
webofbits
Aludel - LLM prompt evaluation workbench

Aludel - LLM Evaluation Workbench
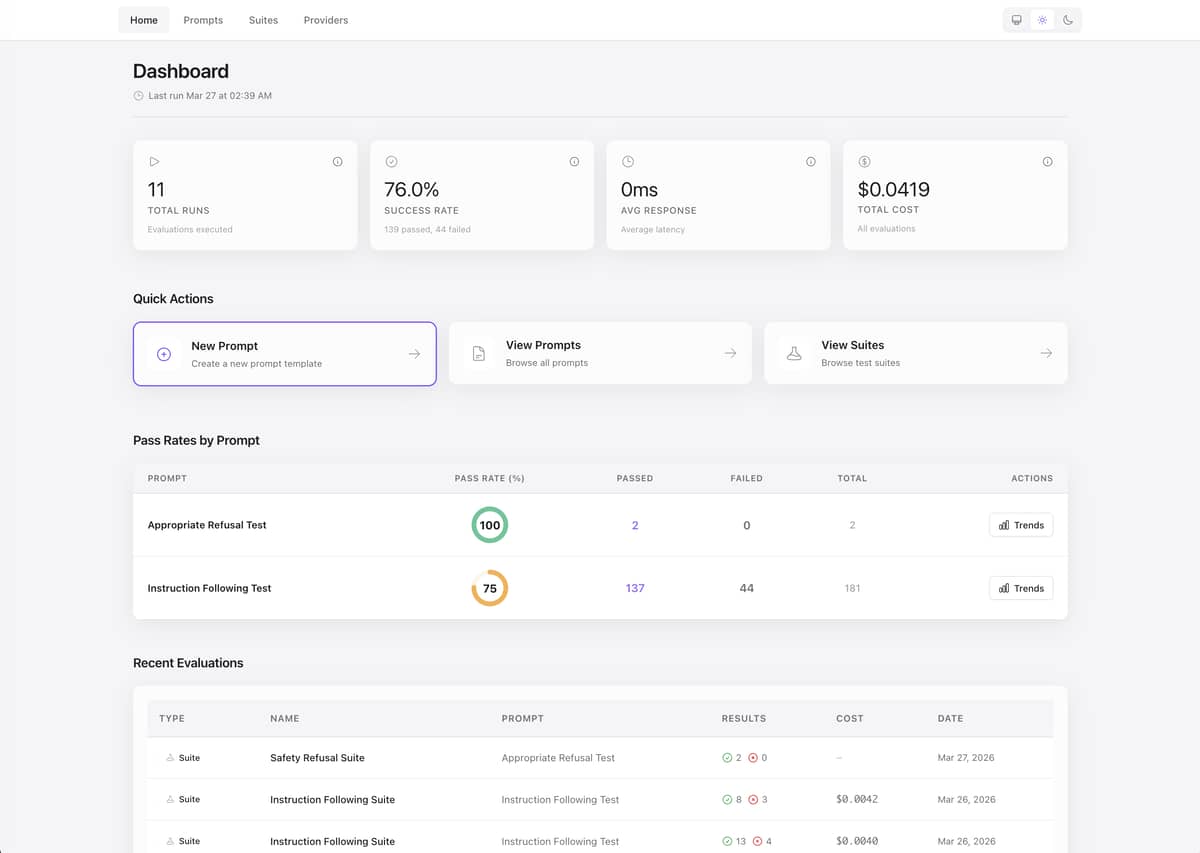
Aludel is an embeddable Phoenix LiveView dashboard for evaluating and comparing LLM prompts across multiple providers (OpenAI, Anthropic, Ollama) simultaneously. It helps developers test prompt quality, track costs, and catch regressions with automated evaluation suites.
What it does
Run the same prompt across different LLM providers side-by-side and compare:
- Output quality — See responses from GPT-4, Claude, and local Ollama models together
- Performance metrics — Latency, token usage, and cost per request tracked in real-time
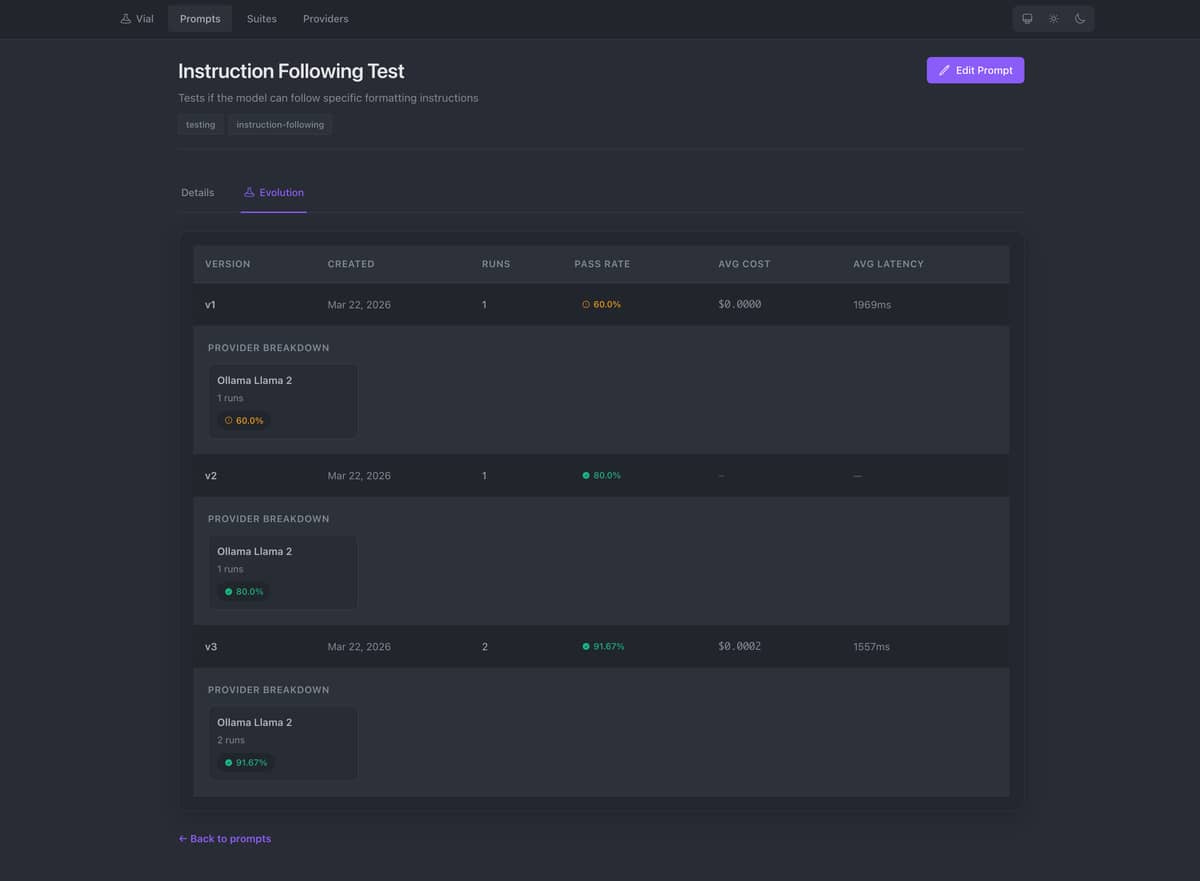
- Evolution tracking — Visualize how prompt versions perform over time with pass rates, cost, and latency trends
- Regression testing — Automated evaluation suites with assertions (
contains,regex,exact_match,json_field) - Prompt versioning — Immutable prompt versions with
{{variable}}interpolation
Key features
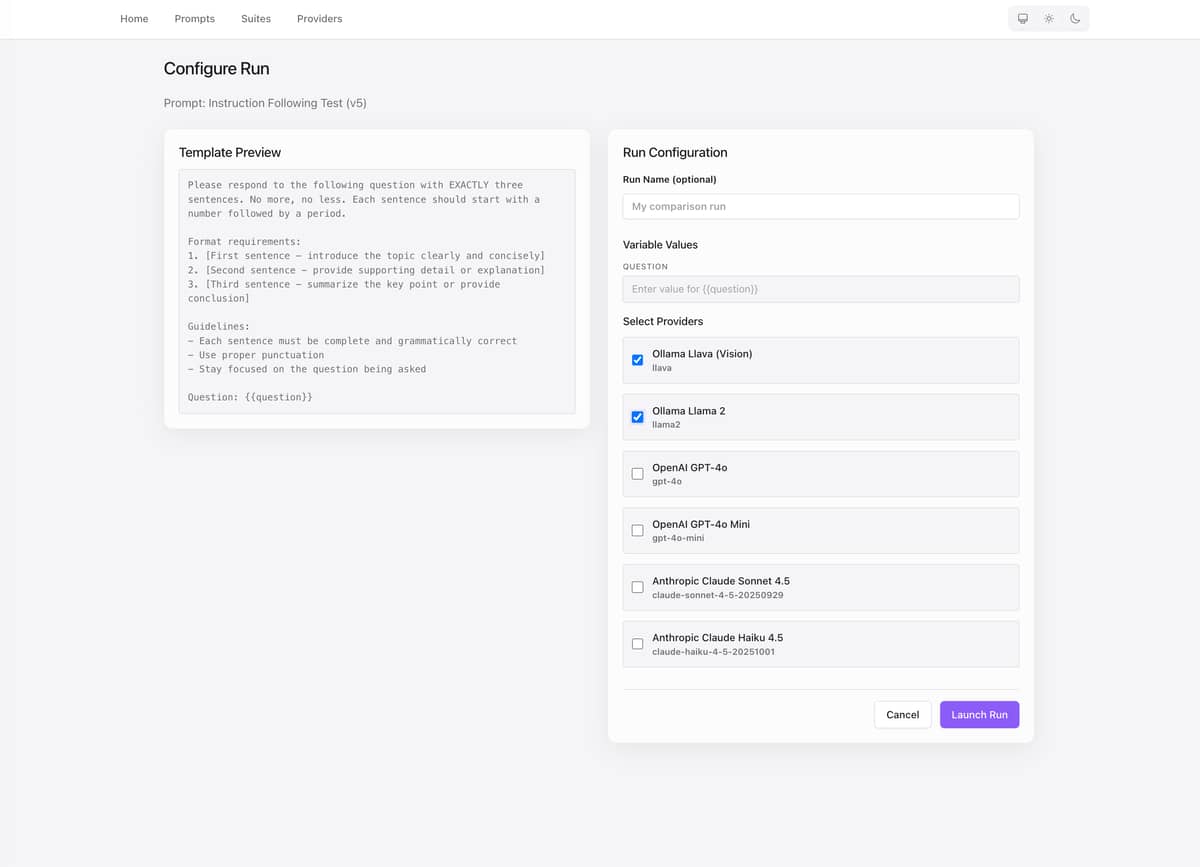
- Multi-provider execution — Send one prompt to OpenAI, Anthropic, and Ollama concurrently. Results stream in real-time.
- Cost tracking — Automatic cost calculation based on token usage and provider pricing.
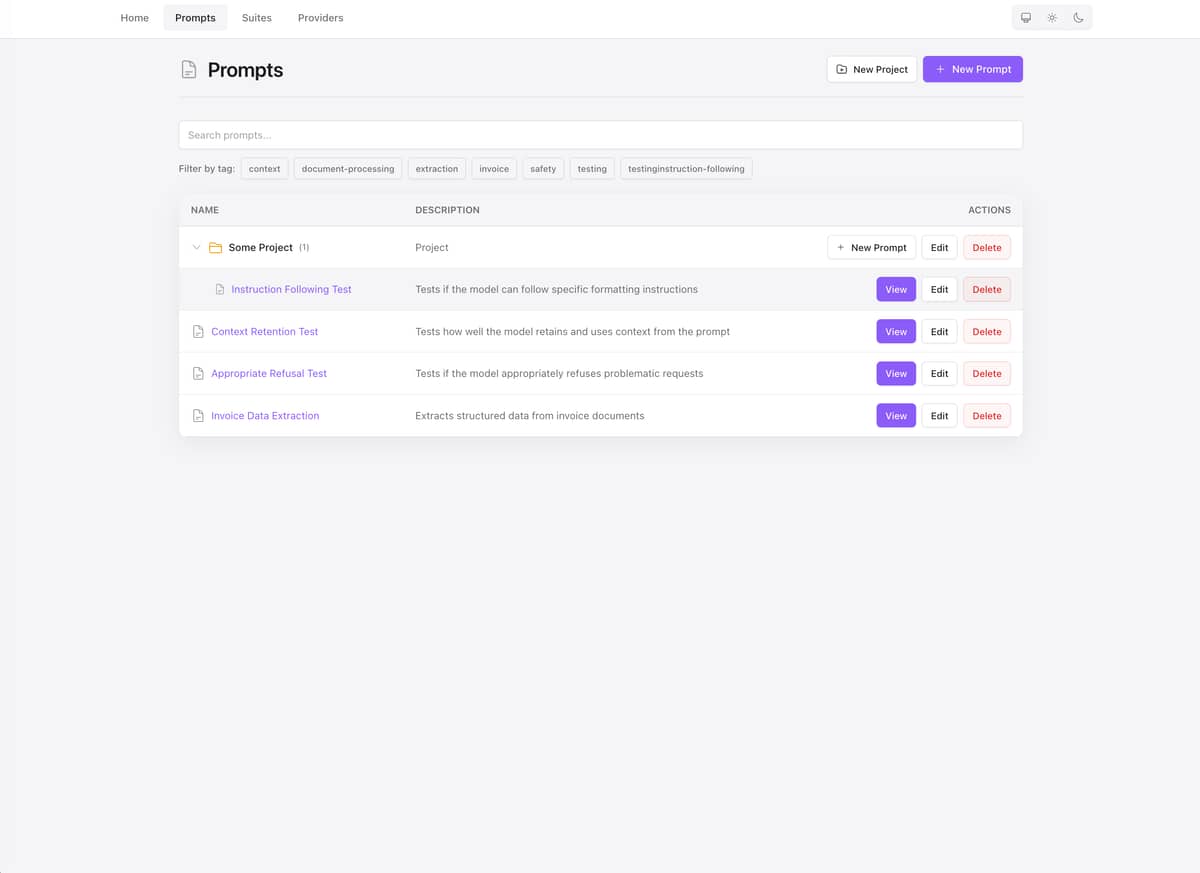
- Evaluation suites — Visual test case editor with document attachments (PDF, images, CSV, JSON, TXT). Run automated assertions against LLM responses.
- Dashboard — Live metrics as runs execute: cost trends, latency, and per-provider performance.
- Local-first option — Works with Ollama out of the box (no API keys required). Add cloud providers optionally.
- Embeddable — Add to any existing Phoenix LiveView app as a self-contained dashboard, or run standalone.

Example workflow
# 1. Create a versioned prompt template
"Explain {{topic}} in exactly 3 sentences."
# 2. Run across 3 providers simultaneously
# - Ollama (llama3, local)
# - OpenAI (gpt-4o)
# - Anthropic (claude-sonnet-4)
# 3. View side-by-side comparison in real-time:
# Provider | Latency | Tokens | Cost | Output
# Ollama Llama3 | 1,234ms | 45/123 | $0.0000 | ...
# OpenAI GPT-4o | 856ms | 52/145 | $0.0019 | ...
# Claude Sonnet | 1,102ms | 48/138 | $0.0018 | ...
# 4. Create evaluation suite with assertions
# - Assert output contains "three sentences"
# - Assert output matches regex pattern
# - Run regression tests on prompt changes
Use cases
- Prompt engineering — Test variations across providers to find the best prompt/model combination
- Cost optimization — Compare pricing and quality trade-offs between providers
- Quality assurance — Automated regression testing when updating prompts or switching providers
- Provider evaluation — Benchmark performance, cost, and quality across OpenAI, Anthropic, and local models
- Offline development — Use Ollama for local development without API costs
Installation
Aludel can be embedded into any Phoenix LiveView application or run standalone.
As a dependency (embedded mode)
# mix.exs
def deps do
[
{:aludel, "~> 0.1"}
]
end
# config/config.exs
config :aludel, repo: YourApp.Repo
# lib/your_app_web/router.ex
import Aludel.Web.Router
scope "/dev" do
pipe_through :browser
aludel_dashboard "/aludel"
end
mix aludel.install # Copy migrations
mix ecto.migrate
mix aludel.seed # Optional demo data
Standalone mode
git clone https://github.com/ccarvalho-eng/aludel.git
cd aludel/standalone
mix deps.get
mix ecto.setup
mix aludel.seed # Optional demo data
mix phx.server
# Visit http://localhost:4000
Requirements: Elixir 1.19.5+, Erlang/OTP 28.4+, PostgreSQL 17+
Optional: ImageMagick v7+ (for PDF support with Ollama vision models)
Current status
Active development. Core features complete. Available on Hex.pm with CI/CD, and security scanning.
![]() Multi-provider execution (OpenAI, Anthropic, Ollama)
Multi-provider execution (OpenAI, Anthropic, Ollama)
![]() Real-time result streaming with LiveView
Real-time result streaming with LiveView
![]() Cost and latency tracking
Cost and latency tracking
![]() Prompt versioning and evolution tracking
Prompt versioning and evolution tracking
![]() Evaluation suites with document attachments
Evaluation suites with document attachments
![]() Side-by-side comparison UI
Side-by-side comparison UI
Links
- GitHub: GitHub - ccarvalho-eng/aludel: LLM Evaluation for Phoenix Apps · GitHub
- Hex.pm: aludel | Hex
- Discussions: ccarvalho-eng/aludel · Discussions · GitHub
- License: Apache License 2.0



Most Liked
webofbits

webofbits
Minor updates:
- Dashboard Revamp - Glass morphism styling
- Improved Dark Mode - Updated to One Dark color palette for better contrast
- Prompt Evolution - New evolution tab for tracking prompt performance over time (kudos to @mikehostetler for the idea i.e. feat: integrate GEPA for prompt evolution and optimization · Issue #12 · ccarvalho-eng/aludel · GitHub )
- Branding Updates - Added beaker icon to navigation and favicon
- UI Polish - Modernized button design, improved modals, consistent styling across pages

Popular in Announcing










Other popular topics





 Latest Phoenix Threads
Latest Phoenix Threads
Latest on Elixir Forum
Sponsor Spotlight

We build reliable cloud platforms for business-critical systems.
Categories:
Sub Categories:
Forums
Popular Tags
- #ecto
- #liveview
- #troubleshooting
- #learning-elixir
- #deployment
- #library
- #erlang
- #testing
- #genserver
- #mix
- #absinthe
- #remote-other
- #otp
- #plug
- #how-to-question
- #macros
- #postgres
- #channels
- #elixirconf
- #exunit
- #discussion
- #code-sync
- #javascript
- #podcasts
- #onsite
- #dialyzer
- #docker
- #authentication
- #umbrella
- #full-time-contract
- #podcasts-by-brainlid
- #ecto-query
- #elixir-ls
- #phoenix_html
- #iex
- #blog-post
- #graphql
- #genstage
- #ai
- #websockets
- #supervisor
- #advent-of-code
- #elixirconf-us
- #distillery
- #processes
- #forms
- #api
- #metaprogramming
- #security
- #hex
Our Sponsors

Build Elixir applications with speed and confidence.

Supporting innovation across the BEAM ecosystem.
We build reliable cloud platforms for business-critical systems.

Catch errors, track performance, monitor hosts and more.

Error tracking for Elixir devs who love to ship. Start your free account.

Practical resources that improve the lives of professional developers.

Producing high quality Elixir screencasts since 2017.

The deployment platform built for Elixir: PaaS ease, VPS control.

The team behind Membrane, Popcorn, LiveDebugger. Available for hire.

Courses that'll move you from confusion to "Aha, now I get it!"