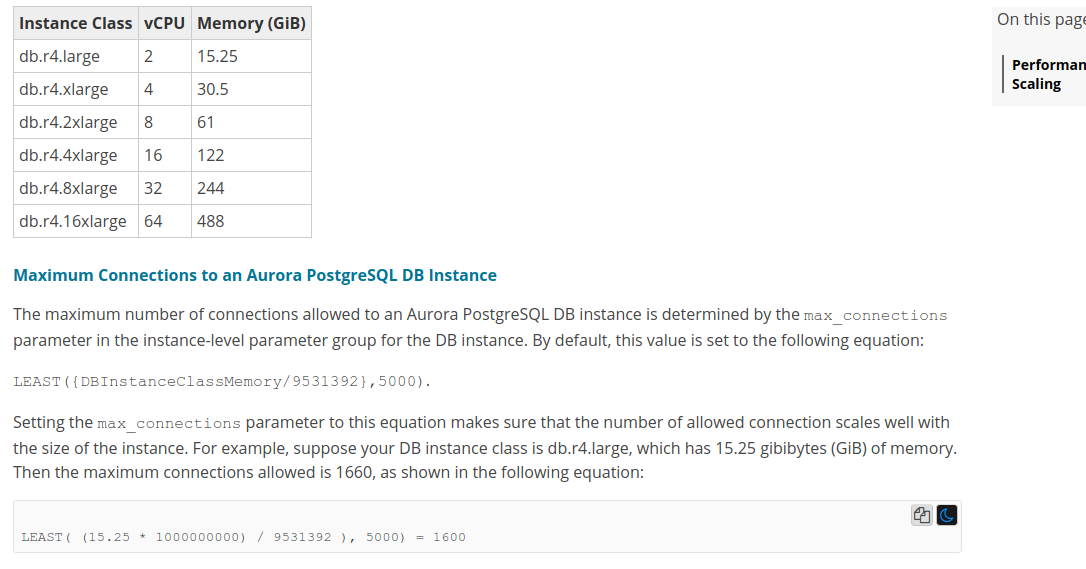
Following the aws documentations:
The instance db.r4.large with 2v CPUS and 15.25GB allow up to 1600 connections.
I’m working on a real-time application that consumes a good amount of database resources and needs to open multiples database connections to provide data to users.
I run some tests(with pool_size: 10) and sometimes I got ** (EXIT) time out with a few users.
I read in some sources and some people say to set the pool_size based on CPUs… but may i need more, let’s say, 200/300 or even 1000 connections opened…
if I can’t set more connections with this db.r4.large instance, what I need?
So, can I set the pool_size based on Aurora PostgreSQL DB Maximum Connections? Someone can give me an advice and share experience about this?
1 Like
Maybe you should check out for slow queries and optimize them, or, if that’s not possible, increase ecto’s timeout for tests.
3 Likes
@kelvinst is correct. If the issue is slow queries, then increasing the pool won’t fully solve the problem, because you will still hit the timeout issue on long queries. You need to measure the query time and queue time reported by Ecto and see which one is the cause of your timeouts.
3 Likes
Good Point,
I already started to check it and I’ll optimize and create partial indexes…
Related to Ecto pool_size x AWS Aurora max_connections, someone has an advice? It’s ok to increase the pool_size according to AWS Postgresql max connections or I can have a problem with it?
1 Like
Increasing the pool size can only help if you have a high queue_time as reported by ecto. In general, though, the pool shouldn’t be too big - the app can be actually slower with a too big pool.
With each connection in the pool there’s some additional overhead. Each connection, when idle, requires periodic heartbeat - this adds some “background” work. Additionally the query cache is per connection which means the chance of running an already prepared query on any given connection is much lower in a large pool. Finally, it increases resource use on the database server, potentially slowing everything down on that end.
4 Likes