I’ve been running some tests comparing the results more thoroughly this week and will probably post an update tomorrow. I can confirm that EXLA performs better than Python when using the full sequence length. I also started playing with CUDA on AWS, but there I still need to run some more tests.
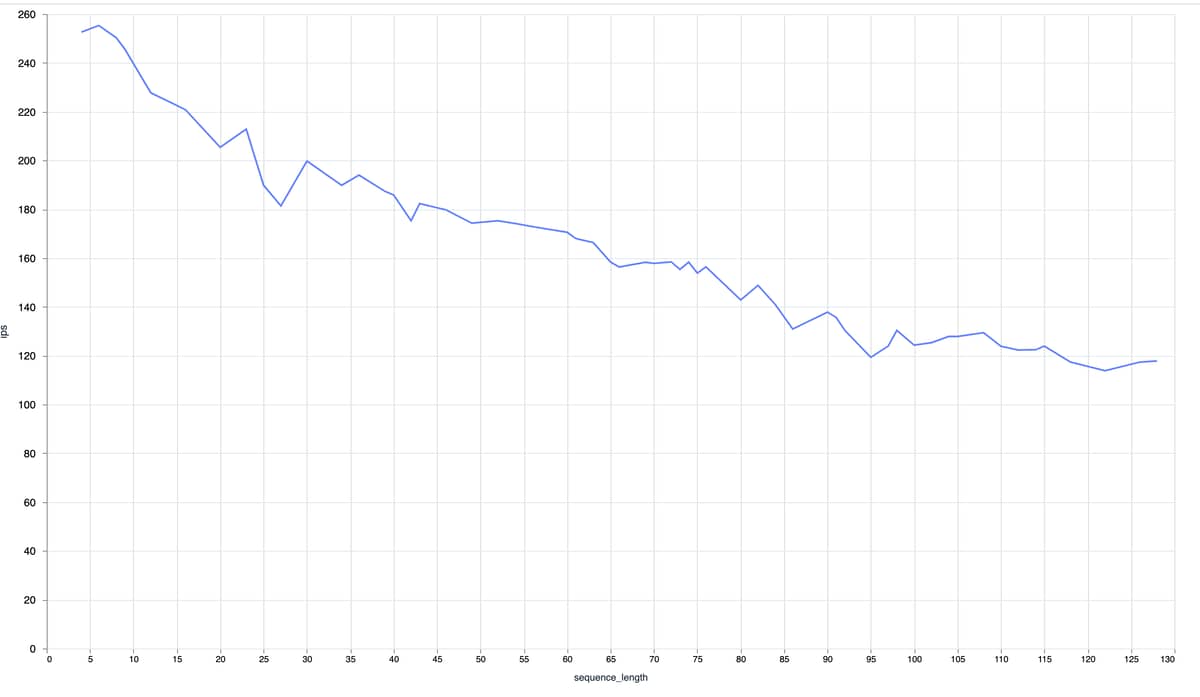
To measure the impact of the sequence length, I adapted my serving to always tokenize twice. One time with the full sequence length and then again limited to the actual sequence length of the input. The encode/second graph looks like this for EXLA (x-axis sequence length, y-axis encodes/sec):

This is the graph for Python (not quite fair as it goes through an extra HTTP request):
And finally I’m attaching the Livebook I used to generate these graphs.
All in all, Elixir and EXLA perform well. The only thing remaining is that I could not get the CPU to be fully loaded with EXLA (the same for CUDA).
The first one seems similar to what Python does, always using the longest input sequence length, if I understood that right.
I’ve been thinking about the following: couldn’t we also allow a dynamic sequence length and just in time compile when we first get an input with a specific sequence length? Further requests should then be compiled. As the sequence length is finite, this would mean that one could either pre-compile every sequence length or “warmup” the serving.



















