I am testing a very basic phoenix-based api server and can’t seem to get ecto’s queue time under 1ms for all requests, even though there are plenty of connections available. It’s usually under 1ms but then occasionally spikes to ~40ms which pushes the average latency of the api call from ~5ms to something like 17ms:
mysql database server with > 100 max connections
ecto’s database url is configured with “pool_size=10”
hammering the server (localhost) with “ab -c 5” (concurrency level 5)
I am getting latencies of up to 45ms:
Percentage of the requests served within a certain time (ms)
50% 5
66% 6
75% 7
80% 8
90% 39
95% 44
98% 45
99% 45
100% 45 (longest request)
And here is a sample of a typical log sequence:
QUERY OK source=“users” db=0.5ms queue=0.3ms idle=4.5ms
QUERY OK source=“users” db=0.4ms queue=0.3ms idle=4.9ms
QUERY OK source=“users” db=0.4ms queue=1.1ms idle=4.2ms
QUERY OK source=“users” db=1.8ms queue=0.3ms idle=4.2ms
QUERY OK source=“users” db=0.4ms queue=0.3ms idle=4.5ms
QUERY OK source=“users” db=0.3ms queue=0.4ms idle=4.1ms
QUERY OK source=“users” db=0.6ms queue=0.5ms idle=4.5ms
QUERY OK source=“users” db=0.4ms queue=0.4ms idle=6.0ms
QUERY OK source=“users” db=0.4ms queue=0.4ms idle=6.1ms
QUERY OK source=“users” db=0.3ms queue=0.3ms idle=4.0ms
QUERY OK source=“users” db=0.7ms queue=0.3ms idle=4.2ms
QUERY OK source=“users” db=0.4ms queue=0.4ms idle=6.4ms
QUERY OK source=“users” db=0.4ms queue=0.3ms idle=5.8ms
QUERY OK source=“users” db=0.3ms queue=35.1ms idle=5.1ms
QUERY OK source=“users” db=0.3ms queue=38.5ms idle=4.0ms
QUERY OK source=“users” db=0.3ms queue=36.8ms idle=7.1ms
QUERY OK source=“users” db=0.3ms queue=2.4ms idle=39.6ms
QUERY OK source=“users” db=0.3ms queue=2.3ms idle=39.6ms
QUERY OK source=“users” db=0.3ms queue=36.8ms idle=5.4ms
QUERY OK source=“users” db=0.5ms queue=39.1ms idle=5.0ms
QUERY OK source=“users” db=0.3ms queue=0.2ms idle=5.4ms
Why am I getting those ~30-40ms queue times and what can I do, if anything, to keep it under 1ms in 100% of cases when there is no shortage of db connections?
Tangentially I’d consider using wrk not ab, there have been issues in the past with how ab negotiates connections.
With any benchmark question, please validate that you’re running in a production build, development builds have things like code loading on that can introduce delays. Also, you’ll want to supply the exact versions of the various libraries that you’re using, and of elixir itself.
Yes, db server, phoenix and ab/wrk are on the same machine, it’s a 12-core Intel i-7 / 32GB RAM laptop running ubuntu linux. I am running the same test on k8s/google cloud - where the 3 tiers are on different pods and I am hitting the same issue with queue times.
tl;dr we are CPU bound somewhere but we don’t know where.
These first numbers look good. Idle time shows we have some space capacity in the connection pool but not much. Given these numbers we are using a connection every ~4.5ms. Idle time is calculated by looking at the difference in the following timings: time a checkin message is sent to the connection pool and time a checkout message is sent to the connection pool. Note that these are measured outside the connection pool process, in the client process (e.g. phoenix request handling process), so are be independent of connection pool overhead. The idle time is calculated by checkout request message sent time - checkin sent time. If the checkout is sent before the checkin, when the connection pool is IO bound/out of connections, then the idle time would be negative by that previous calculation but it is set to 0 because the connection was never idle. Therefore this timing can reflect if we the connection pool is IO bound, i.e. if above zero we are not IO bound, if zero we are IO bound.
We can see the idle time is never 0 in the sample. Assuming this doesn’t occur elsewhere then the connection pool always has spare connections. I believe this is expected given the 5 concurrency clients and 10 connection pool size.
Now to where we see some less ideal numbers in queue time:
Queue time is calculated by measuring the time between when the connection checkout message is sent and the time the client process receives the connection from the connection pool. Both time points are recorded in the request handling process. Therefore we see the full connection pool overhead as the schedulers must schedule the connection pool, and the connection pool must handle the message (and any other previous messages), and then schedulers schedule the request process. This means queue time includes both IO and CPU overhead. If we continue with the previous assumption that idle time is always strictly positive then we are never IO bound. Therefore this queue time is showing us being CPU bound, and given the concurrency level (5) and cores (12) this could be a scheduling issue if we are having to wait nearly 40ms.
Note that there are multiple schedulers, in the cloud there is usually hypervisor, kernel and BEAM VM. You suggested you’re running in GKE sometimes, so likely you’ve got a CPU resource quota too. On your laptop there are probably fewer CPU limitations but your kernel is going to be scheduling whatever applications are running as well.
Assuming the sample is 100% of queries during a time interval, it naively looks like this issue could be scheduling outside the BEAM VM because we have 3 requests with a queue time of ~38ms followed immediately by 2 requests with a similar idle time. Given that we have 5 clients and we we measure these timings, it suggests that 3 clients were “blocked” while awaiting a connection from pool shown by queue time, and 2 clients were “blocked” before they could request a connection shown by the idle time once they made the request. For the later 2 its not clear where the clients were blocked, it may be in phoenix or the load tester.
Given the next two requests go back to high queue time, and the third is back to normal this analysis might be poor because we don’t know how many queries each HTTP request makes and when in time these queries occurred - thought never being IO bound (idle time > 0) suggests that its 1-2 on average. For example most of these queries could be running concurrently, and the BEAM scheduler could interweave the handling because it can scheduler processes in and out at any time - e.g. its possible that we see 5 requests with queue time 38ms but by the time we log at the end of a query we already have the first 2 clients recording their second request. Also the load tester has concurrency 5 (< 10 connection pool size), so if one request in BEAM is slow, then the next request that load tester thread sends is delayed by that slow request, so the idle time is expected to be higher for the next request it sends. The load tester may also adjust its recording for this situation and add a latency “penalty” to that second request as it was scheduled to begin late. Queuing theory is tricky. You could dig deeper into this situation by recording the timestamp of the log event and the load tester client thread id. For many load testers the BEAM’s socket connection info (e.g. cowboy connection pid - each socket has 1 socket connection in cowboy, and then an extra 1 pid per request, with http keepalive there is a new pid per request but the connection pid is reused by a client) could be a reasonable proxy for client thread id.
If the sample isn’t 100% of queries during an interval then the already weak analysis is very discredited. It may be processes in the BEAM that are running slow because if we are CPU bound somewhere away from the connection pool then we will leave connections idle for longer.
Given you mentioned a laptop I would definitely assume that 12 schedulers (core count / elixir -v shows 12 BEAM schedulers) is too many and wont combine well with other processes running. You could try reducing the BEAM schedulers to help your kernel schedule all the things its needs to with: Erlang -- erl. Maybe try setting 5-8 schedulers, especially if there is no concurrency in phoenix request handling. Linux should be doing a great job though and it might just be that any laptop is not a good environment to get good latency at p90 and above. I have found that the further away from a production like environment the harder it is to create a meaningful benchmark unless you have already identified the slow parts of the critical path and are just testing those.
I don’t know GKE but you could have similar issues there but likely less problematic if you have a pod for client load tester, elixir and the db. I assume this is also like your production environment, so I would move here instead of the laptop, add the additional logging from above and ensure you have suitable scheduler count/cpu quota before continuing. I don’t know what visibility GKE gives but you may even need to adjust the concurrency/quote for the load tester, e.g. if you set 5 CPUs and 5 concurrency maybe try 6 CPUs and 5 concurrency. This is a load test so don’t want to context switch away to other processes too often.
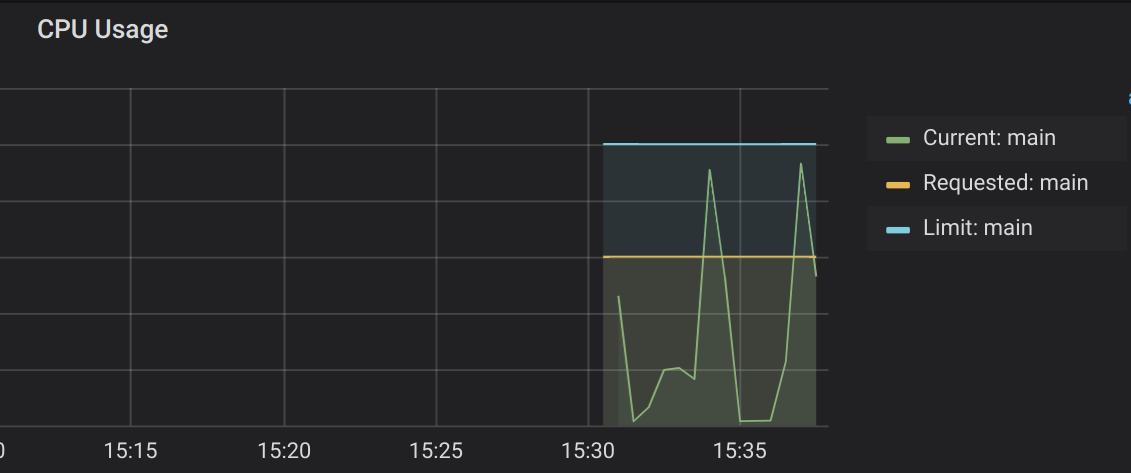
Wow. Thank you so much for this very detailed analysis. I redid the tests today on the GKE environment, following your suggestions, and was able to pinpoint the culprit - the server running the phoenix app was indeed getting cpu-bound, which only became obvious when I upped number of tests from 100 to 10,000.
I think what threw me off initially was that only some of the requests were getting high queue time, whereas I would have expected higher latency for all requests in a CPU-bound app.