If I am not wrong, You can use dirty schedulers…
https://bgmarx.com/2018/08/15/using-dirty-schedulers-with-rustler/
If I am not wrong, You can use dirty schedulers…
https://bgmarx.com/2018/08/15/using-dirty-schedulers-with-rustler/
Dirty schedulers is fine, or just send the work to another thread in rust and have elixir poll for the result or for it to send a message back instead of a function call.
Also, it doesn’t need to be a NIF, it’s operating over files after all, so a Port to a persistent process that does the work or even just a standalone application run via System.cmd on-demand or so would be fine.
Hello and thank you to everybody for extensive review and feedback. I see many suggestions. Let please digest your feedback and incorporate already given improvements (IO lists, tuples, etc) and I’ll be back shortly with results.
Also answering some questions.
@jola I think it’s worth talking about expectations here, do you expect the code to run as fast as Java?
I do not expect Elixir in single ‘flow’ execution to over-perform Java, I only would like to get all possible improvements to make it as close as possible to lets say “base line”. The result what I have is already big win because it is just one flow of file processing but I need to process 400 files with overall latency 15-20 minutes, so as a next steps I need to scaleUp and most likely scaleOut this solution. And that is where Java fades away, especially on scaling out and orchestration of “workers”. That’s why I intentionally pursue Elixir. There will be more functionality I need to implement after aggregation as well.
@ dimitarvp Do you know in advance how much maximum unique values will this combo have?
The hourly input to this job in ~0.5 billion records in ~400 files. Because I remove few fields from the key hence getting more coarse-grained key, there is room for aggregation and reduction ratio is ~3.5-4 so as result from the 0.5 billion records we should have 120-150 millions
Also just overall comment about input file structure. It is fixed and unlikely to be changes any time in future. It just has header what I need to skip and the line separated records in CSV format. The key spec is fixed so I need just to pick up subset of keys out of the key set for aggregation.
Thank you.
Yes, needs to return in 1ms is good advice. But to be clear, it’s only scheduler on one core that’s locked–it’s not like it blocks all other processes from working, unless/until you hold onto the core so long that scheduling falls over and can’t get up.
So you can use a port instead. Or at the 1 ms mark return intermediate state, then wrap the nif into an Elixir module that takes care of calling, holding the state, passing into the next call, repeat until done.
Stream.into(File.stream!(output_path, [:write, :utf8]))
This line likely isn’t helping - by default, it’s going to do a syscall to write the data for each element in the stream. The Java implementation uses BufferedWriter, which defaults to an 8kB buffer.
The delayed_write mode could help here:
Stream.into(File.stream!(output_path, [:write, :utf8, {:delayed_write, 8129, 1000}]))
(you can spell it just :delayed_write, but this version explicitly sets the buffer size to match the Java version)
See also the Erlang documentation for :file.open/2
Thank you valuable feedback - will incorporate it as well.
Update:
It was actually pretty fast fix getting ~50% of boost. The latency decreased from 115 sec to 80 sec using buffered writer! Thanks.
The next step IO list instead of strings for the key and Elixir solution will be near perfect
That should probably be Stream.each, would reduce memory use a bit.
If you’re switching to iolists then this last part doesn’t make sense to stream any more
|> Stream.map(fn {key, value} -> key <> "," <> Decimal.to_string(value) <> "\n" end)
|> Stream.into(File.stream!(output_path, [:write, :utf8]))
|> Stream.run()
I would change it to something like
data = table
|> :ets.tab2list()
|> Enum.map(fn {key, value} -> [key, ",", Decimal.to_string(value), "\n"] end)
File.write!(output_path, data, [:utf8]))
Because you no longer create intermediate values that can be cleaned up, and there’s no repeated iterations, there’s no longer a value to Stream here, just overhead.
Nice job with the speedups! If you want to keep digging I’d expect the initial File.stream is a bottleneck, because it’s a lot slower to create a stream of lines than eg reading the whole binary and splitting it (but it uses a lot more memory).
Thanks @OvermindDL1, @kokolegorille, @sribe for the advices!  and sorry guys I’ve moved the thread to something slightly different.
and sorry guys I’ve moved the thread to something slightly different.
About memory, for example Elixir Stream gets the lines from the file and these strings are passed to this NIF, do you know how these strings are passed? Is this memory shared in some way with the NIF code or is it copied?
I’m trying to understand how much a function call to a NIF can be fast…
I’m sorry, I’m a huge Elixir fan but its hard to let this one go by. Java is really good at distributed batch processing. Like, really good at it. Elixir has advantages in real-time and concurrent systems, but for distributed batch processing I’m skeptical you will beat the performance OR the management capability of the Hadoop ecosystem and specifically Spark or MapReduce. And you don’t have to manage that yourself you can spin up an EMR cluster on AWS. A lot of this stuff gets oversold for fake “bigdata” projects but a quadrillion rows a month…thats a big ask for Elixir IMO.
Let me tend to disagree please.
We do heavily use all spectrum of AWS services including EMR and the result what I am going to process is actually an EMR output. But not all distributed computation is required heavy artillery, infrastructure and external services. Many required task can be done in much more elegant and concise way.
I did some of them in Java and rejected EMR solution when designed, and they still are running in Prod for 2-3 years with almost no operation. But all my Java solutions are based on scale up principle so far. It works good (as long as next gen of EC2 instances come) but what if i need a cluster of 2 or 3 nodes only? Just distribute set of tasks to the tiny fleet, then in Java it becomes not a trivial task at all. How to orchestrate this work how to retry failed tasks, how lock tasks, how to partition and shard task to particular node? All this requires bring extra services like DDB (for task locking, deduping and orchestration), Kinesis for sharding and locality and SQS as a message bus. I am looking at Actor model in Elixir and Erlang’s OTP which potentially gives all this options out of box and built into language.
For Java I think I can only compare Akka to Elixir to achieve similar capabilities for horizontal scaling.
Do I have wrong expectation?
Thanks.
If you want to build a system to do all this yourself, Elixir is a great system to build that orchestration layer with. I think Hadoop provides a lot of that orchestration for you in the context of batch processing, but maybe I do not understand your use case. Hadoop distributes tasks to where the data is and/or where compute resources are available. There are retry parameters, scheduling constraints, you name it. You need more processing power, you just bring more nodes up. I can understand not wanting to deal with the accidental complexity that system brings, and maybe your system doesn’t need it, but I think the statement “Java can’t scale batch processes” is indefensible. That is all I’m pointing out.
Don’t forget that the BEAM is a fantastic glue. It can orchestrate nodes running native code (like rust or C++ or python or whatever) with ease, handling failures, restarting, etc…
If you need something really speedy use an FPGA
We use Microsoft Orleans a .NET C# distributed virtual actor framework at work. Maybe that’s something you want to checkout if it’s distributed model is something you can work with. C# performance is at least same as Java, maybe faster, plus C# has good async implementation built in using async and await keywords. You can also use F# functional language instead of C# if you use it through Orleankka.
I’ve read or maybe watched a video that Microsoft has used it to distribute IO and CPU bound work.
I’m curious which part is actually slow.
Based on my experience optimizing a similar code snippet (spent lots of hours on it, measuring each part).
Another thing, causing lots of GC by constantly growing the heap. With a similar use case script I was able to speed it up considerably by setting the initial process heap size to a very large number, which avoids growing the heap a bunch of times. GC in general is costly, if you can avoid it, do. But that’s up to your memory limits.
ps come to my talk at CodeElixir LDN or ElixirConf US where I will be talking about this thing exactly
In case it wasn’t mentioned (I just took a passing glance at this thread), replacing Enum/Stream functions with plain recursion can sometime improve performance significantly (at the expense of having a more complicated code). Not sure if it would help here, because you seem to be doing a lot in each step, but you can give it a try.
In general , I wouldn’t be surprised if in some scenarios a sequential Java program is about 10x faster than Elixir. BEAM languages are definitely not famous for their speed  That said, IME, in many cases it is possible to get close enough to the speed of faster languages with a combination of proper algorithms and BEAM specific technical tricks.
That said, IME, in many cases it is possible to get close enough to the speed of faster languages with a combination of proper algorithms and BEAM specific technical tricks.
Good evening everybody, sorry for delayed update, I had extra hectic working week so put my POC on hold, but today I finally competed first part and got more or less working version.
In short results are just tremendous - I did not expect such a great outcome. And outcome is as following:
In Elixir app:
the average latency is ~17-18 minutes for the whole work, which is almost 2 times better than I did with Java prototype 1 year ago!!!
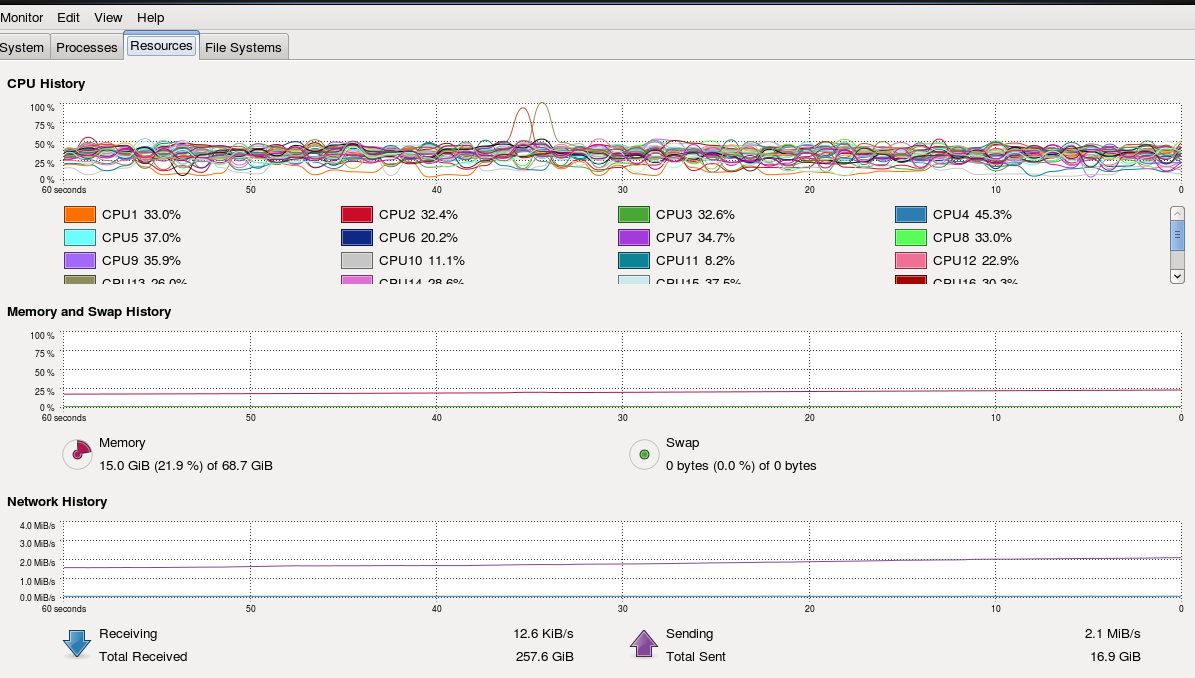
The CPU usage is ~50%, the memory usage ~50% which is slightly higher than in Java but totally acceptable (please see screenshot bellow).
I performed 3 test runs for different hours. The test platform is my cloud devbox C5.9XL (36 cores, 25Gb net, 72Gb RAM)
This is first functional step in the POC (and I still need to work a lot) but first results exceed all my expectation!
Thanks to everybody who helped to reach me such results.





















© Copyright Elixir Forum | Terms | Privacy & Cookies