Thanks! Any feedback is appreciated!
Aludel v0.1.10 Released
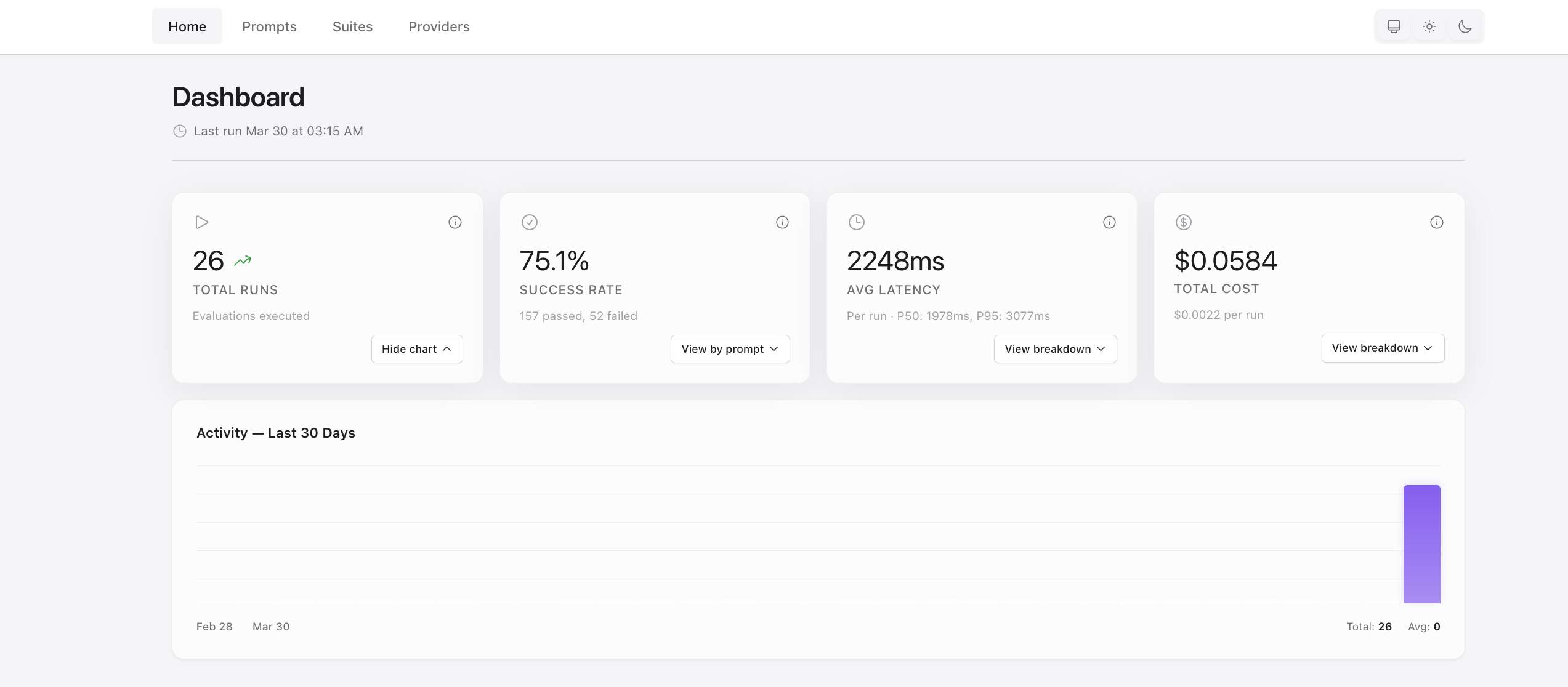
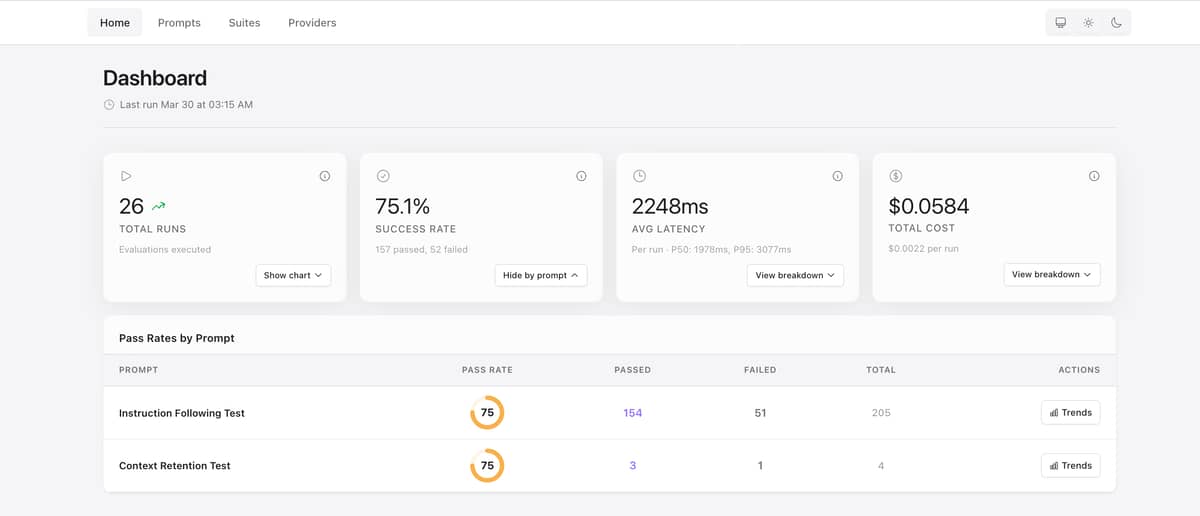
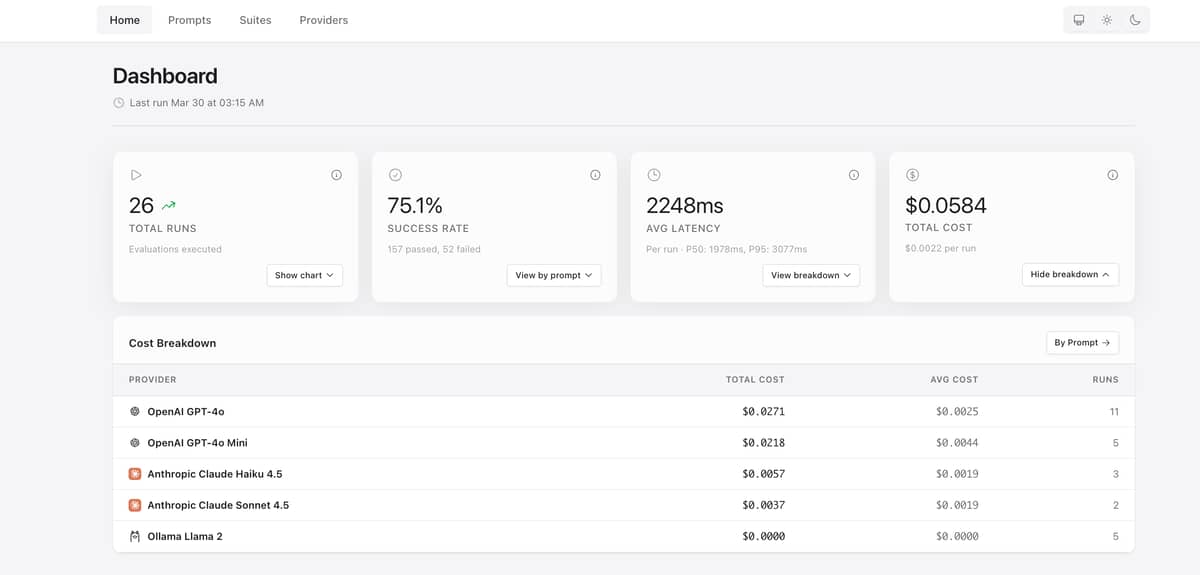
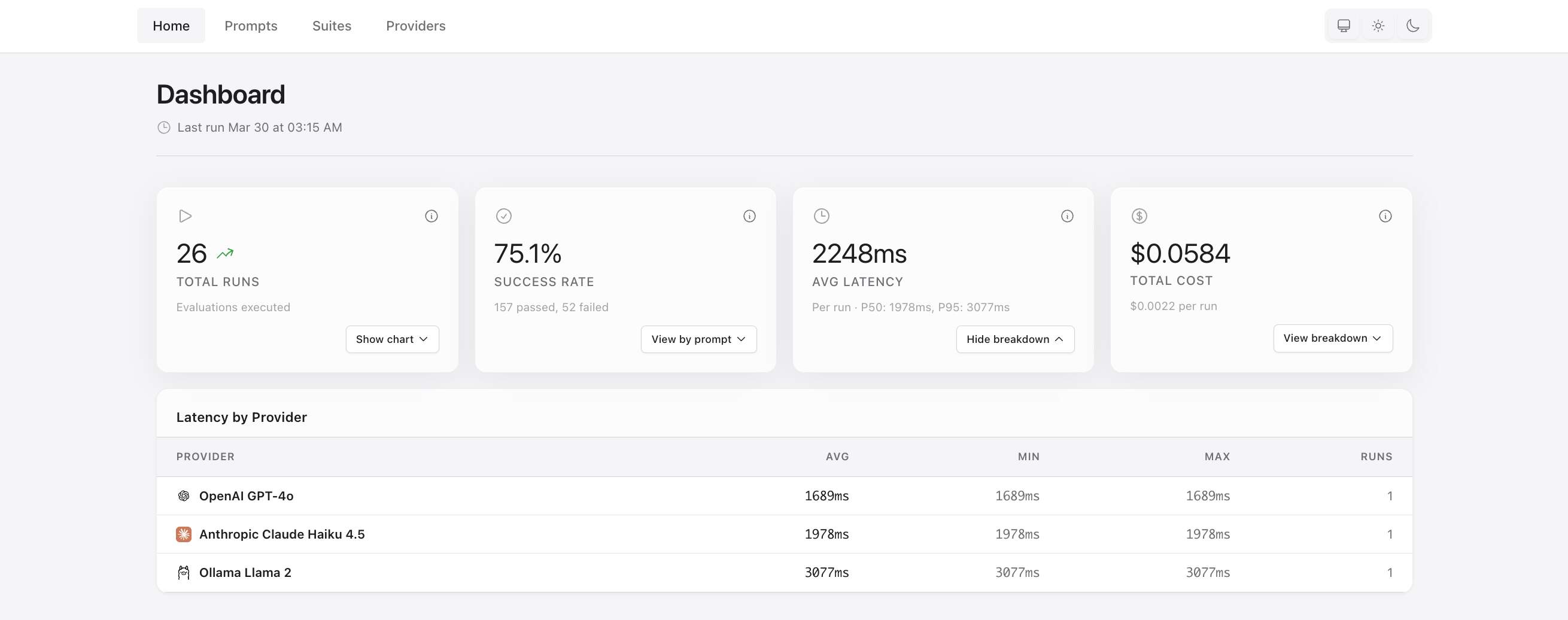
Small update with dashboard UI improvements:
- Pass rates by prompt can now be toggled from the Success Rate card (consistent with other
breakdown sections) - Better table spacing in dashboard breakdowns for improved readability
- Internal refactoring for cleaner provider icon handling
@sezaru I started a branch to refactor LLM HTTP layer: refactor(llm): refactor LLM HTTP layer by ccarvalho-eng · Pull Request #38 · ccarvalho-eng/aludel · GitHub . It should replace Req for ReqLLM and have a good framework using HTTP adapters. That should make it easier to add more providers
Thanks man! Looking great ![]() !
!
Also, just a small thing, I didn’t look at the code, but I saw in the pr changes that you are using mox for mocks right? Just in case you don’t know, Req has amazing support for testing out-of-box Req.Test — req v0.5.17
Good to know! Feel free to push a PR or open an issue if you think it’s going to help more than Mox or it’s more efficient. Does ReqLLM inherit that test framework?
In case anyone has used this and think somehow it’s useful, which LLM providers would you most want to see in Aludel next?
Currently supported: OpenAI, Anthropic, Ollama.
Considering: Gemini, Mistral, Groq, Cohere, AWS Bedrock.
What are you actually using in your Elixir projects that you’d want to evaluate against?





















