
Qqwy
Arrays - Fast and versatile arrays with swappable implementations
While not as prevalent as in imperative languages, arrays (collections with efficient random element access) are still very useful in Elixir for certain situations. However, so far a stable and idiomatic array library was still missing, meaning that people often had to resort to directly using Erlang’s not-so-idiomatic :array module.
Arrays aims to be this stable, efficient and idiomatic array library.
Arrays
![]()
Arrays is a library to work with well-structured Arrays with fast random-element-access for Elixir, offering a common interface with multiple implementations with varying performance guarantees that can be switched in your configuration.
![]()
![]()
![]()
![]()
Installation
Arrays is available in Hex and can be installed
by adding arrays to your list of dependencies in mix.exs:
def deps do
[
{:arrays, "~> 2.0"}
]
end
Documentation can be found at https://hexdocs.pm/arrays.
Using Arrays
Some simple examples:
Constructing Arrays
By calling Arrays.new or Arrays.empty:
iex> Arrays.new(["Dvorak", "Tchaikovsky", "Bruch"])
#Arrays.Implementations.MapArray<["Dvorak", "Tchaikovsky", "Bruch"]>
iex> Arrays.new(["Dvorak", "Tchaikovsky", "Bruch"], implementation: Arrays.Implementations.ErlangArray)
#Arrays.Implementations.ErlangArray<["Dvorak", "Tchaikovsky", "Bruch"]>
By using Collectable:
iex> [1, 2, 3] |> Enum.into(Arrays.new())
#Arrays.Implementations.MapArray<[1, 2, 3]>
iex> for x <- 1..2, y <- 4..5, into: Arrays.new(), do: {x, y}
#Arrays.Implementations.MapArray<[{1, 4}, {1, 5}, {2, 4}, {2, 5}]>
Some common array operations:
- Indexing is fast.
- The full Access calls are supported,
- Variants of many common
Enum-like functions that keep the result an array (rather than turning it into a list), are available.
iex> words = Arrays.new(["the", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog"])
#Arrays.Implementations.MapArray<["the", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog"]>
iex> Arrays.size(words) # Runs in constant-time
9
iex> words[3] # Indexing is fast
"fox"
iex> words = put_in(words[2], "purple") # All of `Access` is supported
#Arrays.Implementations.MapArray<["the", "quick", "purple", "fox", "jumps", "over", "the", "lazy", "dog"]>
iex> # Common operations are available without having to turn the array back into a list (as `Enum` functions would do):
iex> Arrays.map(words, &String.upcase/1) # Map a function, keep result an array
#Arrays.Implementations.MapArray<["THE", "QUICK", "PURPLE", "FOX", "JUMPS", "OVER", "THE", "LAZY", "DOG"]>
iex> lengths = Arrays.map(words, &String.length/1)
#Arrays.Implementations.MapArray<[3, 5, 6, 3, 5, 4, 3, 4, 3]>
iex> Arrays.reduce(lengths, 0, &Kernel.+/2) # `reduce_right` is supported as well.
36
Concatenating arrays:
iex> Arrays.new([1, 2, 3]) |> Arrays.concat(Arrays.new([4, 5, 6]))
#Arrays.Implementations.MapArray<[1, 2, 3, 4, 5, 6]>
Slicing arrays:
iex> ints = Arrays.new(1..100)
iex> Arrays.slice(ints, 9..19)
#Arrays.Implementations.MapArray<[10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]>
Rationale
Algorithms that use arrays can be used while abstracting away from the underlying representation.
Which array implementation/representation is actually used, can then later be configured/compared, to make a trade-off between ease-of-use and time/memory efficiency.
Arrays itself comes with two built-in implementations:
Arrays.Implementations.ErlangArraywraps the Erlang:arraymodule, allowing this time-tested implementation to be used with all common Elixir protocols and syntactic sugar.Arrays.Implementations.MapArrayis a simple implementation that uses a map with sequential integers as keys.
By default, the MapArray implementation is used when creating new array objects, but this can be configured by either changing the default in your whole application, or by passing an option to a specific invocation of new/0-2, or empty/0-1.
iex> words = Arrays.new(["the", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog"])
#Arrays.Implementations.MapArray<["the", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog"]>
Is it fast?
I’m proud to finally present a stable release of this library for you all. Work on Arrays started a few years back but was on the backburner because of other projects. Now, I finally had some time to get back to it.
The library is heavily documented, specced and (doc)tested.
I’m very eager to hear your feedback! ![]()
~Marten/Qqwy
Most Liked
Qqwy
I have some better news: Recently I was introduced to the Aja library, which implements multiple of data structures focused on performance. Its A.Vector is a persistent immutable array implementation, written fully in Elixir.
I wrapped A.Vector with the Arrays.Protocol (which was a breeze as Aja already exposes a very rich API ![]() ), and benchmarked them against the other implementations.
), and benchmarked them against the other implementations.
The results are amazing! ![]()
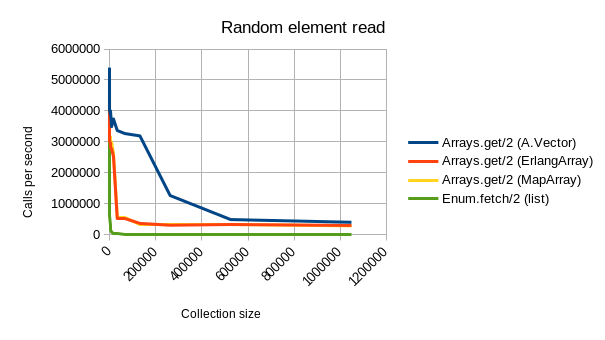
Aja’s implementation is fast. As can be seen from below benchmarking graphs, A.Vector beats the other alternative datatypes outright in most common tasks:
- Random reads are much faster regardless of array size. (and remain super fast even for very large arrays!)
- Random updates are slightly (~20%) slower than using an MapArray or ErlangArray for arrays with less than ~2^1 elements. After this, A.Vector is often much faster. (I do not yet know what causes the odd spike at 2^17 where A.Vector is super fast.)
- Appending a single element is similarly performant to the other implementations. At higher sizes, it keeps up with ErlangArray (where MapArray becomes much slower.)
- Concatenating is where
A.Vectoralso really shines: It is roughly 5x(!) faster than ErlangArray and MapArray, regardless of collection size. It is only outclassed by plain lists (which are again ~5x faster for concatenation, but much (i.e. asymptotically) slower for all of the other three operations).










You can find ArraysAja on GitHub in a separate library, of which v0.1.0 has been published to Hex.PM.
Qqwy
I have created a couple of benchmarks, and added them to the README.
Just like all benchmarks, these should be taken with a grain of salt.
There are probably ways to improve them.
EDIT: nicer and more recent graphs can be found a few posts further down. ![]()
Benchmarks
You can run the benchmarks locally by running mix run benchmarks/benchmarks.exs,
which will also output the HTML format with nice graphs.
Append a single element
Appending a single element is very fast on arrays, even as sizes grow.
MapArray and ErlangArray perform similarly.
For extra comparison, we look at lists both to see how slow list ++ [val] becomes as baseline,
but also how fast [val | list] still is:
In certain situations where a list can be treated as ‘backwards’, this can be a very simple way to append elements.
As doing this is built-in, it will always be faster than our arrays.
Thus, it serves as a ‘maxline’.


Random element access
Accessing a random element is very fast on arrays, even as sizes grow.
Arrays start beating lists significantly once the collection has more than 256 elements.
MapArray and ErlangArray seem to perform similarly < 8192 elements.
For larger sizes, ErlangArray seems to be a factor ~2 slower than MapArray again.



Random element update
Arrays start beating lists once the collection has more than 128 elements.
For sizes up to 131072 elements, MapArray seems to be between 100% and 30% slower than ErlangArray.
For longer arrays, MapArray wins out, with ErlangArray being ~30% slower.
It seems like put_in has some overhead w.r.t. calling Arrays.replace.
This warrants more investigation. Maybe Access has some overhead for its calls,
or maybe the implementations of get_and_update_in could be further optimized.

Concatenate two equally-large collections
Strangely, concatenation of large collections is very fast on lists.
Probably because all of it happens in a single built-in function?
Lists outperform arrays 20x-100x for this task.
Between ErlangArray and MapArray, ErlangArray seems to handle this task 50% faster when concatenating two 4068-element arrays, and twice as fast for larger collections.



From above benchmarks, we know (caveat emptor):
- For collections smaller than ~100-200 elements, there is no pronounced difference between using lists and arrays.
- For collections with more than ~100-200, but fewer than fewer than ~10_000-20_000, ErlangArray is a small constant amount faster than MapArray for updates, and other operations perform similarly.
- For collections with more than ~10_000-20_000 elements, MapArray is usually a small constant amount faster than ErlangArray.
EDIT: Added some graphs to this post.
Qqwy
Better Graphs
I did not like the graphs I constructed before very much: they are neither beautiful nor easy to understand, and took a lot of manual labour to create.
In these graphs, we compare the average running time (i.e., ‘lower is better’) of four common operation on sequential collections.

Concatenation of lists seems to be optimized to an extreme extent within the BEAM, because while this should be asymptotically slower, it blows all other implementations out of the water.
For larger collections, A.Vector is significantly faster than ErlangArray or MapArray. This is one operation in which ErlangArray is clearly better than MapArray (in most other operations, their performance is very similar).

Random access is a prime situation for which arrays are better suited than lists (once you have more than ~20 elements; below that, the JIT will be able to optimize the list-based solution to something incredibly fast).
This is another situation in which A.Vector is significantly faster than ErlangArray and MapArray, being just as fast as the builtin lists for small collections, and not really showing any signs of slowing down until having more than ~120_000 elements.
That said, the performance of MapArray and ErlangArray is by no means bad; up to arrays of ~30_000 elements, they are only a constant amount slower than A.Vector.

Updating a random element is another operation for which arrays are clearly more suitable than lists. As soon as you have more than ~20 elements, that is. Here, A.Vector actually is beaten by ErlangArray and MapArray (which perform similarly well), at least until your array has more than ~30_000 elements.

It’s clear that appending a single element to the tail of a list is a really bad idea. In some situations, pre pending an element to a list and then ‘interpreting it backwards’ is a possibility, although that will still not allow fast read/write access to any of the other elements in the collection (as seen above).
For appends, all three kinds of arrays (ErlangArray, MapArray and A.Vector) seem to behave similarly well. A.Vector slows down a little here once the ~10_000 element limit has been reached.
Which implementation should I use?
Benchmarks are nice, and from above benchmarks it seems that either A.Vector if reads are common and ErlangArray if writes/appends are somewhat more common might be a good rule of thumb.
But why choose based on general advice? The main fief of the Arrays library is that it is easy to switch out one array-implementation for another (by an app-wide config or an option passed to Arrays.new), so the better advice is to make your choice based on benchmarking your particular application! ![]()
I want to thank @sasajuric for his great article on sequences of december last year, and for publishing the source code to make the graphs in that article. (And also to @sabiwara for his help in this matter – hope you get around to writing that longer blogpost about A.Vector soon!)
What’s next?
I will probably be spending my spare time the next couple of weeks on some of the other Elixir libraries I’ve been working on (hint). After this, work on Arrays will continue. The roadmap is still to add support to more common array operations: swapping elements at two indices, sorting arrays, shuffling arrays, and maybe more if other common operations are identified.
I urge you to try out the library! It is very stable, well-tested and performant.
At some distant point in the future a v3.0 might be released if the Arrays.Protocol might be refined further to include more paths for optimization. This will be a breaking change for array-structure implementers but probably not for users of the library.
Cheers! ![]()
~Qqwy/Marten
Popular in Announcing










Other popular topics





Latest on Elixir Forum
Sponsor Spotlight

We build reliable cloud platforms for business-critical systems.
Categories:
Sub Categories:
Forums
Popular Tags
- #ecto
- #liveview
- #troubleshooting
- #learning-elixir
- #deployment
- #library
- #erlang
- #testing
- #genserver
- #mix
- #absinthe
- #remote-other
- #otp
- #plug
- #how-to-question
- #macros
- #postgres
- #channels
- #elixirconf
- #exunit
- #discussion
- #code-sync
- #javascript
- #podcasts
- #onsite
- #dialyzer
- #docker
- #authentication
- #umbrella
- #full-time-contract
- #podcasts-by-brainlid
- #ecto-query
- #elixir-ls
- #phoenix_html
- #iex
- #blog-post
- #graphql
- #genstage
- #ai
- #websockets
- #supervisor
- #advent-of-code
- #elixirconf-us
- #distillery
- #processes
- #forms
- #api
- #metaprogramming
- #security
- #performance
Our Sponsors

Build Elixir applications with speed and confidence.

Supporting innovation across the BEAM ecosystem.
We build reliable cloud platforms for business-critical systems.

Catch errors, track performance, monitor hosts and more.

Real-time error tracking, performance insights, and observability for devs.

Develop your skills with books, videos, and courses.

Producing high quality Elixir screencasts since 2017.

Enabling companies to succeed by building software people love.

Courses that'll move you from confusion to "Aha, now I get it!"