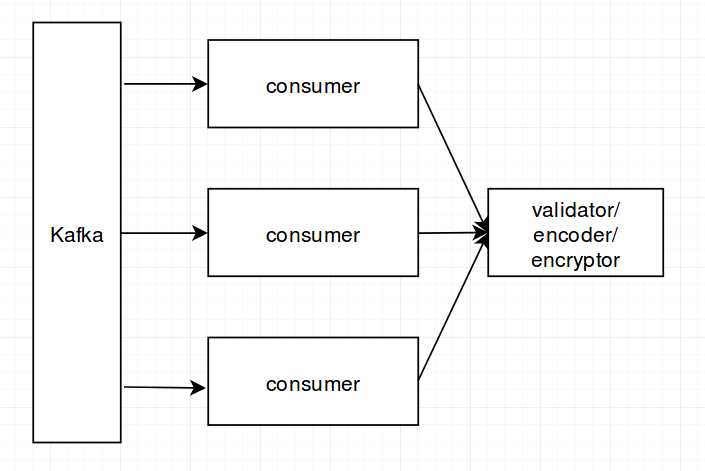
All GenServers I use are pretty simple. Validator, as an example, takes a schema definition (loaded from a file) as an argument to start_link, processes it and keeps as a state. The validate function uses that schema to do the actual validating. The same is true for the Encryptor. Basically a state doesn’t change after init for all of my GenServers. So if I use a pool all GenServers will share the same state.
If instead I initialize the consumers with schemes, keys, etc. and pass this data as an argument to the functions holding the logic that will solve the problem indeed but it requires the consumers to ‘know’ about things that are not their responsibility, for example, that a schema should be processed after it is loaded. Feels like a problematic architecture. Creating a pool for every little module that has to keep a state seems ridiculous too.
While studying how this is usually done I found a couple of Erlang examples where a global ETS was used to store a state at init and then in a function that needs the state the ETS was accessed by name. Actually I used this approach to solve an (anticipated) bottleneck problem when writing a Validator (for lack of a better solution that was simple enough). But then a number of modules with a similar problem emerged and I wasn’t fond of an idea of using what looks like a global variable solution all over the place  .
.
@ryh
maybe then instead of this
def validate(schema_id, data) do
GenServer.call(__MODULE__, {:validate, schema_id, data})
end
I should do something like this
def validate(schema, data) do
schema = GenServer.call(__MODULE__, {:get_schema, schema_id})
validate_data(schema, data)
end
This way the actual processing is happening in the caller process. But as far as I can understand a schema definition would have to be copied from a GenServer process to the caller process, and it is much larger than the actual data being validated. Maybe the same thing happens when using a global ETS table though.
Maybe I’m doing it all wrong. I really hoped there was a widely used solution to this problem 
")