If a scheduler thread runs a blocking code, it will block. Therefore any potentially long-running synchronous syscall could lead to thread exhaustion.
However, a benefit of Erlang runtime over most others is that you can only block a scheduler if the BIF you’re calling is blocking, whereas in other runtimes you can do it with your own custom logic. IIRC, blocking a go scheduler was as simple as for {}, and I suppose that in node something like while(true); should do the job
Consequently, the Erlang approach has an interesting potential: the runtime layer could completely prevent blocking and thread exhaustion. I don’t know how many potentially long-running blocking syscalls are currently used. It would be interesting to know that and see if there are possibilities to eliminate them or provide alternative solutions.
Good luck with that when DNS does not work. If your sshd.config has UseDNS you are screwed; if your sshd.config has UsePAM, and your PAM setup look up names you are also screwed. Hell, if your shell’s prompt has \h in it (VERY common), it will do hostname -f for every new shell to spawn.
The DNS service server is what he want to connect with via a remote shell, and what you are referring too is DNS problems in the machine trying to connect to the remote shell, thus it’s not the same, aka you can have the remote DNS service server innoperational, but from the moment you have your laptop with a working DNS then you can fire-up the remote shell.
The point of the (now huge) Twitter thread to me seemed to have come from “is it possible to starve a thread pool comprised of raw OS threads” and slow/unresponsive DNS was given as an example.
The answer is always “yes, it can”. Handing the keys to the kingdom to most programmers nowadays is a no-go because they have no clue there are actual physical limitations there. Do try and spawn 50,000 threads on your machine. Unless you have $25,000+ workstation you’ll start seeing your machine lag at the 3000th or even 2000th mark.
As others have remarked both here and in the Twitter thread, there’s a LOT that can be done. But the original poster seemed to do his very best to be not impressed (I pointed that out to him at the end of my participation). And the discussion got perverted to “but there ARE ways for all languages / runtimes to alleviate the problem!” which is IMO a discussion stopper.
Of course there are ways. There are ways to not litter parks yet people do it anyway. There are ways to have wooden furniture without destroying the Amazon forest but it’s destroyed anyway. Etc.
Same goes for languages/runtimes; he made a few remarks that modern languages are starting to learn from Erlang to which I simply responded “but I need the results today”. I won’t care much if PHP and Ruby and Python are finally green-thread-enabled 20 years down the line. This makes for inspirational history books but in the meantime all of us have to work with something.
So the discussion started off well but it failed to stick to the main point: “which languages/runtimes do it better TODAY?” – and as I also remarked in the Twitter thread, theoretical constructs like “every language can be as good as Erlang” is not an interesting or productive discussion.
@garazdawi Thanks for the links. I learned valuable things from them.
This seems to me that is far to be the correct way of doing it in Erlang, therefore maybe some Erlang developer from this forum can put a Pull Request to fix it?
Maybe @garazdawi can shed us some light or point us to someone who can?
I don’t know. The guy didn’t seem to discuss entirely in good faith, plus the discussion took an un-productive turn (focusing on theory and the far future and not on what’s available right now), thus I bailed out last night.
I and others have presented facts. From then on he and everyone else can think what they like.
Well I am not a fanboy of Erlang , but I was genuinely interested in knowing how the beam would address the scenario he was describing, that we now know that is the Uber meltdown and we even know the repo.
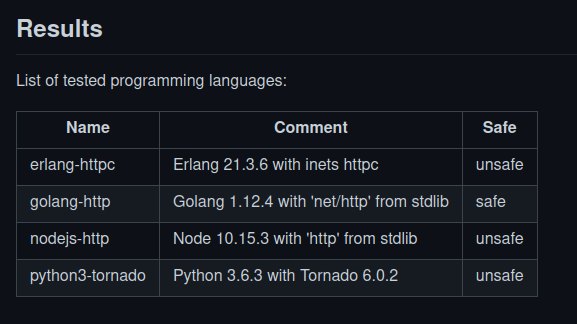
So, what do you think about the Erlang code on that repo?
Someone tried to add a dotnet pull request to the repo based on the Twitter discussion, but failed, the pull request is now closed:
Oh, you’ll have to pay me to study that, sorry. Not interested in that particular discussion any longer – I got what I needed from it.
I am not as well, but many people project (in this case this expression means “they judge for others by themselves”) and think that if you love a particular piece of technology then you are a fanboy who is not interested in facts. I can’t stop them from having the wrong conclusion but I don’t have to engage them (for more time than is needed) as well.
Almost 5 years ago I decided to try Elixir for something that a Ruby on Rails code was horrible at – and it paid off hugely. While I am not a big fan of web projects work I still do it because Phoenix is a very well done framework, and the OTP reaps us several important benefits, especially in today’s world where Moore’s Law gains are dwindling all the time.
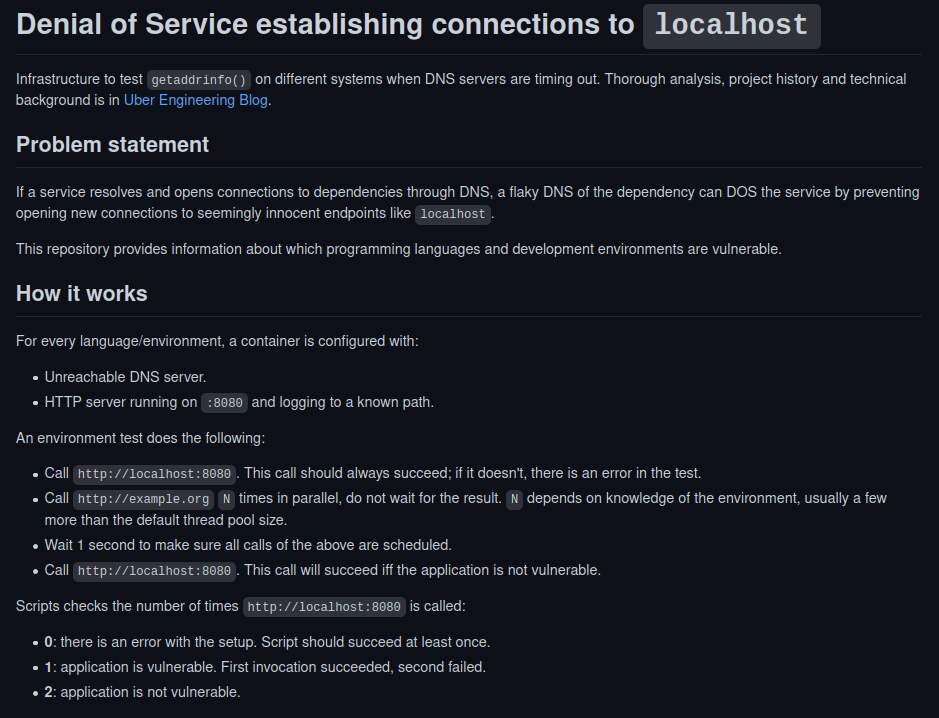
I think the whole test is flawed. It basically boils down to
“If DNS is not resolvable, can a language still resolve localhost given it already had N pending DNS requests in flight?”
Of cause erlang can be made to pass this test by configuring to use inet_res. However, this is not solving the real problem. If I were the ops people responsible for this, I want the whole shit to hang right there, and raise a giant red flag, so I know there is something seriously wrong. Limping along in a very limited way (only localhost is resolvable) is not helping anybody.
I replied on Twitter, but for completeness I’ll also respond here.
The Erlang implementation runs everything sequentially, while readme mentions that potentially exhausting reqs should be started in parallel (which is e.g. done by the go implementation).
I couldn’t get that repo to work on my machine, so instead I made a slightly alternative version in Elixir (uber_denial_by_dns_test.exs · GitHub) which passes. Sanity review is welcome
A few things that might work correctly even if DNS resolver is laggy/non-responsive:
Accepting incoming connections
Serving responses which don’t require connecting to a remote server
Interacting with remote servers if connections were established while DNS resolver was responsive
remote shell + debugging
In fact, the system might live through the period of increased dns resolver lagginess without significant availability issues.
You can raise a red flag without hanging the “whole shit” , e.g. by having some metrics + alerting system in place. E.g. the system reports dns resolver status to some remote server, and some job on that remote server raises an alert if no status (or invalid status) is reported within some time period.
Correct me if I am wrong. And I am not sure whether you are using inet_res or not in your code in the first place. But if the you keep increasing the number of parallel requests, then one of the following will happen eventually:
for native resolver with OS thread_pool, the thread pool will be exhausted
if the thread pool will dynamically allocate new OS thread to the pool, it will hit the limit of total allowed OS threads
for async UDP based inet_res, it will hit the total number of file handles or ports limit
IMHO, the last two scenarios are even more disastrous than the first one, and are harder to pin point the culprit too.
I didn’t set any specific config, so I think the native resolver is used. As explained in this earlier post it is a port program that uses a pool of threads. I didn’t read the impl, so I’m not sure if the pool is dynamically expanded.
I’m using 100 concurrent reqs in this test. Also tried with 1000, and it worked the same.
Assuming that no unbound pool growth is taking place, the thread pool in this port would be exhausted. However, these are not scheduler threads, so everything else could still work without problems, which is to me the main point of the original twitter discussion. Once the dns server becomes responsive, dns resolving should resume to work too. So we get limitation of negative effects of failures, and self-healing.
This could happen if the client code is using unbound concurrency to talk to remote services. I regard this as an architectural problem in the client code, and this issue could happen even if dns resolving works normally.
I read the implementation of the port program, and I think it will grow the pool and there is no artificial bound other than what is imposed by the OS. Another interesting detail is when number of free workers is low, it will try to piggy back to a busy worker that is resolving the same hostname. Since in this test all failing resolve is to the one single host: example.org so the dynamic growth will never be triggered
It makes sense and defeats the purpose of this test at the same time. We could pass this test with any number, yay.
I actually did try with dynamic names (e.g. example1.org, example2.org, etc) and that worked equally well, though I didn’t try it with a larger number of concurrent processes (e.g. 100k of them).
If this is done, it should be a decent protection against system limit exhaustion, since I expect that in many practical scenarios the number of remote servers that have to be resolved is small and limited. One exception that comes to mind would be a crawler (and there are probably other examples), but in such cases you definitely want to limit the amount of concurrent requests, which should also mitigate the issue.