I should note however that even Programming Phoenix ≥ 1.4 still advocates this implementation of “Phoenix MVC”:
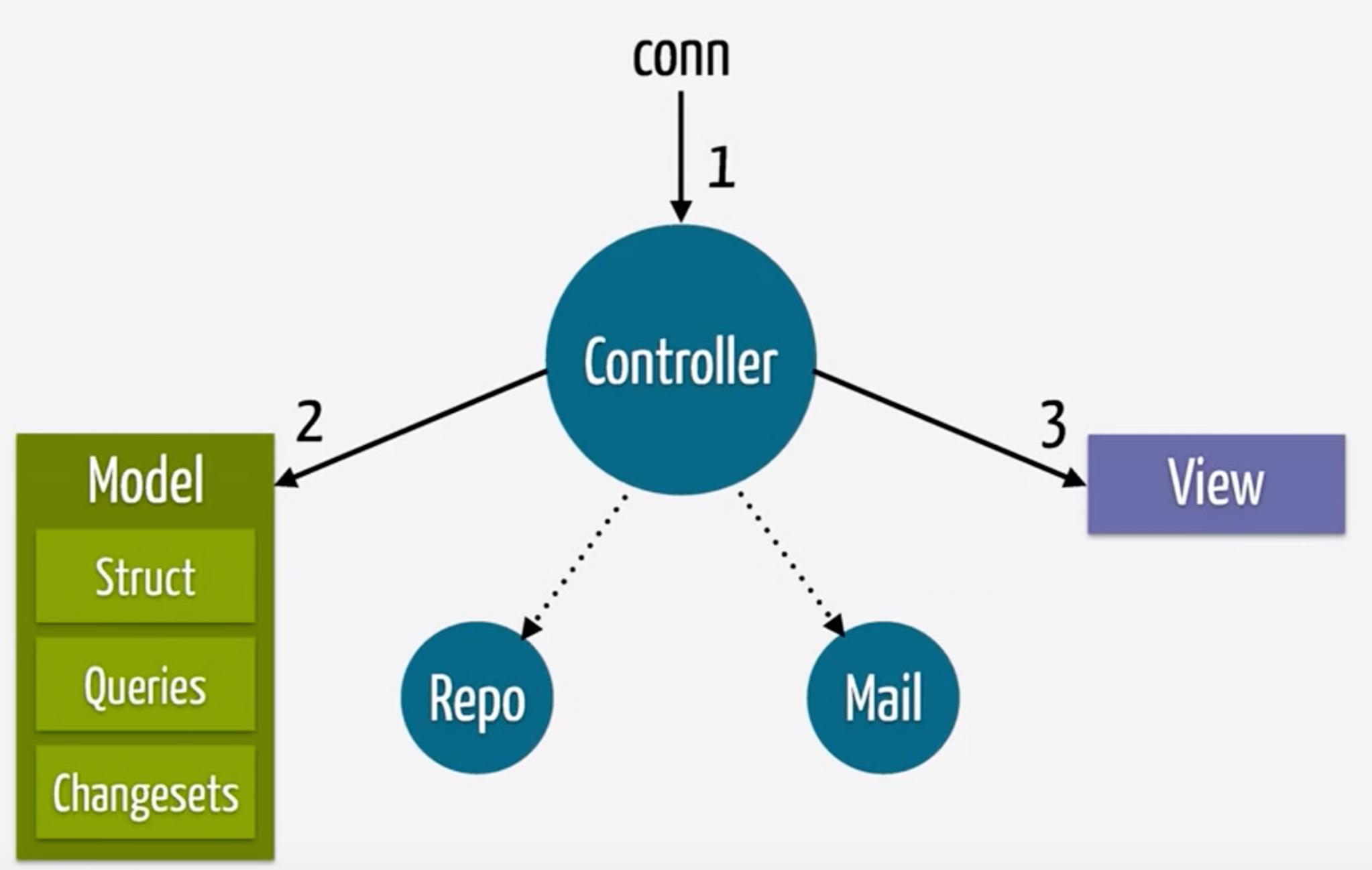
The “model” is the collection of persisted data types, the associated queries, and changesets - but without Repo access. This is justified by striving to keep everything inside the “model” free from side effects, leaving it ultimately up to the controller to effect changes in persisted state by pushing the built-up changesets into the appropriate Repo functions.
This is in contrast to the typical understanding of a bounded context which puts a boundary around its internal types (and associated transformations usually implemented in a persistence-ignorant manner with direct access to/on top of a Repository)
(Edit: some of the Programming Phoenix ≥ 1.4 code actually looks less like the above graphic as context functions will access the Ecto repo themselves - in which case side effects are accepted in order to keep implementation details out of the controller)
“Phoenix MVC” is the basis of Dave Thomas’s claim that:
first 1.2 and then 1.3 actually tightened the coupling between the two.
[i.e. Phoenix and Ecto] - making a case for removing the database (and Ecto) entirely out of Phoenix and using them inside a separate OTP component (OTP application) which exposes an API to which Phoenix connects.