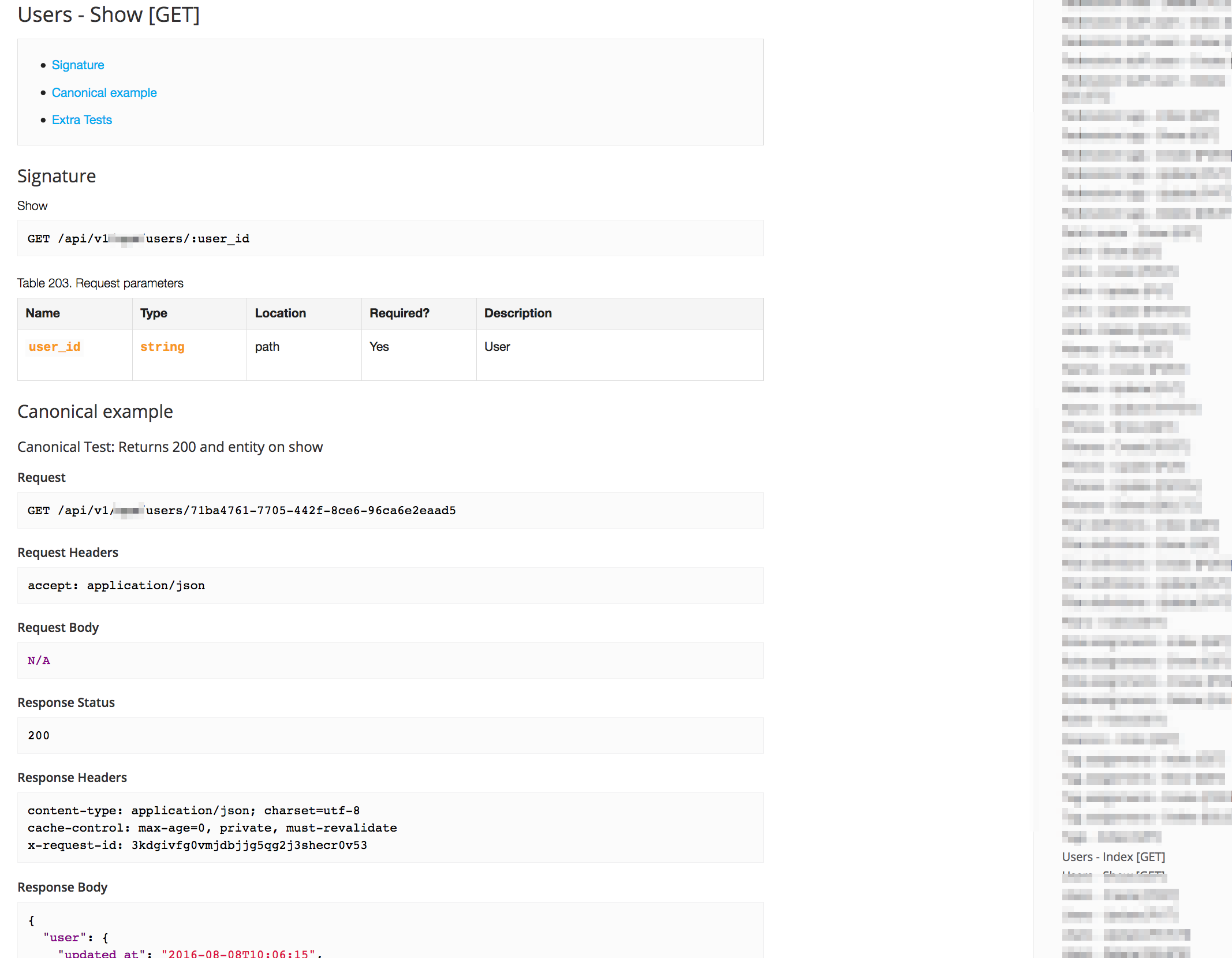
Maintaining API docs can be a real pain, and a lot of people overlook them, especially when it is purely an internally-used service.
I’ve discovered a few nice tools that generate pretty docs based on markdown files, but I haven’t found anything that automates the process of maintaining the actually content.
I was thinking about how to do this, and I think it would be really cool if there was some sort of DSL or library for automating JSON API docs via integration tests on your controllers.
For example, you might have a test like this that creates a new blog post:
test "create a post" do
assert %{
"title" => "My first post",
"body" => "Some content...",
"inserted_at" => _,
"updated_at" => _
} =
build_conn()
|> post("/posts", title: "My first post", body: "Some content...")
|> json_response(:created)
end
And then some mix task would automatically generate documentation based on your tests.
Does anyone know if something like this already exists?
If it doesn’t already exist (and isn’t impossible for some reason), here’s one way I can think something like this might be implementable:
Provide some simple functions to document requests and responses:
test "create a post" do
request = post(build_conn(), title: "My first post", body: "Some content...")
response = json_response(request, :created)
document(request, response)
assert # something
end
I’d imagine you could simplify that to something more like this:
test "create a post" do
assert %{
"title" => "My first post",
"body" => "Some content...",
"inserted_at" => _,
"updated_at" => _
} =
build_conn()
|> post("/posts", title: "My first post", body: "Some content...")
|> json_response(:created)
|> document()
end
These functions might do nothing when just running mix test, but would build some universal documentation output (Markdown or something) when you run MIX_ENV=test mix apidocs.
Have you heard of Swagger? I saw this post post a few days ago an it seems that it uses a json specification to document you endpoints. I don’t seem too hard to automate this json file generation, but I dont know if this would be a nice option
These look better, but you still have to maintain this manually. Defining the schemas, for example, comes really close to repeating code that is already in your views (it’s just different enough that you can’t re-use view functions). If I made a change to a view, I’d have to remember to make the subsequent change the my swagger schema definition.
I still maintain that generating docs from your tests would be valuable. Every request or response you would see documented would therefore have been guaranteed to run through a test. It would be nearly impossible to have bad documentation, because your tests would then be failing.
Hey @pdilyard, I have implemented this, currently working on making it non-$project-specific and releasing an open source library. We have reached the full automation, including CI checks (e.g. you can’t push any code through that isn’t inline with the documentation) and auto-deployment of the docs page itself (on a free heroku node BTW).
I’ll let you know when I have a public repo if you’re interested. Hoping to release it early next year.
^ Apidocsjs works very well for my use cases with Elixir. I created a simple phoenix app that gets called by a github webhook whenever a pull request is merged to develop and auto updates the apidoc js output documentation which is hosted on S3. The same app then acts as a reverse proxy to the S3 resources with auth in front of them.
We use phoenix_swagger to generate a swagger spec, then bureaucrat with a custom markdown formatter similar to this to merge the swagger spec and the test examples into markdown.
Finally process the markdown with a static site generator, and put the results back into the priv/static directory of the Phoenix app for self hosted docs.
swagger and apidocs are very different animals IMO.
Swagger is designed to be interactive API explorer. There is limited support for sample runs (curl session recordings). For example, there is no way to record multiple samples for the same return code and “produces” type. I, API consumer, prefer (at least initially) to see samples without executing anything. Schema is nice but it is not simple to construct samples in my head quickly.
Am I the only one that thinks the JSONAPI spec is way over-engineered and inefficient both? I’m not sure why GraphQL would not be used as it seems to do everything JSONAPI does but significantly better, especially with introspection and API documentation generation?
I like the way JSON:API standarizes the API for filter, sort and page.
Is the GraphQL equivalent to use parameterized fields with many optional arguments?
Indeed. Most folks are using the Relay connection pattern for paginated fields, and you can put whatever arguments on there you like. They can be optional for some fields, required for others, and it’s all self documented by the same schema that actually runs everything.