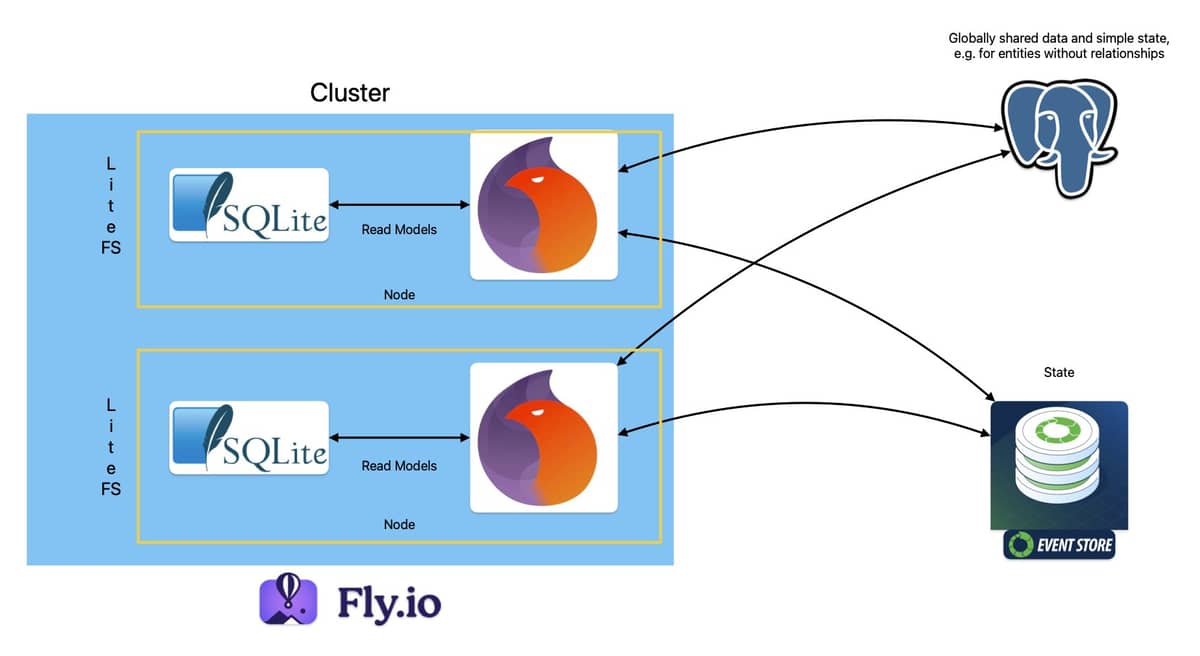
It can do global load balancing AND you can have instances across the globe on the same virtual network so you can actually run a normal global distributed beam setup. Then just do some smart ETS caching and you’re good.
Not sure how the beam would handle latencies in practice. I’ve read of issues there but it would be simple enough to try. Just keep an eye on your egress bill
Yeah that’s what I’m thinking when it comes to it: audit of our LV usage to cut down any unnecessary interaction, then multi-region GKE cluster with read replicas in each region and see how it works. We’re currently using discrete horizontal scaling without experiencing any real drawbacks - i.e. no distributed BEAM - so it might just work. When I get some time (hah) I might spin up a multi-region cluster and run some latency tests etc.
TBH this is why I went with GCP: as well as a better Kube product, their networking is really good.
The process which pulls these log messages on page load starts a task on each node to get the recent log events cache, combines and returns them.
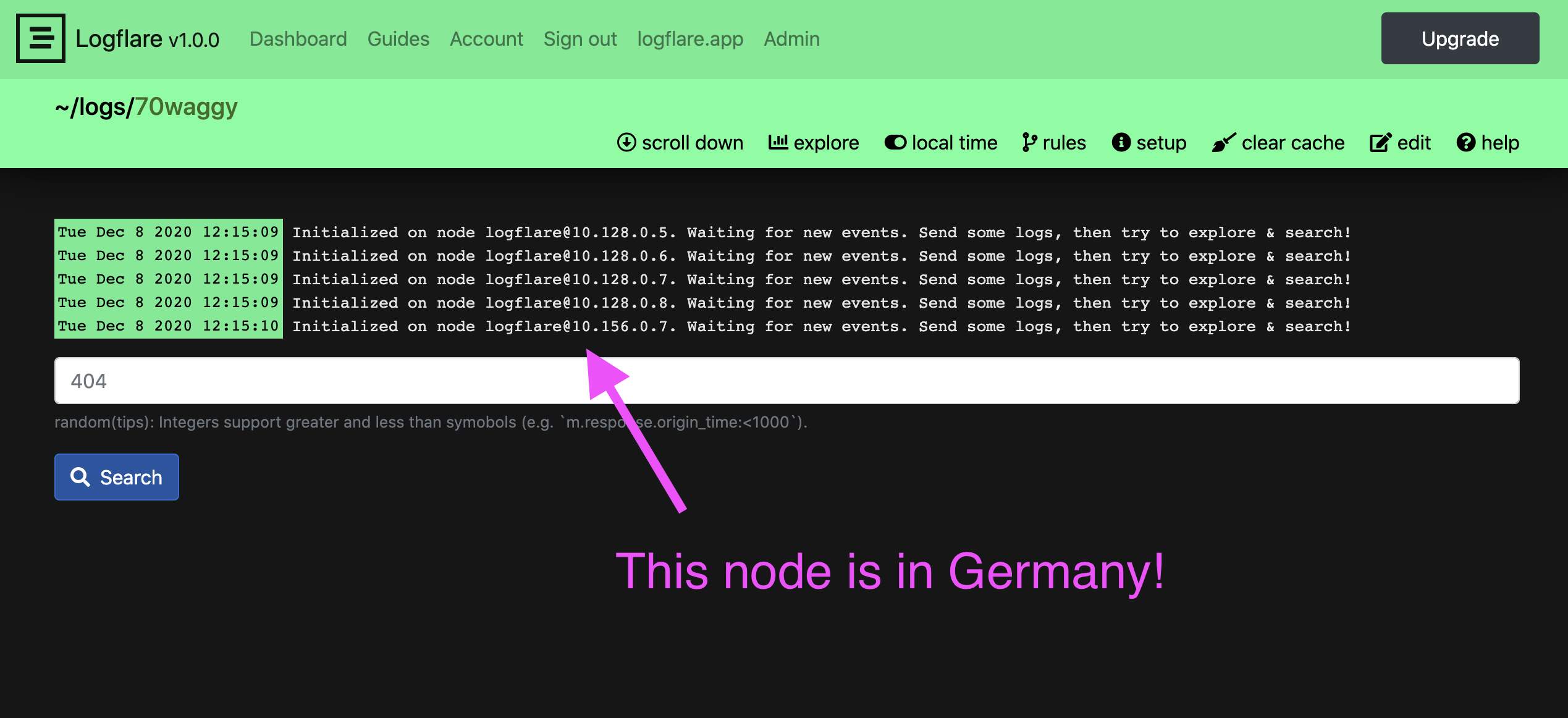
The Germany node is not serving traffic yet. All nodes are talking to the Postgres hosted in the US. We do a bunch of queries on node boot and did get some Ecto timeouts there so I’m not sure we’ll be able to serve traffic until we get a replica over there too.
But with Google Global load balancer all EU traffic should go directly to this node, and all US traffic will go to the US nodes. And when you load the page up it collects data from all nodes globally and displays that data.
Not yet. I pulled that node down as we’re replicating our rate limiting data via PubSub to each node and the data transfer was a bit much.
Hopefully week after next we’ll roll out more precise caching which will let us just run one db node. And then each continent will be a separate cluster to avoid the PubSub transfer costs. Rate limits will be per cluster. Global load balancing will still be sending data per each request to the closest Logflare cluster which will be great for our EU users.