Yes its always the same domains. Ok, I will re-enable those for sure then.
Here is my Dockerfile (i’m just putting it anyway just in case it helps debugging). Thanks, good point. Maybe I can just add a temporary line where I add apk --no-cache --update add net-tools iproute2 and comment it out when I’m not using it
# https://github.com/GoogleCloudPlatform/community/blob/master/tutorials/elixir-phoenix-on-kubernetes-google-container-engine/Dockerfile
# REPLACE_OS_VARS is used only for POD_IP passed in from GKE yaml
FROM elixir:1.7.4-alpine
ARG APP_NAME=appname
ARG PHOENIX_SUBDIR=.
ENV MIX_ENV=prod \
REPLACE_OS_VARS=true \
TERM=xterm
WORKDIR /opt/app
RUN apk update \
&& apk --no-cache --update add git \
&& mix local.rebar --force \
&& mix local.hex --force
COPY . .
RUN mix do deps.get, deps.compile, compile
RUN mix release --env=prod --verbose \
&& mv _build/prod/rel/${APP_NAME} /opt/release \
&& mv /opt/release/bin/${APP_NAME} /opt/release/bin/start_server
FROM alpine:latest
RUN apk update \
&& apk --no-cache --update add bash openssl-dev
ENV PORT=8080 \
REPLACE_OS_VARS=true \
MIX_ENV=prod
WORKDIR /opt/app
EXPOSE ${PORT}
COPY --from=0 /opt/release .
CMD ["/opt/app/bin/start_server", "foreground"]
You don’t necessarily need to deploy outside K8s, just find a way to disable k8s DNS lookups from those specific pods. That’s achieved by making sure that the resolv.conf file that ends up in each pod is just using a normal DNS server instead of your pod local one. I don’t recall how to configure that off the top of my head though sorry.
You don’t need to create new images just for debugging, what I suggest is connecting to an existing image and installing the packages for debugging there.
ok, did you try to test the API you are calling? Is it possible that they are not able to handle the load you are putting on them? I would use some outside tool like ab for example to verify that you are not getting the same timeouts.
a) they can handle millions of requests a second (they’re data APIs)
b) if it were the API then simply multiplying the number of running apps on a single node wouldnt get wildly improved results
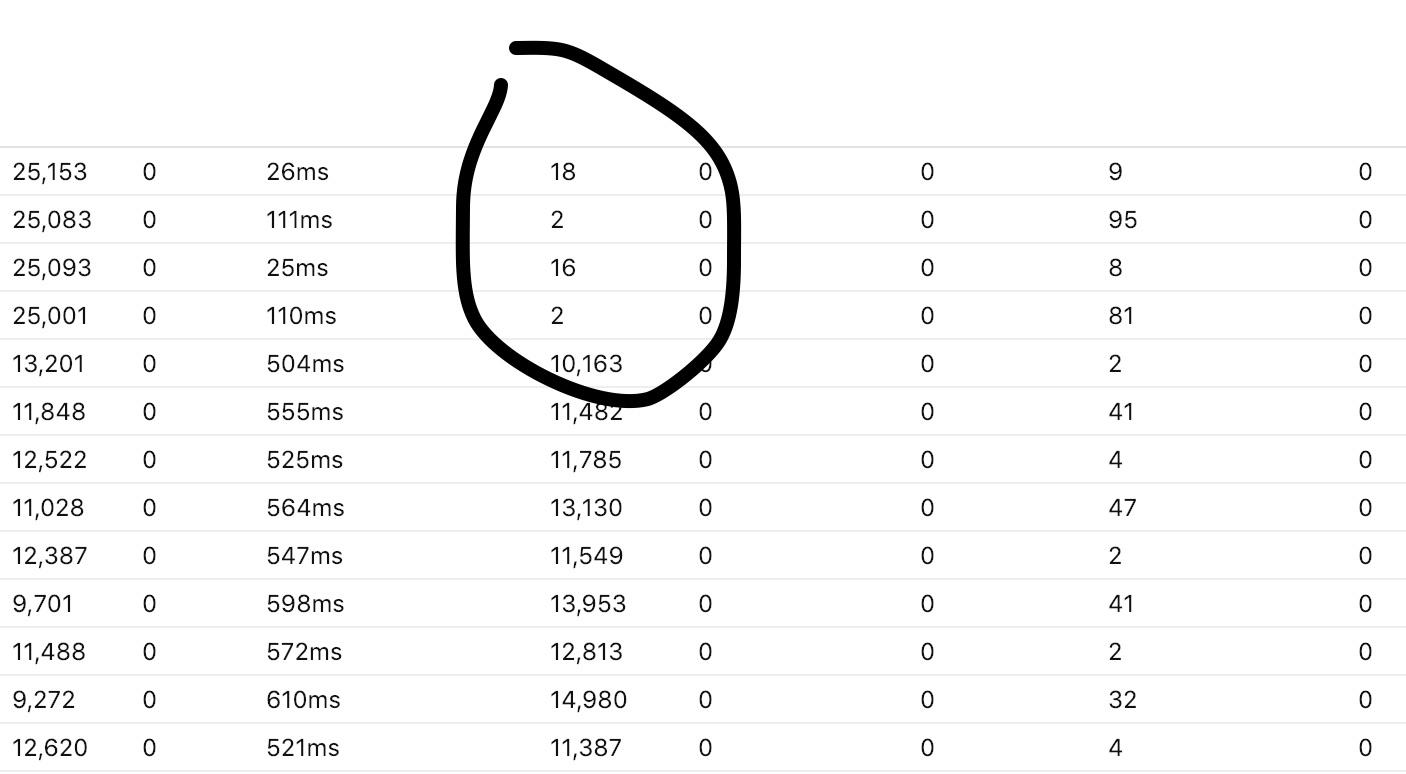
I will try. I just realized that Tesla uses a pool by default even though hackney by default doesn’t use a pool.
So this entire time its been using a pool which has thrown off my mental model. Now that I know it IS using a pool and failing, I decided to test the pool settings.
The default connections is 50 with a timeout of 15 second I believe… I tried setting it to 200 with a timeout of 1 second.
You can see a pool def helped. I suppose ill try to see the max pool i can get on a single app instance. When I did this before I remember getting decreasing performance past a certain number, I thought it was 200 or so.
If this is for the filesystem IO I believe my app hardly uses the disk if that matters. In the google cloud the disk IO is several MB with like 20-100 operations a second