Is there any specialized packages or official documentation addressing deployment to AWS Elastic Beanstalk ? Possibly also using also AWS CodePipeline to build from a GitHub repository branch.
What is the best way to do that?
Thank you ![]()
Is there any specialized packages or official documentation addressing deployment to AWS Elastic Beanstalk ? Possibly also using also AWS CodePipeline to build from a GitHub repository branch.
What is the best way to do that?
Thank you ![]()
I would probably suggest Kubernetes.
You can setup a pipeline that will push your Docker build to building pipeline (I don’t know the name for AWS as I use GCP) and then roll out to all pods.
Clustering is quite easy this way as well.
Thank you. As for Kubernetes, is they any packages or official documentation on this topic?
I don’t have to use AWS Elastic Beanstalk. I can possibly use Kubernetes on another hosting provider. What I am looking for is auto scaling based on load (web application).
Just a few sources:
https://medium.com/@chargio/creating-a-simple-elixir-phoenix-application-to-deploy-in-kubernetes-2eff2c8e367c
I don’t know of any official documentation specifically for Elixir, but I’d use Docker to deploy on Beanstalk. You can use the mix phx.gen.release --docker task to generate a suitable Dockerfile and then follow the official AWS documentation to deploy a Docker image to beanstalk. I’m sure AWS also has docs and guides to automate this with CodePipeline.
@Blond11516 thank you! One more minor question, how do you deploy and redeploy code changes? Do you do a git pull inside Dockerfile?
Do you do a
git pullinsideDockerfile?
No, that’s not really how Docker containers work. The basic idea is that you, as the application developer, write a Dockerfile which describes how to build, configure and start your application. You then use this Dockerfile to build a Docker image (through the docker build command). This image is a bit like a small virtual machine with your application and its dependencies baked in. Finally, you push your image to some repository and ask your cloud provider to deploy this image to a server.
The goal behind this is that images provide a reproducible deployment environment that is built from scratch every time. This means you can take your image and deploy it as many times as you want, on any server you want from any provider you want and it should work the same every single time. This is in contradiction to VPS-based deployments, where you have a single server that you configure manually and push updates to, which often ends up with the server holding all sorts of hidden dependencies and configurations that can be extremely hard to reproduce if you ever need to migrate or scale to another server.
Now, because we want reproducible builds from scratch, updating the application usually means building a whole new image with our updated code and deploying that new image to replace the old one. The exact way to do this will depend on the service you’re using to host your app.
With all that said, I’d recommend you avoid deploying to AWS if you can. AWS is a very complex system that’s more tailored to bigger teams or experienced developers who want fine-grained control over their infrastructure. Because of that, their documentation is honestly pretty hard to follow if you don’t already kind of know what you’re doing.
I’d recommend looking at smaller infrastructure providers with more focused and beginner-friendly offerings. fly.io is very popular in the elixir community for very good reason imo. They have a dedicated guide for Elixir (although the deployment process is basically the same as with any other stack) and it lets you deploy and update an app with just a couple of commands.
Thank you. I have spent some time in the meantime to learn more about Docker. Actually I have deployed my first small application using Docker on a Kubernetes cluster on Linode! Looks great. Seems that it is easier and cheaper to do that using Linode. I will surely check out your suggestions. What is important for me is the auto scaling features of either Kubernetes or AWS Elastic Beanstalk,
Deploying to Elastic Beanstalk is fairly easy (probably the easiest method to deploy something on AWS). As mentioned previously; you can have a Docker image set up and do the rest from the CLI. You can also run the Beanstalk CLI to trigger the build (like you would do from your machine) from your CI on code changes (after a PR gets merged, etc).
However, I must say that If you are going the Elastic Beanstalk route be aware that you are in for a world of pain™️ if you have to deal with distribution down the line - at least if you intend to use any of the standard libcluster strategies (IIRC, EB does not support exposing multiple ports when you use Docker).
Also, If you are using automatic autoscaling and you have shared state for stuff like authentication (using ETS for instance), you might get all sorts of problems because the autoscaled instances are not aware of each other.
PS.: I think the DNS cluster strategy or the Postgres cluster strategy could help with that, but I honestly haven’t tested it on EB yet.
Thank you. How would you deal with that ? Simply using Kubernetes instead of AWS Elastic Beanstalk?
I advise you to try creating a cluster with the new strategies for autoscaled instances (links in my previous reply) and see if that is going to work. If everything works, keep using EB; it’s a lot less work than setting up K8s overall (I mean if you don’t need to).
Mainly, I am interested in creating a cluster (in EB or K8s) which auto scales (vertically) based on demand. But i find you comments interesting with regard to sharing states using either DNS cluster strategy or Postgres cluster strategy.
I have read in the topic and all examples I see display in UI the number of nodes connected. That is fine but I am looking for real life use cases. When would sharing data between nodes becomes significant ? Would be happy to learn more about real life use cases and examples. Thank you.
Ok, I’m going to give you an example… I first noticed this problem with EB in a project that uses the Pow Auth library. Pow uses ETS to cache user credentials when you log in, so while using EB, if nodes are not in a cluster what happens is that the request comes through the load balancer to a given node, this node tries to auth the user, and it successfully does so, after that it tries to redirect the authenticated user to the app; when the redirect happens, the requests goes through the load balancer again and it might end up hitting another node that might not have the credentials cached in ETS. When this happens, the node (which doesn’t have information about the credentials) is going to negate the auth attempt and redirect the user again, and the whole thing starts over from the load balancer requesting the autoscaled nodes in an infinite cycle of auth attempts and redirects. What you want to solve this is using a distributed store like Mnesia and making the nodes talk to each other so they can share the cached information.
@thiagomajesk I just wanted to share this with you and community. There is a small library that can be used to to run Mnesia inside Kubernetes. I have already implemented it and yes the pods are sharing a Mnesia database.
Out of curiosity, why do you want auto-scaling? In my experience it’s rarely actually needed, even for many medium to large scale apps. If cost is a concern, the time you spend building and managing auto-scaling will often far outweigh the cost of 1 or 2 small to medium servers running unnecessarily.
Also, are you sure you want vertical (more powerful machiness) autoscaling? I’ve only ever heard of autoscaling horizontally (running more machines).
I am looking for horizontal (sorry I made a mistake earlier), yes by adding machines. As for your thoughts, I agree, but thought it would be nice to be in the safe side. As for now, by now ![]() I have managed to set things up both on AWS and Kubernetes at Linode. So, the tools are ready to be implemented in a project of mine in near future. Thank you.
I have managed to set things up both on AWS and Kubernetes at Linode. So, the tools are ready to be implemented in a project of mine in near future. Thank you.
I will be using JWT authentication, so I guess there will be no issues due to lack of a shared state between the instances. Any shared data, I will simply put inside a SQL database accessible by all instances.
EB does support exposing multiple ports, here is an example using nginx …
docker-compose.yml
nginx:
image: nginx:alpine
platform: ${__PLATFORM__}
restart: always
ports:
- 80:80
- 7070:7070
depends_on:
- api
volumes:
- public_assets:/app/public
- ./nginx.conf:/etc/nginx/conf.d/default.conf
nginx.conf should have of course two server definitions: one listening on port 80 and one on port 7070.
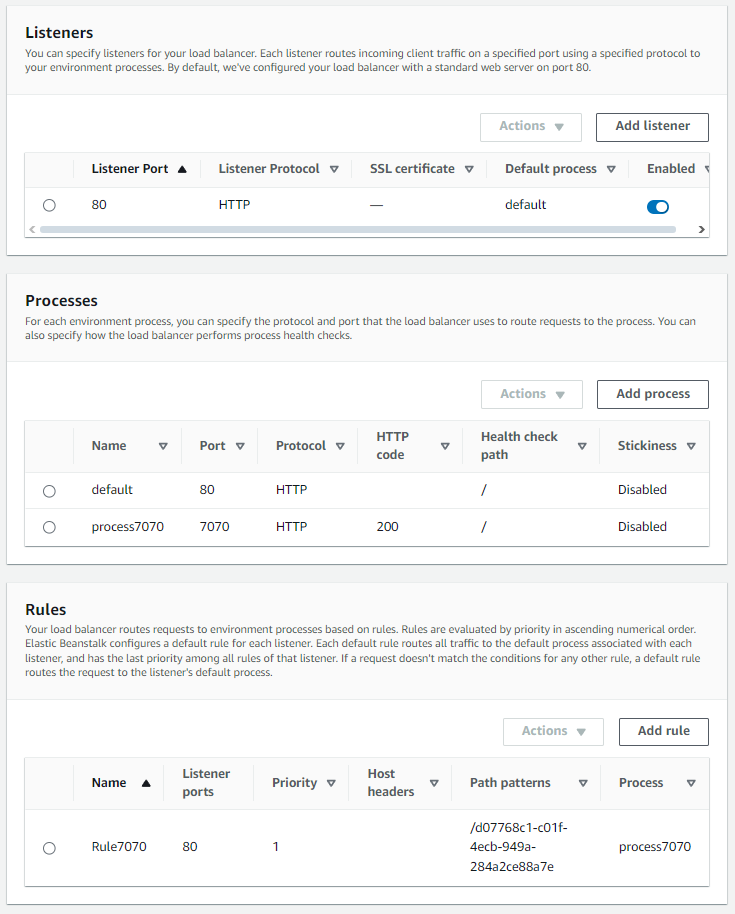
And if access is needed from external internet to those two nginx processes, this can be done by configuring the processes and rules of the elastic load balancer, here is an example, path-based [can be also host-based]:
That been said, I still have no idea how this can help in creating a shared environment for multiple Phoenix applications running in multiple EC2 instances within the auto-scale EB environment. I guess, maybe, since they all run in same local subnet (VPC), maybe, create another small instance (not related to EB) and that all others subscribe to it via Mnesia by their private IP addresses on the local subnet? And thus share some common store …
Hi! I haven’t touched EB in quite a while, so good to know this is supported now… I remember getting in touch with AWS support back in the day and this was a platform limitation at the time (although documentation said otherwise).
Using this:
Can be an easier solution to connect the different instances, instead of using for example DNS strategy. What do you think?





















© Copyright Elixir Forum | Terms | Privacy & Cookies