I have some better news: Recently I was introduced to the Aja library, which implements multiple of data structures focused on performance. Its A.Vector is a persistent immutable array implementation, written fully in Elixir.
I wrapped A.Vector with the Arrays.Protocol (which was a breeze as Aja already exposes a very rich API ![]() ), and benchmarked them against the other implementations.
), and benchmarked them against the other implementations.
The results are amazing! ![]()
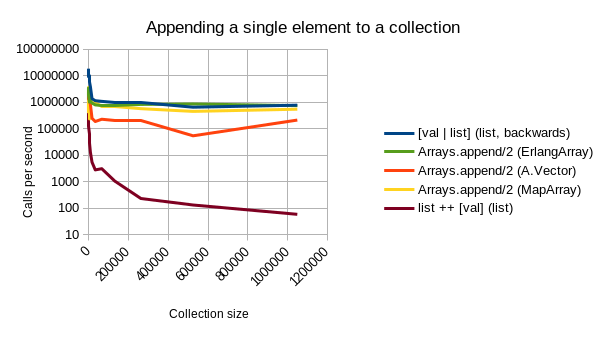
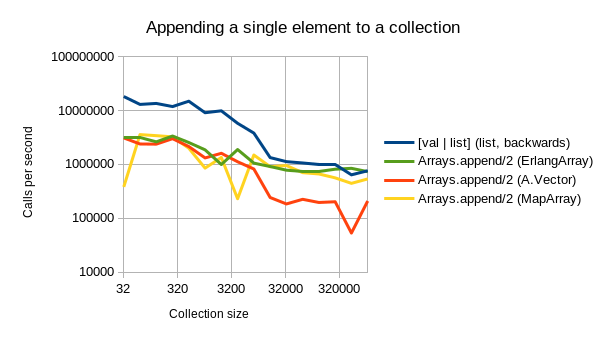
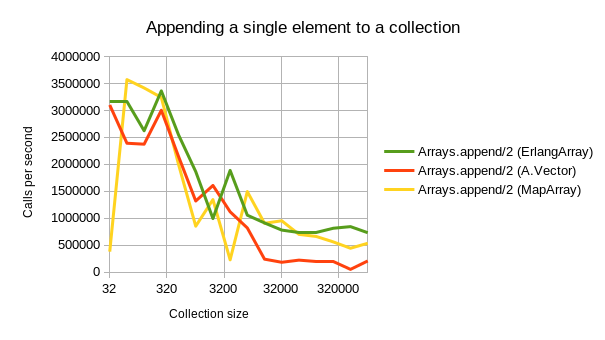
Aja’s implementation is fast. As can be seen from below benchmarking graphs, A.Vector beats the other alternative datatypes outright in most common tasks:
- Random reads are much faster regardless of array size. (and remain super fast even for very large arrays!)
- Random updates are slightly (~20%) slower than using an MapArray or ErlangArray for arrays with less than ~2^1 elements. After this, A.Vector is often much faster. (I do not yet know what causes the odd spike at 2^17 where A.Vector is super fast.)
- Appending a single element is similarly performant to the other implementations. At higher sizes, it keeps up with ErlangArray (where MapArray becomes much slower.)
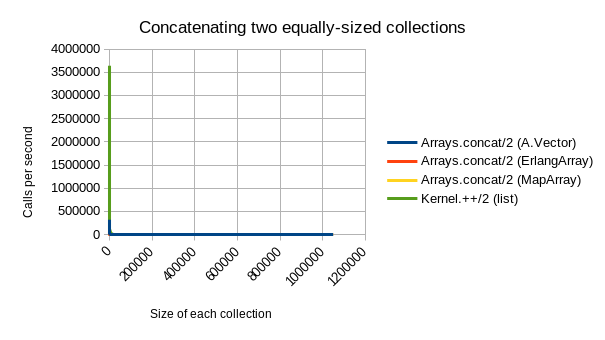
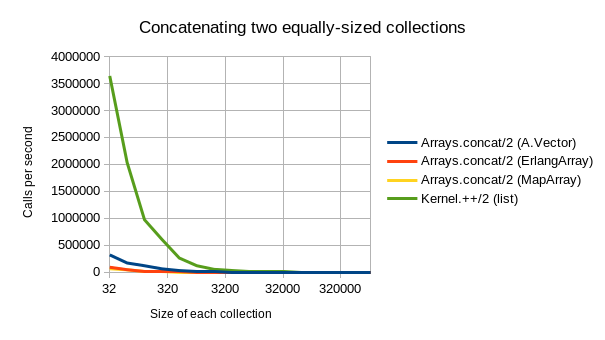
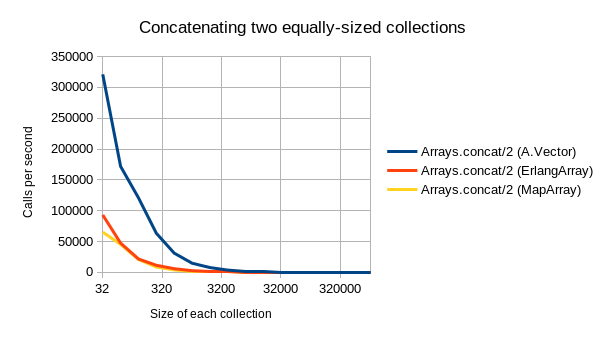
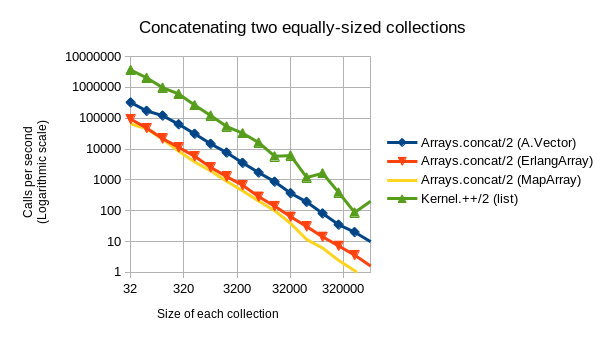
- Concatenating is where
A.Vectoralso really shines: It is roughly 5x(!) faster than ErlangArray and MapArray, regardless of collection size. It is only outclassed by plain lists (which are again ~5x faster for concatenation, but much (i.e. asymptotically) slower for all of the other three operations).
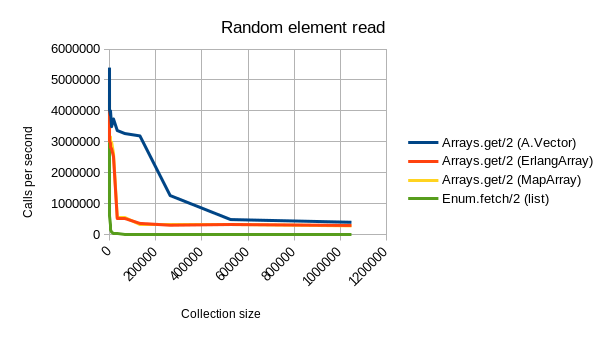
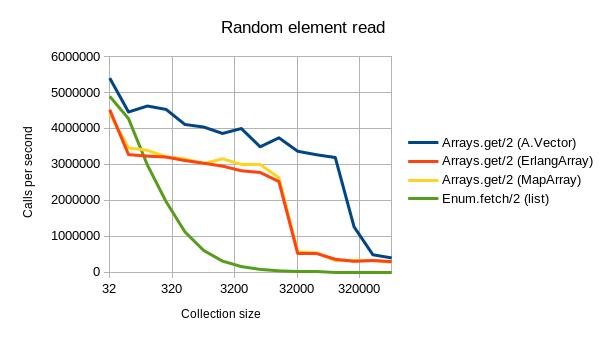
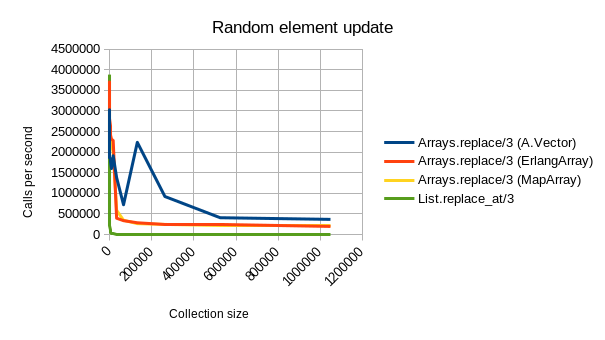
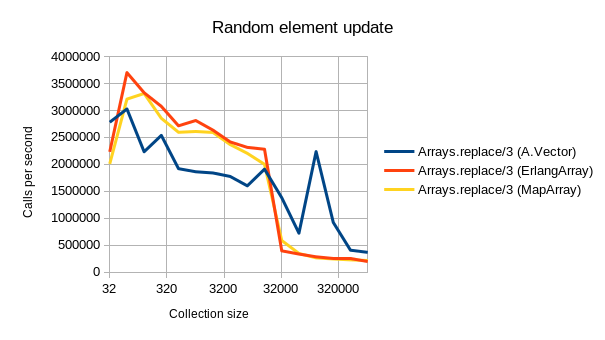
You can find ArraysAja on GitHub in a separate library, of which v0.1.0 has been published to Hex.PM.


















