This combo is just insane (Claude blows GPT out of the water - maybe off the planet). I’ve never been more productive. And I feel like the UX is still not totally figured out - looking forward to how it evolves.
2 Likes
Thanks for sharing!
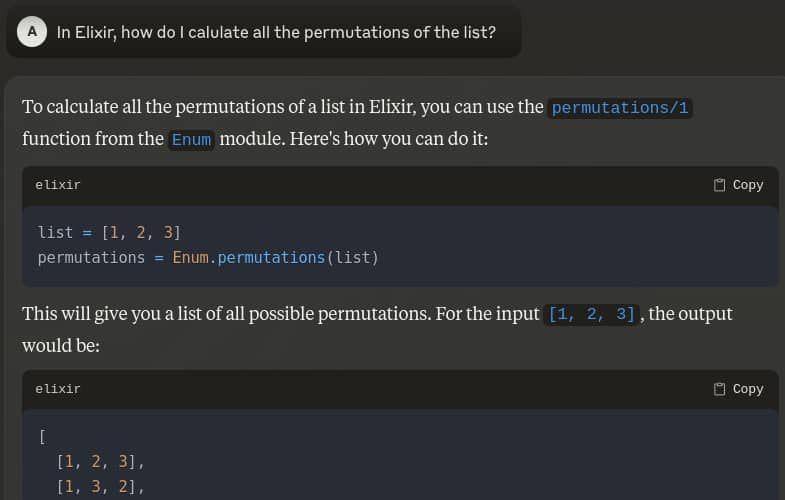
I wanted to try out Claude with Elixir for a while, but other than doing standalone prompts and copy-pasting, I’m not sure how to integrate it into my workflow.
I’ve checked out Aider now, but I don’t understand what a productive workflow looks like. Starting a chat about a file and going back and forth in the terminal?
productive workflow
Here’s one example. Use @preciz recommended configuration to disable auto-commits. Then with Neovim, install an aider plugin GitHub - joshuavial/aider.nvim . Map ‘ga’ to open an Aider console in a vertical split. With that, you can ask Aider to refactor code, add functions, tests, etc. Aider will make changes to the code. If you don’t like the edits, the changes can be reverted.
3 Likes
You could try something like Cody that integrates with your editor.
Great advice, thanks! I’m a Neovim user, so it fits perfectly. Do you also use Github Copilot then? Or just this?
I’m using it with continue.dev as someone upthread suggested, and it seems rather limited by the fact that it doesn’t have the ability to access project files. It can only analyze the snippets I copy-paste into the prompt window. Maybe this is continue.dev’s limitation?
I’m in the middle of a huge refactor, and I need to be able to say “look at the (uncommitted) changes I’ve made in this file, and make the same changes in this other file”. That would save me a huge amount of time and headache, but seems beyond the tools’ capabilities.
Cody doesn’t have those limitations.
1 Like
I have the very same test for all these new “killer AIs,” and all of them show the very same shameful result.
It also shows you how to implement it yourself… It’s common knowledge that these things hallucinate.
I agree with you that LLMs absolutely give no guarantees that they’ll always be correct and that they can be confident in their failures. However, the lesson from an example like this shouldn’t be to conclude that LLMs aren’t useful or helpful in general. They are both useful and helpful more than they’re not… so long as you’re using them correctly and come to them with proper expectations. They are not going to write your application for you or replace the programmer: in fact, I think it takes a more senior developer to really extract the benefit from these tools at this point. I look at LLM given solutions/code much the same way I might approach a Stack Overflow answer to a question I have… often times I find at least enough to set me on the right path… but I also see answers that, through the lens of my experience, I know somehow just “aren’t right” or complete, etc. If I ask the LLM to write code for me, I’m now viewing it very much as a junior developer whose code I need to carefully review. The answers or code don’t always work out or save time, but over repeated iterations, I find that overall I’m clearly more productive.
I also find that these things can be helpful in just explaining the code written by others. What turned my opinion on LLM utility was a task I was asked to do. I was given an MS SQL Server T-SQL routine to convert to PostgreSQL PL/pgSQL which was a long mess of nested loops and conditionals. Another developer on the project asked an LLM to convert the procedure to PostgreSQL and it didn’t work so I got the ask. After my failing to get a correct result a couple of times (missing a conditionally set value a couple of nesting levels away kind of things and not having an example of what actual inputs or outputs were) I turned to the LLM… but I didn’t ask it to create the code, I simply asked it to tell me what the T-SQL routine did in plain English. The LLM got that description spot on, which I could verify, and I was able to produce a correct results (by hand) in a single well structured SQL query at around a third the amount of code. At that point I was sold but also understood the role the LLM should play in the workflow.
Finally, we mustn’t forget that humans can provide wrong answers with strident confidence as well. The original posing of the “Monty Hall Problem” (Monty Hall problem - Wikipedia), and many of subsequent responses to the published solution, demonstrated that, while we may fail in different ways than an LLM, we still can fail with great certitude that we’re right. So I will continue to ask for help from colleagues and delegate tasks to other humans, too… but I’ll also consider the possibility that the answers I get will be wrong or flawed in some way and so will never suspend my judgment or critical evaluations.
5 Likes
For me Github Copilot was too noisy. I’ve tried 3 or 4 other AI plugins, and I like Aider.nvim best so far. People are trying different approaches and it’s good to be able to quickly test new plugins. Yesterday I found a plugin that provides a CMP-completion source.
I find the LLM’s to be most helpful with small tasks: Bash scripts, SQL queries, GenServer skeletons, etc.
2 Likes
Thanks for the suggestion.
1 Like
There is now an /ask command in aider’s newest version.
So for example you can ask about how it would implement something and if you like the changes then in next message you just tell it to apply it.
Tip: Also don’t forget to apply dark mode in terminal, for some reason it defaulted to light mode for me.
1 Like
I tried it and the workflow’s great! What I did is I generated login/register with phx.gen.auth, then tried to add another step to the authentication flow where the user has to either create a new company or join an existing one.
It took a couple of iterations to get it right and it got stuck at some point where I ended up with a broken, half-way done file, but in the end I got a working version.
I was surprised though that ~1.5 hours of coding with Aider + Claude costed me $0.95. Fresh Phoenix install with auth. Is this also your experience?
And the other thing that I keep wondering is: how big of a drawback is it that we use AI with Elixir & Phoenix, instead of JS/TS/Nextjs and the common stack? I love to use Elixir, but from a logical point of view, Claude has so much more training data for JS stuff & the gap will just grow bigger and bigger.
That is only a temporary drawback when it comes to Elixir I believe.
Because the context lengths of models get longer and using them is cheaper by the month, so probably soon you will be able to just send all the docs of the libraries you want to use and the model will figure out the rest. And you might not need to pay for that in every request because they will cache that for you.
Call me stupid, by why we can’t have specialized LLMs for domain specific things, instead of “universal” LLMs that do 10 things and all of them bad?
For example for elixir, I would be more than happy to have a LLM that analyzed documentation of core libraries and most used libraries, because searching hexdocs is horrible sometimes when you don’t look in the right place. I don’t need code advices, don’t need some magical BS, just point me to the right chunk of the documentation with a prompt.
And nobody ever got fired for buying IBM. I would suggest that rationally choosing Elixir already has to be in part to arbitrage some advantage over others that are taking more conventional paths… because if its not you probably should be following “conventional wisdom technologies” and not thinking outside of the box at all. AI will have more to draw on “inside the box”… and will offer a greater degree of consensus wisdom for those stacks as a result. But it will be conventional wisdom right, wrong, or simply mediocre.
I choose the BEAM, not because of tooling, because I though it would offer a superior, more reliable product experience for customers than could be delivered with the conventional stacks people will conservatively choose. Elixir was secondary to the BEAM choice as being the most expressive BEAM language for the problems I want to solve. Tooling and everything else on the periphery I expected not to be as well developed as they are with other, mainstream technologies… and they’re not… but I knew that cost going in and still happy with the choice.
1 Like
Well, that might be true from one side of things, but at the same time show me another language that allows metaprogramming and have libraries as expressive and powerful as ecto, phoenix.
The lack of tooling is a result of having so many possibilities and features, compare dialyzer with a static language like java and this is like talking 2D vs 3D in terms of types.
I can’t speak much to Phoenix (I’m not really a web guy), but Ecto…
This will be reasonably familiar to anyone that’s worked with Ecto… and with good reason as I recall.
Developers on all stacks like expressiveness and powerful libraries and work hard to solve these problem for themselves. I do think Elixir excels in expressiveness because of its functional and expression oriented design… but Elixir’s advantage in this regard is easy to overstate.
Again, I think Elixir is great language and that a more general applicability of the BEAM to actually running applications is seriously underappreciated… which is why I’m still here. But we shouldn’t be shy about where others may yet have advantages.
I know about LINQ, but honestly I think it falls short compared to ecto if you used them side-by-side in real-world applications. LINQ is trying to tailor the language behind an ultimate library, whereas I can do the following in ecto:
defmacro st_transform(wkt, srid) do
quote do: fragment("ST_Transform(?, ?)", unquote(wkt), unquote(srid))
end
Here you go, I’ve extended ecto to my personal needs with 3 lines of code, linq and other libraries trying to do this will be never be able to achieve this by design.
1 Like





















