Better Graphs
I did not like the graphs I constructed before very much: they are neither beautiful nor easy to understand, and took a lot of manual labour to create.
In these graphs, we compare the average running time (i.e., ‘lower is better’) of four common operation on sequential collections.
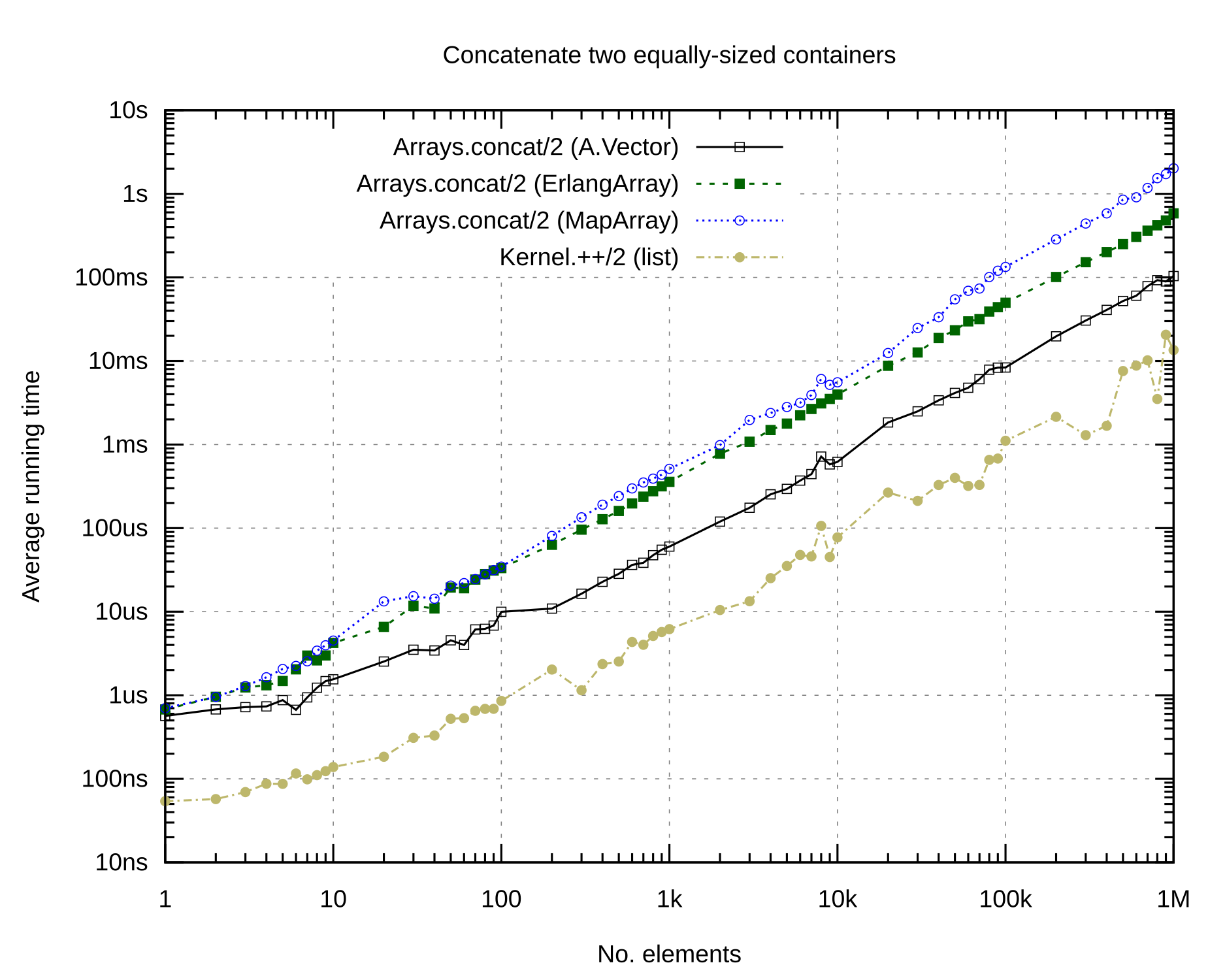
Concatenation of lists seems to be optimized to an extreme extent within the BEAM, because while this should be asymptotically slower, it blows all other implementations out of the water.
For larger collections, A.Vector is significantly faster than ErlangArray or MapArray. This is one operation in which ErlangArray is clearly better than MapArray (in most other operations, their performance is very similar).
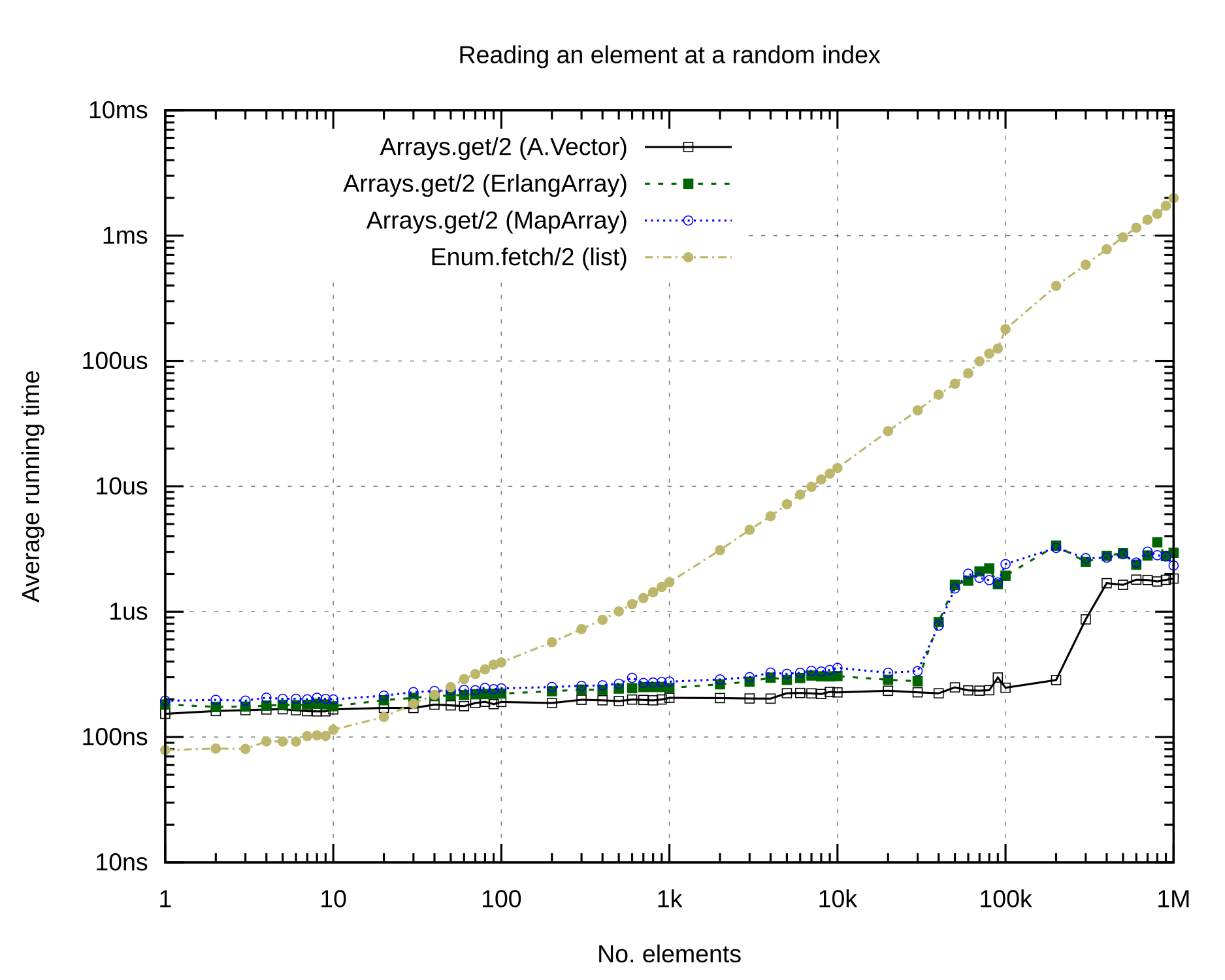
Random access is a prime situation for which arrays are better suited than lists (once you have more than ~20 elements; below that, the JIT will be able to optimize the list-based solution to something incredibly fast).
This is another situation in which A.Vector is significantly faster than ErlangArray and MapArray, being just as fast as the builtin lists for small collections, and not really showing any signs of slowing down until having more than ~120_000 elements.
That said, the performance of MapArray and ErlangArray is by no means bad; up to arrays of ~30_000 elements, they are only a constant amount slower than A.Vector.
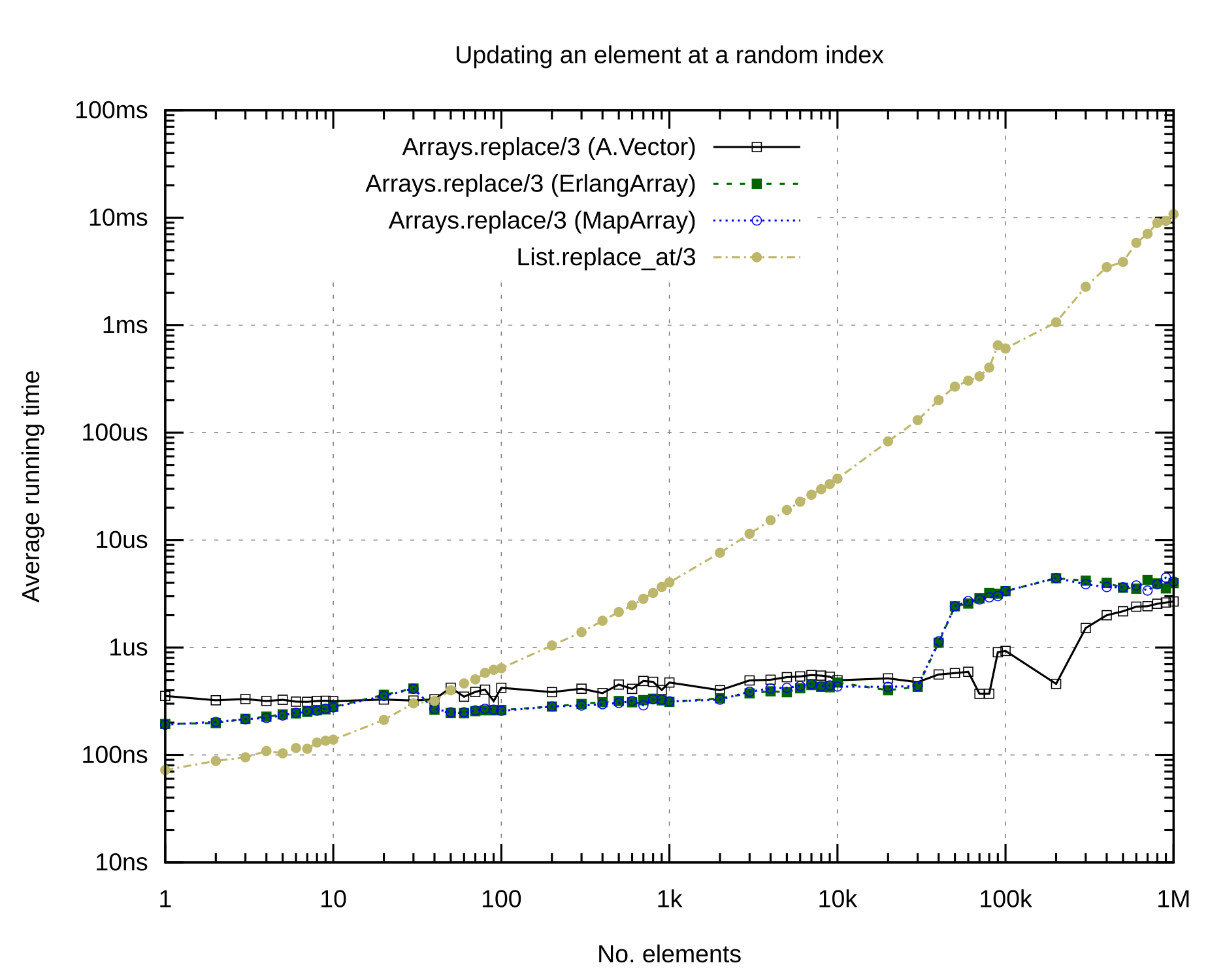
Updating a random element is another operation for which arrays are clearly more suitable than lists. As soon as you have more than ~20 elements, that is. Here, A.Vector actually is beaten by ErlangArray and MapArray (which perform similarly well), at least until your array has more than ~30_000 elements.
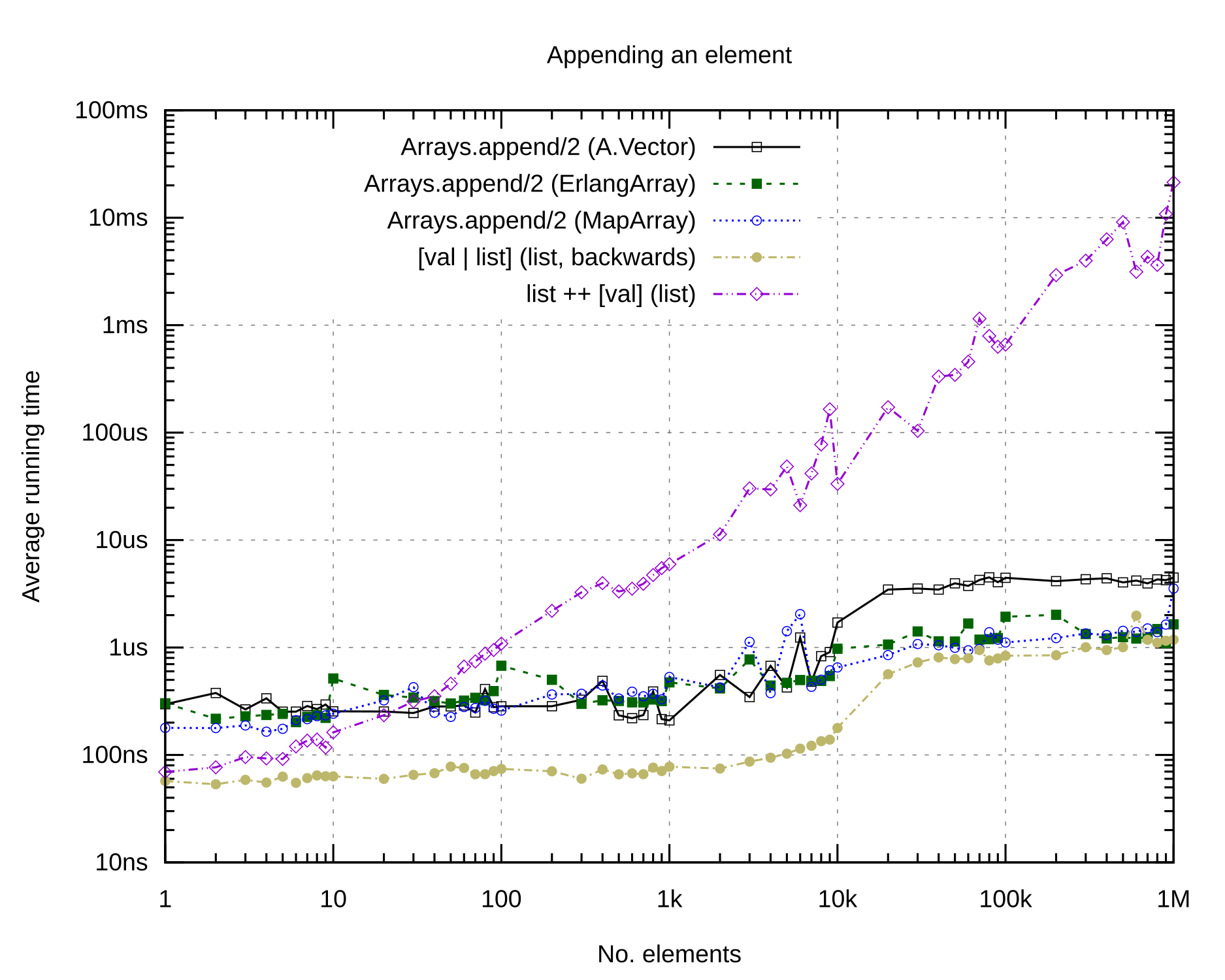
It’s clear that appending a single element to the tail of a list is a really bad idea. In some situations, pre pending an element to a list and then ‘interpreting it backwards’ is a possibility, although that will still not allow fast read/write access to any of the other elements in the collection (as seen above).
For appends, all three kinds of arrays (ErlangArray, MapArray and A.Vector) seem to behave similarly well. A.Vector slows down a little here once the ~10_000 element limit has been reached.
Which implementation should I use?
Benchmarks are nice, and from above benchmarks it seems that either A.Vector if reads are common and ErlangArray if writes/appends are somewhat more common might be a good rule of thumb.
But why choose based on general advice? The main fief of the Arrays library is that it is easy to switch out one array-implementation for another (by an app-wide config or an option passed to Arrays.new), so the better advice is to make your choice based on benchmarking your particular application! ![]()
I want to thank @sasajuric for his great article on sequences of december last year, and for publishing the source code to make the graphs in that article. (And also to @sabiwara for his help in this matter – hope you get around to writing that longer blogpost about A.Vector soon!)
What’s next?
I will probably be spending my spare time the next couple of weeks on some of the other Elixir libraries I’ve been working on (hint). After this, work on Arrays will continue. The roadmap is still to add support to more common array operations: swapping elements at two indices, sorting arrays, shuffling arrays, and maybe more if other common operations are identified.
I urge you to try out the library! It is very stable, well-tested and performant.
At some distant point in the future a v3.0 might be released if the Arrays.Protocol might be refined further to include more paths for optimization. This will be a breaking change for array-structure implementers but probably not for users of the library.
Cheers! ![]()
~Qqwy/Marten




















