Currently i am developing phoenix application,lets say i have 3 queries to store in database. On success of each query i have to push the id of inserted query with some additional info in memory, later i need to pop the id to do some tasks by cron job, how can i achieve this behaviour??
I do not really understand what you want to achieve. And it will not be clear for others either. Can you elaborate?
You might have a look at agent, which could store id for succesful stored query (Or better, GenServer)
https://hexdocs.pm/elixir/Agent.html
The OTP world has all the tools You need to do it.
You don’t really need cron with elixir.
1 Like
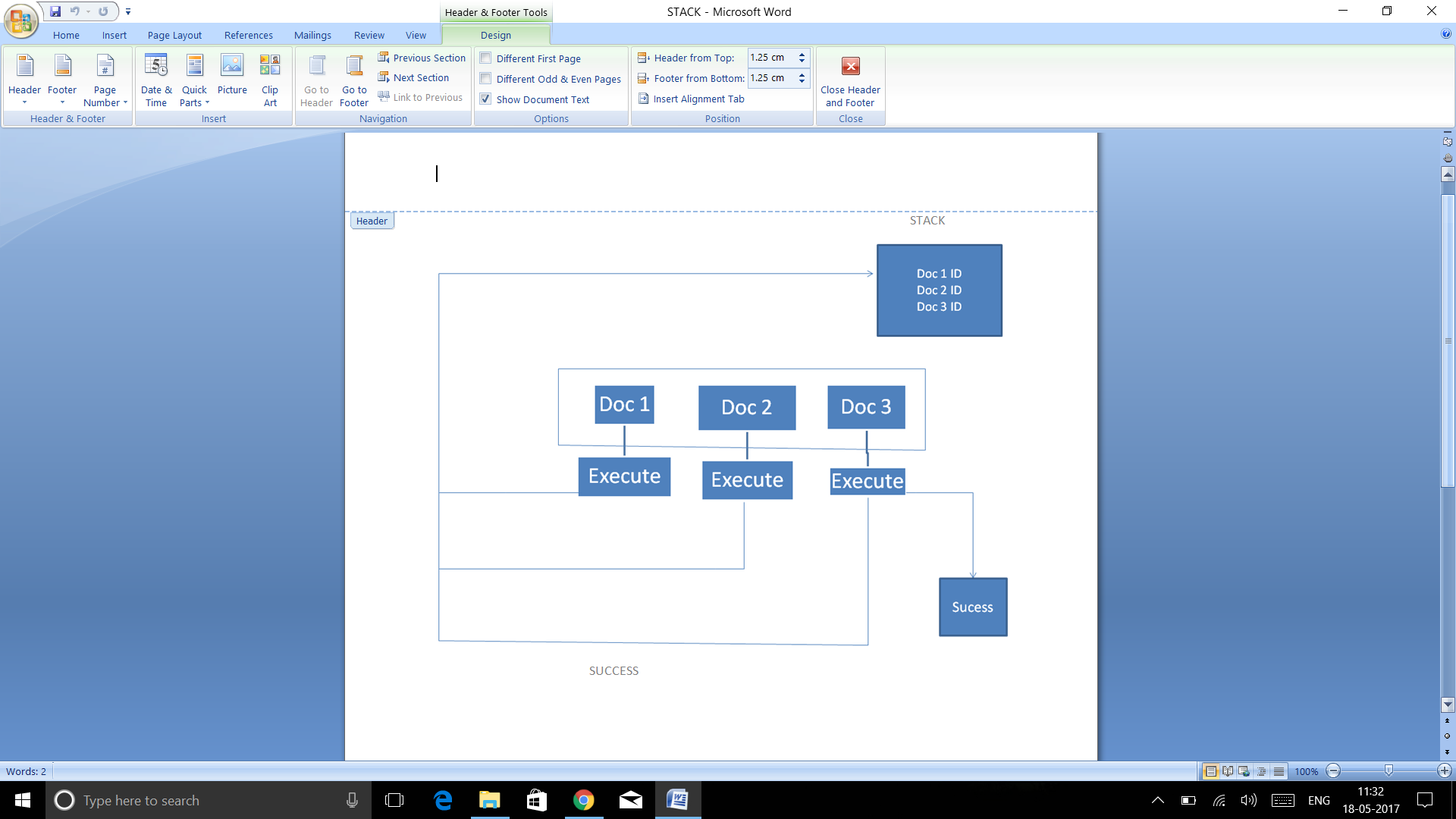
from the following chart, i have transaction document like
{ doc1: { key: value }, doc2: {key: value}, doc3: {key:value} }
whenever i insert doc1, doc2, doc3, on each successful insert(execute) i want to store the id of executed document in stack(memory)
the reason why i am storing is, For example if doc1 and doc2 is executed successfully and doc3 fails then i have to popup the id from stack for doc1 and doc2 and delete from database
You can wrap this in a transaction, if one fails, all are failing
from the following link ecto3 not support mongo_db so i directly use mongodb_driver , Is it possible to use Ecto Multi?
Whatever reason You have to get stuck with mongodb, I find it overkill to use elixir for checking db transaction. I see what You want to do, but You should think if there is a better solution, in the first place.
thanks, i will find better solution mean time if i use this technique what kind of storage should i use Agent or ETS ??
Ignoring the choice of storage technology (mongodb is really not a great choice imho), it is an interesting question that you pose, which can I think be boiled down to this:
Given a series of tasks,
track each task and,
on success attempt the next task
but on failure perform routine on each previously successful task
Looks not so hard! ![]()
Here’s a simple way to accomplish this:
defmodule Rollback do
def insert(id) when rem(id, 2) == 0 do
IO.puts "Failing #{id}"
:error
end
def insert(id) do
IO.puts "Inserting #{id}"
:ok
end
def insert(id, {_prev_status, ids}) do
case insert(id) do
:ok -> {:cont, {:ok, [id|ids]}}
_ -> {:halt, {:error, ids}}
end
end
def rollback(id) do
IO.puts "Rolling back #{id}"
end
def sync_tasks(ids) when is_list(ids) do
case Enum.reduce_while(ids, {:ok, []} , &__MODULE__.insert/2) do
{:ok, _ids} -> :ok
{_, ids} -> Enum.each(ids, &__MODULE__.rollback/1)
end
end
end
… and from the repl:
iex(13)> Rollback.sync_tasks([1, 2, 3])
Inserting 1
Failing 2
Rolling back 1
:ok
Cool!
Buuuut … what if the set of documents to insert arive async over time, so you can’t just pass a list of ids to insert at the start? Well, use a GenServer, and store the list of currently successful ids in its state. Every time a document needs to be inserted, send a message to that GenServer with that id, and it will do the insert and on success store that id in its state. When complete, tell it to exit. If a failure is experienced, that inserting GenServer can then rollback on all the ids in that list of successful inserts in the state. That is not a big change to the above module at all. Cool.
Buuuut … what if something goes wrong and that GenServer experiences an unrecoverable error and crashes? Then that state will be lost, and nothing will rollback! Fear not: create a second GenServer which the first one sends a message to on each success. That second GenServer will do nothing but hold on to the list of successful insertions as its state.
The first GenServer doing the inserts will start the second (rollback) one, which will trap_exit and link to the inserter process. That way, should the inserter die a horrible death, the rollback process can catch that and do its rollbacks. For added safety, it should do the rollbacks in a separate process(es), probably using Task as a convenience.
So, depending on whether you have your list of document up-front, or if you need to feed them in async, and/or if you want EXTRA reliability in case of failure, Elixir has you covered.
HOWEVER… this still is only sort-of-good-enough. What happens if you lose connectivity to the database? Well, the rollbacks will also fail, of course. Fail. (And that is just one possible source of such failure!) Now your database contains orphaned, or worse inconsistent!, data.
This is one reason why application-side transactions are just not good enough. They belong in the storage engine as that is the only place they can really be guaranteed. Everything else is only “best we can do given a poor storage solution”. So if you must use mongo, the above is perhaps better than nothing. But you should really perhaps consider switching to a proper storage solution. There are many of them out there. Honestly, postgresql is more than enough for 99% of use cases out there and it does these things Properly. Most of the time when someone thinks they need something “webscale” they really don’t, and instead spend a bunch of time addressing problems like the one you have here. ![]()
Happy elixir’ing!
4 Likes
thanks for the detailed information
Thanks man, According to your information what i understood is ‘Insert should be done in one GenServer and the successfully inserted id’s should save in another GenServer’ right?? and I would like to know What are the possible connection failures in MongoDB?
That’s the most robust approach of the ones I covered, yes. Best of all: it prevents the need to do anything complex with e.g. ets. Processes are just so lovely for these kinds of things. But I would only take that approach if you require the (small amount of) complexity it adds to your code. Simple as possible, right? ![]()
Network splits if it is run in a different system context (hardware, VM, container, etc.); if the db itself crashes; if the OS it is running on stops and the db doesn’t finish cleanly (e.g. due to the OS being non-gracefully stopped, as can happen in the case of kernel crash or power failure); if the db gets overloaded and stops responding, or responds too slowly, to new requests.
There are any number of failure causes. The first rule of distributed systems, and having your storage outside your application is already a distributed system, is to expect that at some point in the future the system will experience partitioning. It can happen, it will happen.
It might not matter in the case of your application, perhaps a 100% clean and consistent minimal data set is not a requirement. Perhaps having an extra stale record here or there in the db just means it is using a tiny bit more disk and that’s the entirety of the effect. And then you probably don’t care. (Too much, anyways ![]() )
)
But often I see applications written without much care paid to these things that too easily can (and eventually do, often) end up in an inconsistent state or with data lost.
But this is a per-application / use-case judgement call to be made.
Or you can default to using a storage engine that handles much of this for you and worry less. Even then, there are issues like “what if I am saving records/documents to the storage backend, and it fails partially through, do I need to retry later or adjust the data being saved and then retry to prevent data loss due to failure to put the data into a durable store?” No storage system can save every app from every possibility, but they can at least help more than they hinder.
Transactions in the db are one way that durable storage can absolutely help out in very non-trivial ways.
3 Likes






















