
Relrin
Building a pipeline processing with GenStage
Hi everyone,
I’m wondering about building a pipeline with GenStage and RabbitMQ queues for processing data about the players which are searching for a game with similar skill (or rating) for one of my open source project, but slightly stuck on the design phase. The basic idea it’s pretty straightforward:
-
Client put a message into the certain message queue as the request for search a game for him. In any of those messages will be specified
reply_tothat will be using in the last stage for getting understanding where to left the final response. -
And here starting the most interest part of the whole topic: a processing a data about the players. From the some point of view it is none trivial task, but I’ve tried to solve it with the following way:
2.1. The client’s message from the first step is writting into the “generic queue” which is storing all requests for searching a game with opponents.
2.2. The publisher/consumer workers is consuming a message, sending a request to the database for getting an additional information about the player and put the message into the next queue, depends on the rating or skill of the player.
2.3. The next group of publishers/consumers are consuming messages only from the certain queue and processing them (for example a group of workers that processing the players only with an average skill):
2.3.1 Because each worker is linked to the specific queue, it will extract message in sequence and try to analyze it. If the player, the information about which was specified in the message body, is according to the matchmaking algorithm, then the selected player will be saved in the memory of the worker and the extracted message deleted. This process is repeating until the worker have not enough players to fill the game lobby. And when it will completed, a list of players will be transferred as a message to the next queue.
2.3.2 Otherwise the message will be published the special queue, created for requeuing players into generic queue.
2.3.3 Special type of workers are re-publishing messages to the generic queue, which are coming from the publishing node from the 2.3.2 step.
2.3.4. A worker is extracting the published message on the previous step, and creating a new game server (or choosing one from the already existing). After that it will broadcast the server IP-address, port and connection credentials to each player mentioned in the list via particular response queues, that were specified by clients in the first step.
2.3.5 Each client is getting the response from response queue and connecting to the game.
The same thing but demonstrated with the picture:
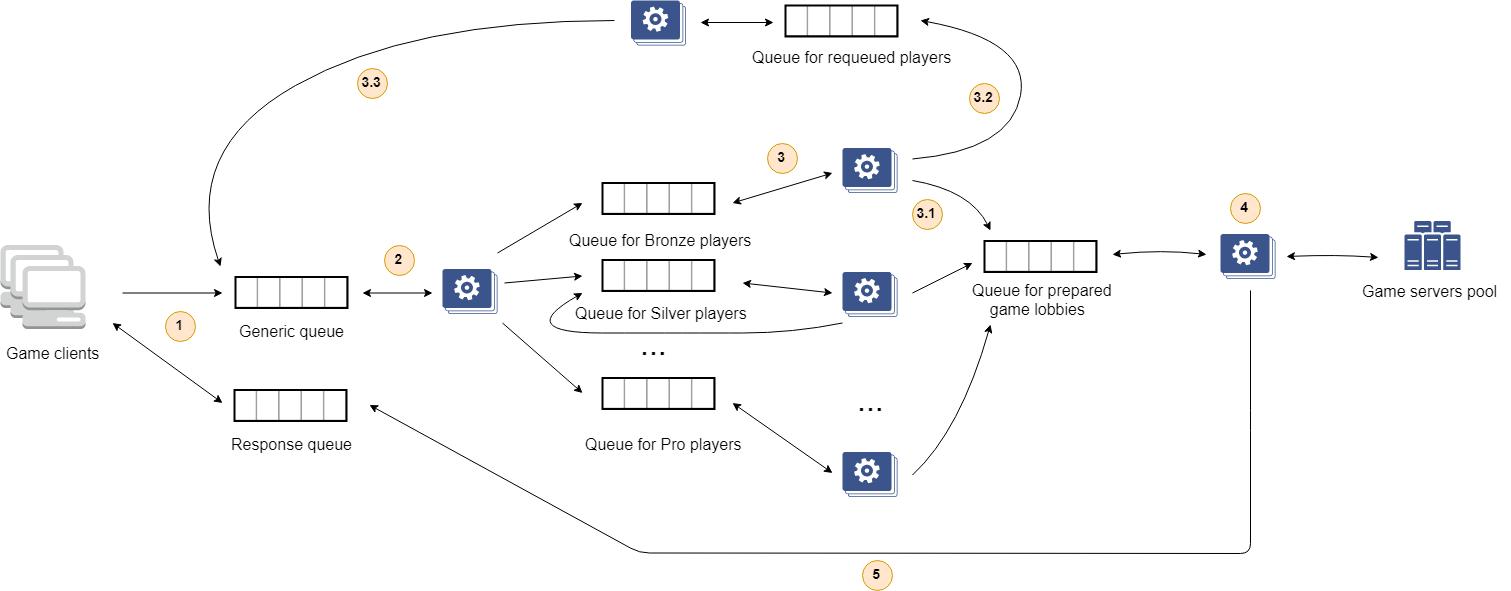
- After when the processing will be done, the worker will extract the response and send it to the certain response queue (that was specified on the first step).
and I have a couple questions, that still raising while I’m designing it:
- Does it a good idea to build this up? Or better to go an another way, when it will be splited up onto small applications?
- It will be great to scale it up when will be necessary in runtime, because we actually don’t know how many requests will come for processing concurrently. Hovewer, it will be good to configure and use a backpressure of GenStage? Or it will be an overkill?
- How to deal with a case when necessary to store a list of players in the workers while collecting players into one group before putting them into one game lobby?
First Post!
amnu3387
It’s not like I developed a lot (or any for that matter) production ready processing queues, but I’m currently building one and my approach to it was a bit simpler I think, although at the same time I don’t know your constraints nor needs - perhaps genstage and several different queues is the way to go for you.
I’m not really answering your questions, just going to share the way I went about it, perhaps it gives you some idea.
I basically opted to have two types of ETS tables (actually there are a bit more but related to other parts),
one which holds the player info in a form such as:
{"player_id", data ... }
which basically is used to verify quickly if a user can or not join a queue, start a game, etc. You look it up with the player ID and then pattern match the tuple & contents to figure out if a player is already playing/has any restraint/etc.
And another ETS table for each type of “tournament” available. So for sake of illustrating this lets say there’s only one tournament type which has 3 matches length - this ETS table will have a few entries with each describing its own record track as the key (if there were more tournament types then there will be more ETS tables, one per each tournament type ofc):
{ "000", [ ] }
{ "w00", [ ] }
{ "l00", [ ] }
{ "wl0", [ ] }
{ "ww0", [ ] }
{ "ll0", [ ] }
With 3 matches length these are all possible track records for matching. When I mention “record” it’s about these “record” tracks and not a record in terms of data structure. The list in the 2nd term is actually the “queue”. Each character on the ETS “key” represents the result of the match, with 0 being not played, w won and l lost. The order of the won & lost doesn’t matter for queuing, so "wl0" is equal to "lw0" hence only "wl0" is used. This is built by an algorithm that takes the number of matches you want to play and produces all the possible relevant results, creating an ETS table where each entry is a record track. This particular one is created on app startup because these tournaments will always be up. Others could be created dynamically at runtime. They can also hold more information if needed.
Now when a user asks to join the play queue he has his own record track. For instance if he hasn’t played any match it will be "000". If he has played two and won both it will be "ww0". If he has played two and lost one and won another it will be "wl0" (because the record string is sorted in order it will always be w’s first, then l’s then 0’s - of course)
The request to join is cast to a genserver which basically just queries the relevant ETS table, looking up the track record that matches this player’s record track, so for instance it gets the record with key "000" in case the player hasn’t played yet any match. If there’s any player in the queue and they can duel each other then the game starts (there are some other details like you can cancel and be requeued, etc)
This genserver handles this activity asynchronously and then itself calls a supervisor to start an individual game genserver for the two matched players that actually handles the game creation and players “negotiation”/“acceptance” to start, update the ets table holding the player “status”, broadcast etc, so it shouldn’t be a bottle neck. The only thing it does is, effectively, looking up an ets table and going through the list in that record (which I expect to never really grow more than 3 or 4 items).
Nonetheless, if it becomes a bottleneck then it can be made so that instead of a single genserver handling all queue requests, it’s instead a genserver per “record track”. So basically a genserver will handle requests to join the record track of "000", other "w00", etc. Since it’s already using the “record” track system, it’s easy to send these requests to their respective genserver as well in case it moves in that direction but I’m not worrying about it rigth now
In this approach a player only ever gets enqueued if there’s no available opponent already waiting, or if the ones that are can’t play against him (they already played against each other this tournament). Otherwise he doesn’t even “get” in the queue. I think this is the easiest way to model it that creates less edge cases but I might be wrong.
There’s one last details which is a send_after message, that gets “scheduled” when a user is enqueued (meaning there wasn’t any available opponent), and basically contains the id of the player and the record track in which they got enqueued. In case it reaches that “time waiting” it will try to find an available opponent in the record tracks above and below the players one (so a player with 2 wins might get matched against a player with 1 win or 1 loss - but not against one player with 2 losses).
When a player is matched in any way their timer is cancelled and basically that’s it.
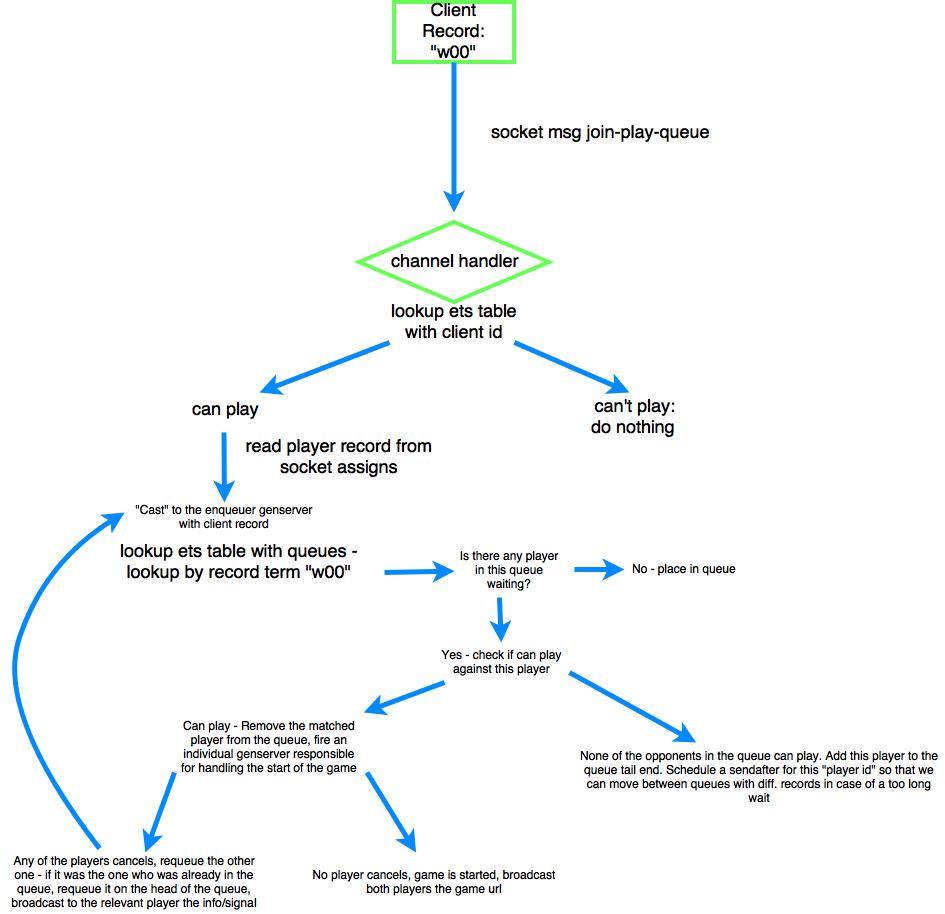
Hope you can get anything useful out of it, gl!
Popular in Questions





Other popular topics









Latest on Elixir Forum
Sponsor Spotlight

Enabling companies to succeed by building software people love.
Categories:
Sub Categories:
Forums
Popular Tags
- #ecto
- #liveview
- #troubleshooting
- #learning-elixir
- #deployment
- #library
- #erlang
- #testing
- #genserver
- #mix
- #absinthe
- #remote-other
- #otp
- #plug
- #how-to-question
- #macros
- #postgres
- #channels
- #elixirconf
- #exunit
- #discussion
- #code-sync
- #javascript
- #podcasts
- #onsite
- #dialyzer
- #docker
- #authentication
- #umbrella
- #full-time-contract
- #podcasts-by-brainlid
- #ecto-query
- #elixir-ls
- #phoenix_html
- #iex
- #blog-post
- #graphql
- #genstage
- #ai
- #websockets
- #supervisor
- #advent-of-code
- #elixirconf-us
- #distillery
- #processes
- #forms
- #api
- #metaprogramming
- #security
- #performance
Our Sponsors

Build Elixir applications with speed and confidence.

Supporting innovation across the BEAM ecosystem.

We build reliable cloud platforms for business-critical systems.

Catch errors, track performance, monitor hosts and more.

Error tracking for Elixir devs who love to ship. Start your free account.

Develop your skills with books, videos, and courses.

Producing high quality Elixir screencasts since 2017.
Enabling companies to succeed by building software people love.

The team behind Membrane, Popcorn, LiveDebugger. Available for hire.

Courses that'll move you from confusion to "Aha, now I get it!"