
maxim
Another cast vs dump question for a custom Ecto type
Hi folks,
I’ve written custom types before, but this specific case gives me pause, and I wonder if you could explain your reasoning here when deciding how to split this logic between cast and dump.
I have a list of base-3 integers that I store in the database as a :binary (postgres bytea).
The value that I assign looks like this (up to 127 digits):
[0,2,1,0,2,2,1]
The value database stores looks like this
[0,2,1,0,2,2,1] |> Enum.reverse |> Integer.undigits(3) |> :binary.encode_unsigned
# <<5, 112>>
However, I have to run 3 checks:
- Is this a list?
- Is length in
0..127 - Are all digits in
0..2?
What part of this goes into cast, and what goes into dump?
Here’s what I think, correct me if I’m wrong:
- Cast runs the above 3 checks, but keeps it a list.
- Dump ALSO runs the 3 checks (in case value was assigned without
cast) but converts it into a binary.
However, those 3 things are quite a bit of code. Between 2 guards and an Enum.any? they traverse the whole list a couple of times. If this is correct, am I supposed ignore the fact that I’m running the same logic twice, once for cast and once for dump?
Marked As Solved

LostKobrakai
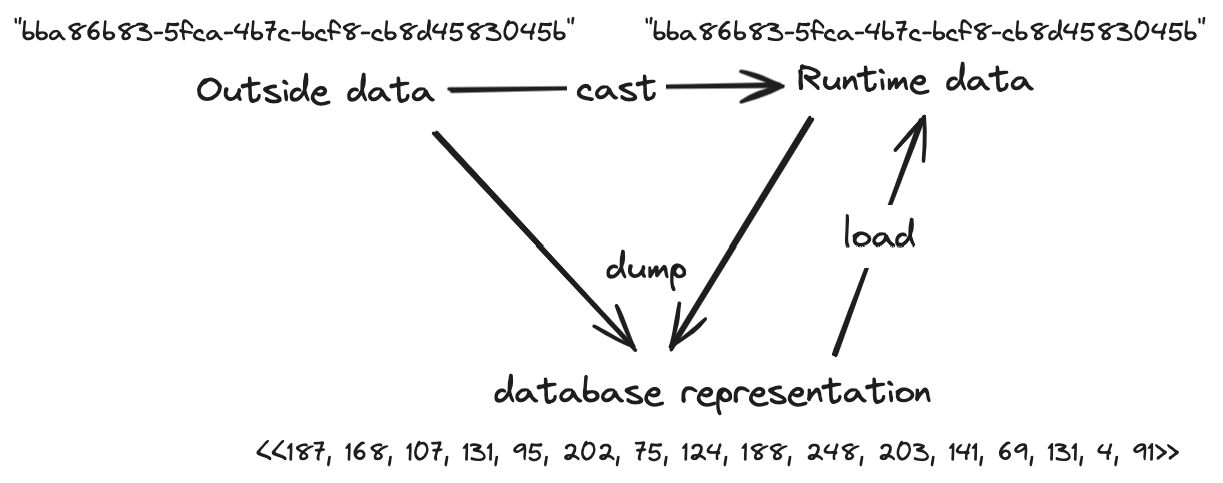
Ecto.Types handle 3 different data representations. Outside data (most often from form inputs, or json fields in the db), runtime data (how your data is put into your structs by ecto and used at runtime) and the database representations as db column.
cast goes from outside data → runtime data
dump goes from anything (outside data or runtime data) → database column data
load goes from database column data → runtime data
For json (map) fields there’s also
json encoding from anything → database json value
cast from database json value → runtime value
The reason why cast/json encoding need to deal with “anything” is because there’s nobody stopping you from inserting data via Repo.insert_all or manipulating a struct manually and there’s no casting involved. So any validation of correct data needs to be done in both cast and dump, where one converts to runtime data and the other to database column data.
Also Liked

axelson
I like visuals so I made a visual to represent @LostKobrakai’s awesome explanation:

And one thing that sometimes confuses (me at least) is that sometimes the “Outside data” and “Runtime data” have the same representation, for example for Ecto.UUID. Seeing it in this visual form makes the reason behind that easier for me to understand/remember:
LostKobrakai

NobbZ
I’m not sure where to put the checks, but at least I can tell you that you only need to iterate once, roughly like this:
def valid_custom_type?(list) do
list
|> Enum.reduce_while(0, fn
_d, l when l > 127 ->
{:halt, :invalid}
d, _l when d not in 0..2 ->
{:halt, :invalid}
_d, l ->
{:cont, l + 1}
end)
|> is_integer()
end
This will iterate not more than once and not more than the first 128 digits of the list.
Due to the early return it should not become a bottleneck that soon.
Popular in Questions






Other popular topics



Latest on Elixir Forum
Sponsor Spotlight

Error tracking, logs, APM, uptime and cron monitoring in one dev-friendly platform. Find and fix problems before your users notice.
Categories:
Sub Categories:
Forums
Popular Tags
- #ecto
- #liveview
- #troubleshooting
- #learning-elixir
- #deployment
- #library
- #erlang
- #testing
- #genserver
- #mix
- #absinthe
- #remote-other
- #otp
- #plug
- #how-to-question
- #macros
- #postgres
- #channels
- #elixirconf
- #exunit
- #discussion
- #code-sync
- #javascript
- #podcasts
- #onsite
- #dialyzer
- #docker
- #authentication
- #umbrella
- #full-time-contract
- #podcasts-by-brainlid
- #ecto-query
- #elixir-ls
- #phoenix_html
- #iex
- #blog-post
- #graphql
- #genstage
- #ai
- #websockets
- #supervisor
- #elixirconf-us
- #advent-of-code
- #distillery
- #processes
- #api
- #forms
- #metaprogramming
- #security
- #hex
Our Sponsors

Build Elixir applications with speed and confidence.

Supporting innovation across the BEAM ecosystem.

We build reliable cloud platforms for business-critical systems.

Catch errors, track performance, monitor hosts and more.
Error tracking, logs, uptime, and Just Enough APM. Built for developers.

Develop your skills with books, videos, and courses.

Enabling companies to succeed by building software people love.

The deployment platform built for Elixir: PaaS ease, VPS control.

The team behind Membrane, Popcorn, LiveDebugger. Available for hire.

Courses that'll move you from confusion to "Aha, now I get it!"