Thank you for the suggestion!
I think Nx.global_default_backend(EXLA.Backend) might already do this? At least I don’t measure any real difference when setting this on my serving. In general I think that the serving is not the limiting factor. I added a script that does not use the Nx.Serving at all, basically just calling Axon.predict and the performance is very similar (nx_axon.exs).
I also tried with different batch sizes and batch timeouts, but again without any measurable differences.
Concerning sequence lengths: that shouldn’t be an issue here as the benchmark is always encoding the same sentence, but good to know!
The main question I have is if there is some bottleneck with EXLA and the dirty NIF schedulers maybe?
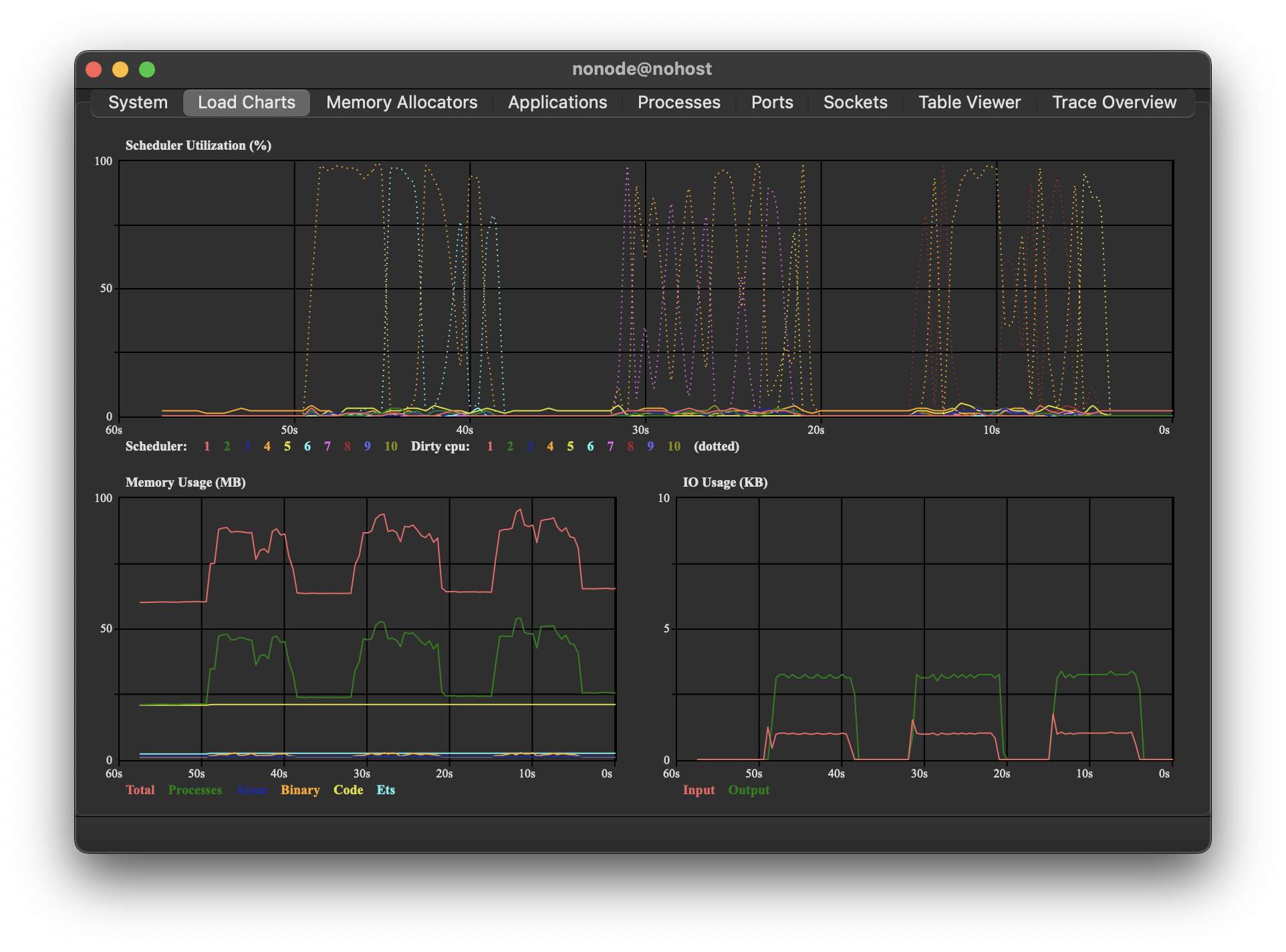
Here you can see the scheduler usage while running the benchmark 3 times for 10 seconds. Looks like only one dirty cpu scheduler is used at a time, although which one changes. I’m no export on NIFs at all, so maybe that’s some common knowledge, but if Nx can only use one dirty scheduler at a time, this might become a bottleneck in other cases as well? Only speculations on my side though.



















