Wow, this topic is full of good insights. I have some good links and food for though to create some LinkedIn posts (not any-more active on Twitter) :).
For anyone wanting to watch the part 1 and part 2 videos while taking linked notes and creating bookmarks I invite you to watch them at:
For example:
Elixir vs Go performance: The pros, the cons, the trade-offs
Elixir vs Go: When resilience and fault-tolerance is more important then pure performance
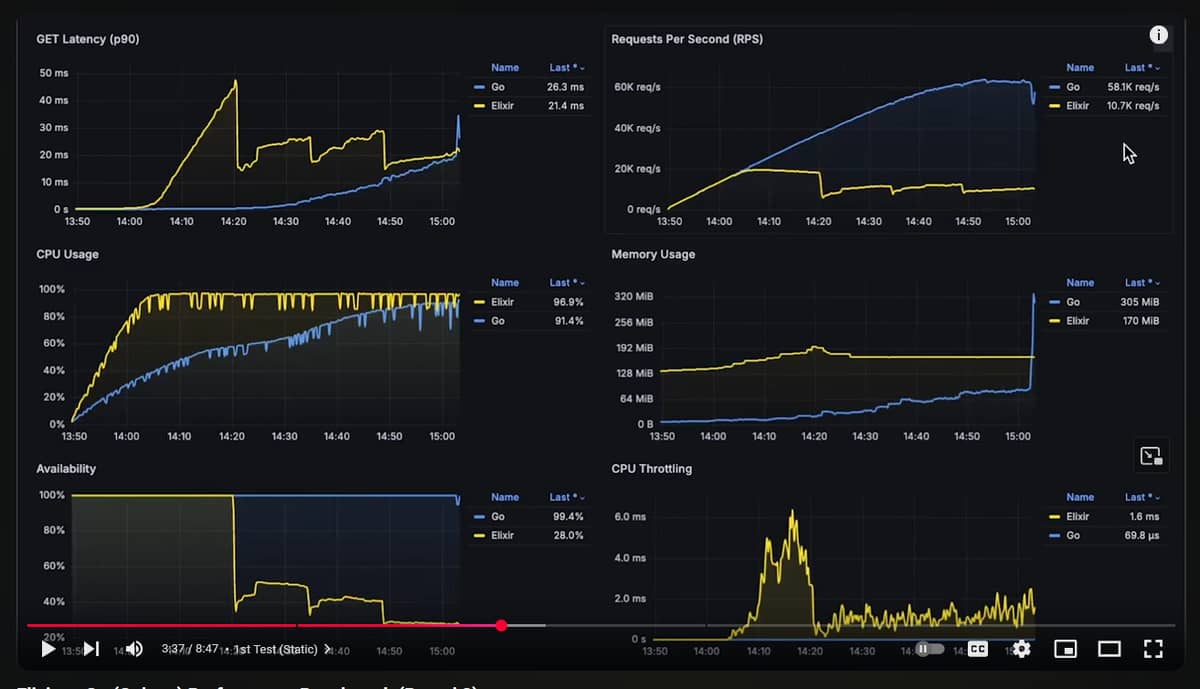
I was surprised with this failure rate too, because I was with the impression that the strongest point of the BEAM was availability under extreme loads, with expected performance degradation off-course.
It would be interesting to ran the benchmark until one of the langs crash and stops to be available entirely. Off-course Kubernetes will restart it, but I would like to know the breaking point of each. I suspect that the BEAM wouldn’t crash, therefore not requiring K8s to restart it, but I would expect Go to crash at some point.
Does the memory spikes of Go in the benchmark mean that it crashed and required a Kubernetes restart?
From what I could tell in the video, what this appears to be demonstrating is that Kubernetes is throttling Elixir. I would prefer to see something like this run on an actual server. Otherwise, what this looks like to me, is that Kubernetes is misconfigured. The drop in performance on the Elixir side strongly correlates with Kube throttling. I could be wrong here, but I regularly see Elixir services happily chugging along at 100% CPU for quite some time with no issue or degradation in performance.
I think the overall impression points to a glanced-over configuration that favors fine-tuning for golang and not for other ecosystems reviewed, that is my personal impression from the specific video and other videos posted by that youtuber.
I don’t use Kube, so I’m sorta extrapolating a bit (and I read some PRs into the creator’s repo), but if you watch the video you can see how CPU throttling on Elixir spikes after it hits 100% CPU
f that is indeed the case, which makes sense to me, then some kubernetes expert needs to open a PR in the repo with the fix and the author needs to create part 3 of this benchmark
A custom simple thrown together client is being used - most likely doing CO(Coordinated Omission) - eg. results are incorrect/misleading
One system is mostly tested in overload >100% cpu (due to 1&2 nothing is really measured before overload occurs eg. latency 0?! ), the test is quickly stopped once the Go test reaches overload.
The tests are out of sync, one test gets ahead of the other, for a given time.