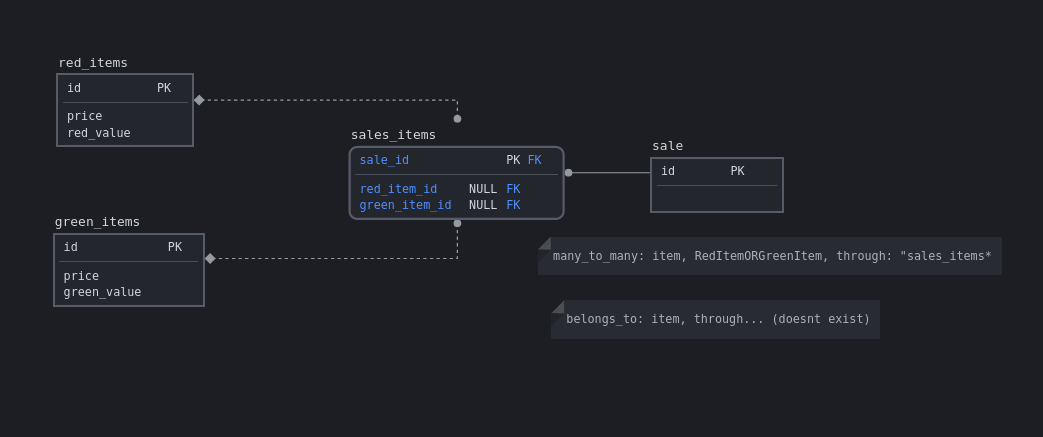
Ecto associations are designed to have one schema on the other end, not many, so defining an items relationship like you’re hoping for would be very difficult.
A single table with kind could work; you’ll encounter the usual worries about “are there too many NULLs in this table’s rows?” but entirely possible.
Alternatively, consider splitting the “has-a-price” (or maybe it’s “can-be-a-sales-item”?) concept apart from the “has-a-red_value” and “has-a-green_value” concepts; sales_items would refer to the generic part, which then has_one :red_details and has_one :green_details. Besides price, the generic table might contain additional information that’s applicable to all items (like a display name, or a preview image).
The intent would be that code that’s not specifically concerned with red-ness or green-ness could manipulate a sale without needing to worry about those details.
It’s sqldbm.com. I am only using the free parts, and basically only for “loose modeling”, none of the constraint/etc stuff.
It fits my need pretty well though. It’s not strict about specifying types unless you want to, you can use “fake types” (any string) too which is handy (“kind: red | green”). I found a lot of DB design stuff is too … DB orientated… asks too much from me when Im just sketching a few relationships and attributes. Same with most UML creators, too cumbersome and slow to add fields, etc.
Also it doesn’t actively try to look like garbage which is a plus.
Hmm, I hadn’t thought of that particular split. I actually had the RedItemSale and GreenItemSale, but it was becoming really cumbersome, moreso down the chain, below the “sales api”. I was experimenting with multiple schemas pointing to the one table, which does work but the nulls scratch at the back of my brain, even with custom constraints to check them - not that the join table doen’t end up with nulls anyway.
You can write an ecto query to return the types manually, can’t speak to the performance implications, etc.
from(si in "sales_items", where: si.sale_id == ^sale_id,
join: sale in Sale, on: sale.id == si.sale_id,
full_join: red_item in RedItem, on: red_item.id == si.red_item_id,
full_join: green_item in GreenItem, on: si.green_item_id == green_item.id,
select: {sale, red_item, green_item})
|> Repo.all()
#=> {Sale, RedItem or nil, GreenItem or nil}
You could wrap this somewhere, get_item_for_sale(%Sale{}) :: red_or_green.
I think you would have to manually manage the “sales_items” table, inserting the “join data” on sale creation. (I guess you could wrap it in a schema, I didn’t try. If you have a schema for it though then you don’t need to write the query, just check for nils in belongs_to relationships) but you can’t use build_assoc etc to do it “for free”, afaik.
I ended up going with a more simplified table layout, thinking it would be ok in my small set,
sales (Sale struct)
has_one: item
items (maps to both RedItem and GreenItem structs which set/enforce the kind attr)
field :kind, "red || green"
but in the end, I think this is marginally harder to use than the normalized tables, because you can’t use the query outlined in the post above.
You have to do something like:
k_red = RedItem.kind()
k_green = GreenItem.kind()
# assuming you're asking for a sale and its item, where you
# do not know the item type
from(sale in Sale
where: sale.id == ^sale_id,
full_join: red_item in RedItem, on: sale.item_id == red_item.id,
full_join: green_item in GreenItem, on sale.item_id == green_item.id,
# cant match on kind because both items have a kind field
# and matching against the wrong thing destroys the join
# where: red_item.kind == ^k_red, # makes no row match
# where: green_item.kind == ^k_green, # makes no row match
select: {sale, red_item, green_item})
|> Repo.one()
|> case do
{sale, %RedItem{kind: ^k_red} = red, _} -> {sale, red}
{sale, _, %GreenItem{kind: ^k_green} = green} -> {sale, green}
end
Final puzzle piece; is it possible to preload data for those joined types? I can only get it to preload data from the main “from” either directly or nested, but in this case item_id is a Item, so I can’t preload the correct Red/GreenItem via that.
I`ve tried any number of combinations of tuples, keyword lists, using the pipe-with-bindeng or keyword syntax, etc.
I guess I could add another-another join and select that data out, then do my own put_assoc post query. I think what I am trying to do is pushing SQL pretty hard without writing some more complex custom functions/fragments or whatever.
E: this works and isn’t actually that painful, then you can pattern match on the result. Elixir is so damn cool. Still interested in how to preload different selects, though I think it’s just not intended to preload data that isn’t part of the “root” query.