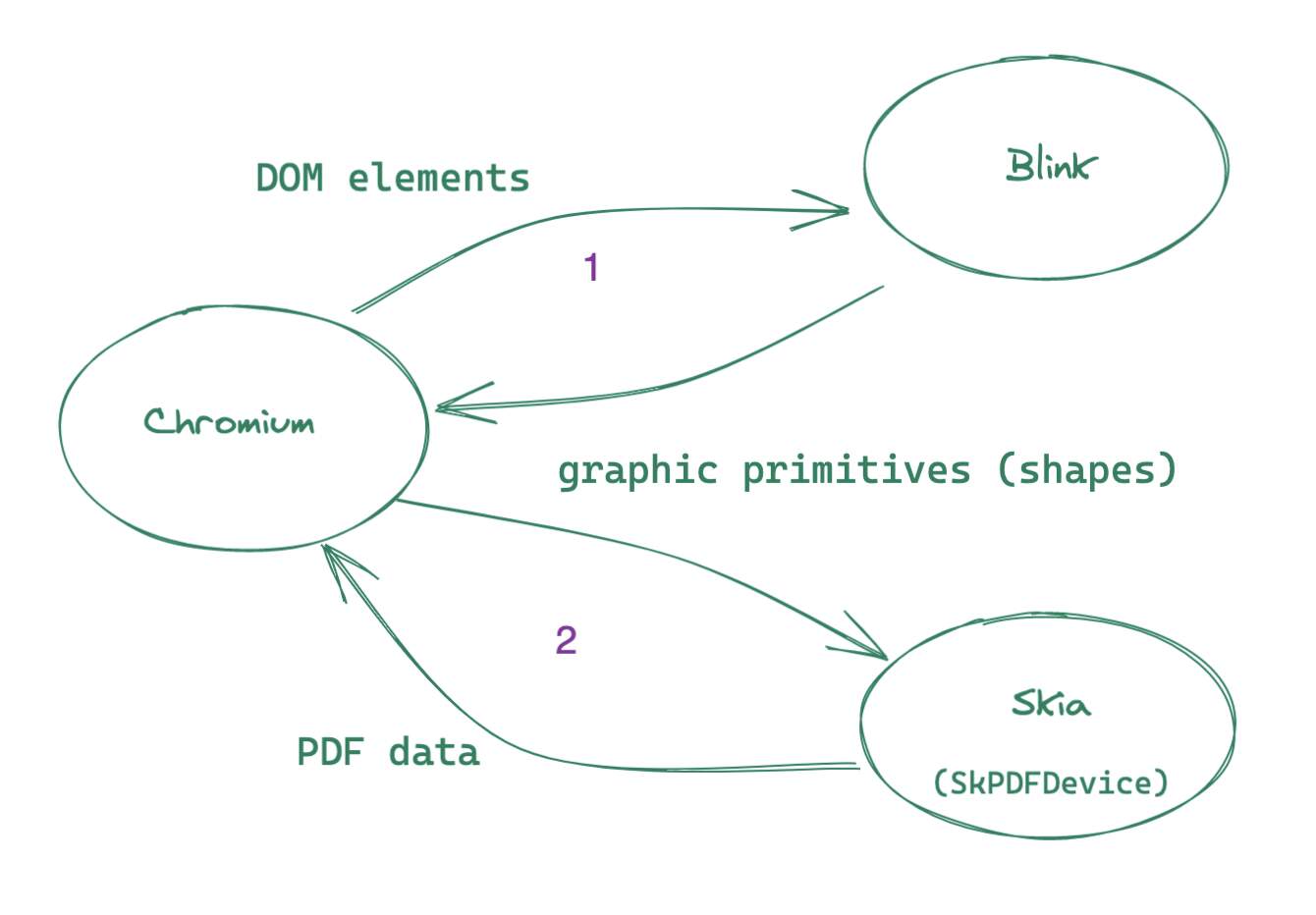
Came here to announce ChromicPDF, a pet project PDF generator I’ve been working on for the past few months. Why another PDF generator, you may be asking? Because it was fun to implement a client for (small parts of) the Chrome DevTools Protocol in Elixir.
That’s basically Chromic’s main feature, it can talk to Chrome without the need for puppeteer / a NodeJS at runtime. It launches Chrome, spawns a number of targets that it keeps around, and to print a PDF instructs them to navigate to a URL. In sum, this makes for relatively performant PDF generation flow.
For good measure, I threw in a PDF/A converter using Ghostscript, capable of creating veraPDF-test-passing PDF/A-3b files - obviously inspired by a project where we needed to generate invoice PDFs for long-term storage.
Would be super interested in any opinion you might have! It’s not (yet) on hex.pm, will wait a bit to see if people are interested. Documentation can be found in the README and, oddly, in the Supervisor module.
cheers,
Malte
Also kudos to my employer for letting us work on pet projects
This looks like an interesting project, kudos on building it!
I’ve got some feedback after reading the project’s README.
When calling the ChromicPDF.print_to_pdfa function you’re providing a map in the print_to_pdf argument, however the specific map keys are in camel case while in Elixir I think it’s more standard/common to use snake case, so for example, you’d use:
print_to_pdf: %{
# Margins are in given inches
margin_top: 0.393701,
margin_left: 0.787402,
margin_right: 0.787402,
margin_bottom: 1.1811,
...
}
instead of the more javascript-like one in the example:
print_to_pdf: %{
# Margins are in given inches
marginTop: 0.393701,
marginLeft: 0.787402,
marginRight: 0.787402,
marginBottom: 1.1811,
...
}
This might just be nitpicking but I thought I should let you know! Congrats once again in building this
Have not read the code nor do I know about the Chrome api, but maybe those options will be passed directly to the API and he just wanted to avoid manually converting from snake case to camel case.
If that is the case, I personally would leave it as it is as it follows the API and people who are familiar with the API would have an easier time working with it. However, if the goal is to completely abstract that, then having them in snake case would be better.
This is quite a tough one… You need something to either render the fonts into a path that you can embed into the PDF, or into something that you can embed as a font into the PDF.
There is for example PrawnPDF in Ruby https://github.com/prawnpdf/prawn and they do it without a browser or other libs. I always wondered why there is nothing like this in Elixir.
@dino@Phillipp is correct, these are passed directly to Chrome and I didn’t want to convert them, or have to maintain a list of them in the library, etc. Perhaps I should convert them to string keys in the README to make this more clear? What do you think?
@egze There is Gutenex which doesn’t have any dependencies and writes PDF. However, PDF is a pretty complex format and writing PDF directly also means you have to come up with a proper text processing API (i.e. something like LaTeX), and in the end teach your users/designers to use it.
IMO this is a call you have to make again with every project that has PDF rendering requirements. Rendering quality is likely to be better with a text processor (not saying Chrome doesn’t render “good enough” PDFs, just that with LaTeX you can do even better); but rendering HTML to PDF gives you the benefit that your designers can easily write templates in their usual environment and new developers can easily make changes without having to learn/adapt to a text processing language. Plus, browser support for print stylesheets and printing webpages in general has become much better in the last years; for example, Chrome automatically renders table headers again on new pages (if your table has proper <thead> tags).
@maltoe I was wondering, how does it work with Chrome with many parallel calls to create a PDF? Is the same Chrome instance reused, or is one started every time? How many parallel calls can it handle?
@egze The same Chrome instance is reused. It has multiple tabs open that are part of a session pool (using poolboy for now), so it can handle multiple calls in parallel. However, there is still only a single connection between Elixir and the Chrome instance, so in theory that could become a bottleneck, although there isn’t much communication happening and I assume most time is spent inside the tab processes when navigating the page / generating the PDF. It’s essentially puppeteer in Elixir :-). Of course, very limited in terms of the functionality it supports from the Chrome API, but conceptionally it works the same.
How many parallel calls: I don’t know, I’ve set the number of workers in the session pool to 5, for no particular reason. Generally speaking, I haven’t done much benchmarking yet, only compared (eye-balled) it against printing a PDF from the command line with Chrome (i.e. spawning an instance every time) and ChromicPDF is definitely magnitudes faster.
@egze If you would want to maximize “PDF throughput”, you could use the {:html, <html blob>} way of passing input, which in turn calls the Page.setDocumentContent function to replace a tab’s contents.
I’ve also been thinking about connecting it to a LiveView to have it only mutate the DOM in places where it needs to (say you’re generating invoice PDFs and you only need to replace the addressee and order items) -> This would probably result in the lowest latency between call and PDF printed, though it’s a bit difficult to synchronize the LiveView-based page mutation and the Page.printToPDF call. Also, this is probably just me looking for intesting problems to solve, not a realistic use-case
Thanks for writing this library, it’s very convenient and simple to install/use! I’ve been playing with it a little bit and tried to print a pdf from a url and it works great!
I’d like to print a pdf from a url which requires that the user is authenticated. One way to do this would be through the cookies in the session. Do you know if I can send cookies to Chrome with ChromicPDF?
I think it should be possible through the Chrome DevTools Protocol.
Setting a cookie is certain possibly with the devtools protocol, and could be implemented into ChromicPDF relatively easily somewhere here.
That being said, I’m trying to discourage users from printing PDFs from remote URLs (hence the default offline mode), for 2 reasons: First, printing from remote URLs seemed to be a bit unreliable in my tests, at least I got rather fluctuating response times (i.e. printing http://example.net a thousand times, sometimes for some reason Chrome would take a second or so to load the page), and second I think users should be well aware of the security implications when doing so.
However, as said, it’s definitely possible. Could you open an issue in the repo so we can discuss there?
Was just wondering, since we need to build it at work soon, is it possible to output pdfs with forms? So something that can be filled out inside the pdf later.
@egze I don’t think that Chrome is capable of saving editable forms in PDF, or at least it won’t do so when printing a HTML form… sorry. Not even sure if there is any HTML-to-PDF renderer that can do this. With my (very) limited understanding of how printing in Chrome works:
At the point when the PDF data is generated, the semantics of input elements are already lost. This is also the reason why PDFs generated with Chrome and probably other browsers tend to be a bit larger in file size as those generated by text processors: They’re basically printing a vector graphic and hence are missing out on a bunch of text-related features PDF has. Interactivity features as well. As said, my knowledge is a bit limited, so I might be wrong ^^
I think you’re out of luck here. You can give wkhtmltopdf (i.e., the Webkit engine) a try, or possibly even pandoc if it’s enough for your needs; but you might find out that the HTML-to-PDF route doesn’t give you editable forms.
Alternatively, it might be possible to post-process the generated PDFs and replace the text boxes with editable fields on PostScript level, but this will be quite costly in terms of
In any case, I’d be super happy to know which solution you chose in the end!
Hi,
somehow I just knew I’d run into this problem before trying out this package. The chrome.exe cannot be found. Running Win10 at work I’m afraid. It’s in the system path and a named env variable ‘chromium’. Not sure what else to do
Also, given the problems around deploying puppeteer-pdf & elixir-pdf-generator to Gigalixir, do you have a recipe for deploying this package to Gigalixir / Heroku? Unless I can get a package working in production it’s not much help.
Otherwise I’m eager to use the package and it seemed to land just at the right time given the challenges the previous two packages were presenting.
[info] Running HSEPlanWeb.Endpoint with cowboy 2.8.0 at 0.0.0.0:4000 (http)
[info] Access HSEPlanWeb.Endpoint at http://localhost:4000
[info] Application sgre_hse_plan exited: HSEPlan.Application.start(:normal, ) returned an error: shutdown: failed to start child: ChromicPDF
** (EXIT) shutdown: failed to start child: ChromicPDF.Browser
** (EXIT) an exception was raised:
** (MatchError) no match of right hand side value: {:error, {%RuntimeError{message: “could not find executable from ["chromium-browser", "chromium", "google-chrome", "/Applications/Google Chrome.app/Contents/MacOS/Google Chrome"]”}, [{ChromicPDF.ChromeImpl, :chrome_executable, 0, [file: ‘lib/chromic_pdf/pdf/chrome_impl.ex’, line: 53]}, {ChromicPDF.ChromeImpl, :chrome_command, 1, [file: ‘lib/chromic_pdf/pdf/chrome_impl.ex’, line: 34]}, {ChromicPDF.ChromeImpl, :spawn, 1, [file: ‘lib/chromic_pdf/pdf/chrome_impl.ex’, line: 9]}, {ChromicPDF.Connection, :init, 1, [file: ‘lib/chromic_pdf/pdf/connection.ex’, line: 25]}, {:gen_server, :init_it, 2, [file: ‘gen_server.erl’, line: 374]}, {:gen_server, :init_it, 6, [file: ‘gen_server.erl’, line: 342]}, {:proc_lib, :init_p_do_apply, 3, [file: ‘proc_lib.erl’, line: 249]}]}}
(chromic_pdf 0.3.1) lib/chromic_pdf/pdf/browser.ex:43: ChromicPDF.Browser.init/1
(stdlib 3.8) gen_server.erl:374: :gen_server.init_it/2
(stdlib 3.8) gen_server.erl:342: :gen_server.init_it/6
(stdlib 3.8) proc_lib.erl:249: :proc_lib.init_p_do_apply/3
You should familiarize yourself with docker and build an image that includes Chrome. Then you can deploy it anywhere where docker deployment is possible.
It can be quite complex in the beginning. Is it something you are already doing for deployments?
Docker isn’t something I’ve ever touched, but I was reading through some of your comments here and was slowly realising that was probably something I needed to do. I was hoping not to have to though: my ‘app’ is trivial - it gets some json from Airtable and builds a pdf because my Airtable users want pdfs!