Hints Today’s hint won’t help you move up the leaderboard but it can help you, and others, understand what is happening in your model training. This hint is about visualizing what is happening with the model.
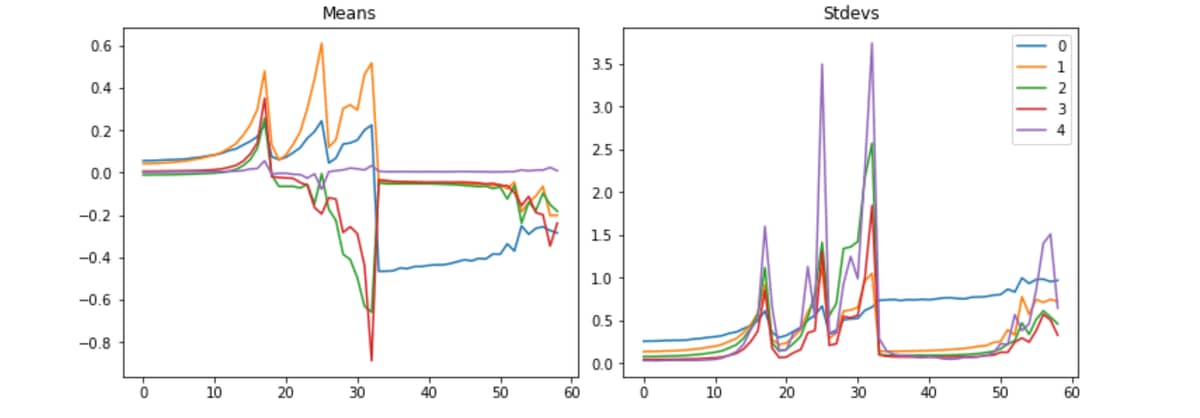
Let’s step back and talk about parameters, i.e. weights and biases. Parameters are the millions or billions of numbers that are optimized via calculations when training a model. An oversimplification of a model is a structured graph of matrix multiplications and additions in layers. Each graph node, layer, receives the output of one or more layers until the final output is reached. When there is a whole lot of multiplication and addition combining together it doesn’t take too long before the calculations exceed what can be represented by a computer as a number, i.e. NaN. So, researchers have generally focused on floating point numbers with full precision, f32, to represent the numbers in a model. Furthermore, they have identified that the optimal situation is when mean of the numbers is about 0.0 and the standard deviations is 1.0. Small floating point numbers are the general goal. By visualizing the mean and standard deviations of multiple layers we can see when the model crashes and starts to recover. Consider creating a Livebook visualization of parameters or as Jeremy calls them activations.
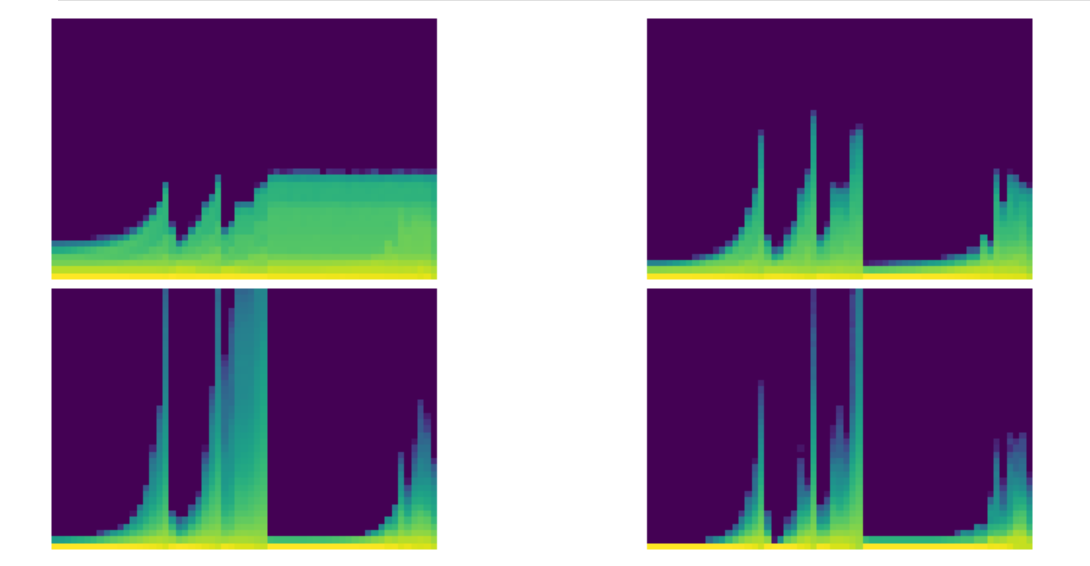
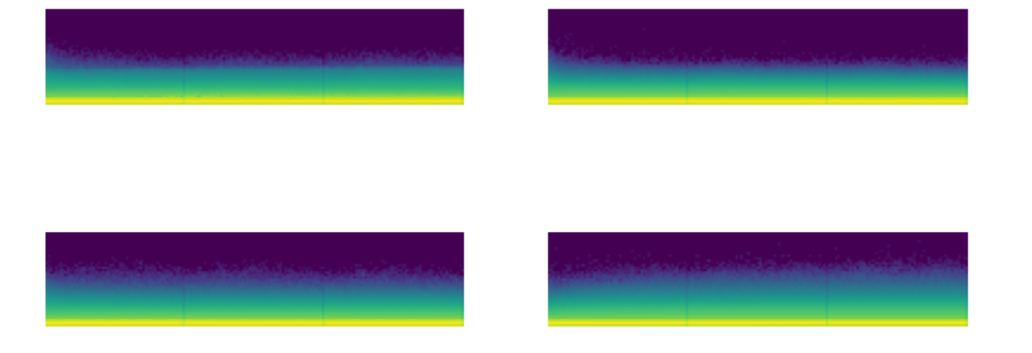
Fast.ai also has a histogram of activations (parameters). Here are a couple of pictures of the crashing training from above and a later well controlled training.
Using the words from the summary, here is how Jeremy described the histogram algorithm.
We call them the colorful dimension, which they’re histograms…So a histogram, to remind you, is something that takes a collection of numbers and tells you how frequent each group of numbers are. And we’re going to create 50 bins for our histogram. So we will use our hooks that we just created, and we’re going to use this new version of append_stats. So it’s going to train as before, but now we’re going to, in addition, have this extra thing in stats, which is going to contain a histogram. And so with that, we’re now going to create this amazing plot. Now what this plot is showing is for the first, second, third, and fourth layers, what does the training look like? And you can immediately see the basic idea is that we’re seeing the same pattern. But what is this pattern showing? What exactly is going on in these pictures? So I think it might be best if we try and draw a picture of this. So let’s take a normal histogram. So let’s take a normal histogram where we basically have grouped all the data into bins, and then we have counts of how much is in each bin. So for example, this will be like the value of the activations, and it might be, say, from 0 to 10, and then from 10 to 20, and from 20 to 30. And these are generally equally spaced bins. Okay. And then here is the count. So that’s the number of items with that range of values. So this is called a histogram. Okay. So what Stefano and I did was we actually turned that histogram, that whole histogram, into a single column of pixels. So if I take one column of pixels, that’s actually one histogram. And the way we do it is we take these numbers. So let’s say it’s like 14, that one’s like 2, 7, 9, 11, 3, 2, 4, 2. And so then what we do is we turn it into a single column. And so in this case we’ve got 1, 2, 3, 4, 5, 6, 7, 8, 9 groups, right? So we would create our 9 groups. Sorry, they were meant to be evenly spaced, but they were not a very good job. Got our 9 groups. And so we take the first group, it’s 14. And what we do is we color it with a gradient and a color according to how big that number is. So 14 is a real big number. So depending on what gradient we use, maybe red’s really, really big. And the next one’s really small, which might be like green. And then the next one’s quite big in the middle, which is like blue. Next one’s getting quite, quite bigger still. So maybe it’s just a little bit, sorry, should go back to red. Go back to more red. Next one’s bigger stills, it’s even more red and so forth. So basically we’re taking the histogram and taking it into a color coded single column plot, if that makes sense. And so what that means is that at the very, so let’s take layer number two here. Layer number two, we can take the very first column. And so in the color scheme that actually Matplotlib’s picked here, yellow is the most common and then light green is less common. And then light blue is less common and then dark blue is 0. So you can see the vast majority is 0 and there’s a few with slightly bigger numbers, which is exactly the same that we saw for index one layer. Here it is, right? The average is pretty close to 0. The standard deviation is pretty small. This is giving us more information, however. So as we train at this point here, there is quite a few activations that are a lot larger, as you can see. And still the vast majority of them are very small. There’s a few big ones, they’ve still got a bright yellow bar at the bottom. The other thing to notice here is what’s happened is we’ve taken those stats, those histograms, we’ve stacked them all up into a single tensor, and then we’ve taken their log. Now log1p is just log of the number plus one. That’s because we’ve got zeros here. And so just taking the log is going to kind of let us see the full range more clearly. So that’s what the log’s for. So basically what we’d really ideally like to see here is that this whole thing should be a kind of more like a rectangle. The maximum should be not changing very much. There shouldn’t be a thick yellow bar at the bottom, but instead it should be a nice even gradient matching a normal distribution. Each single column of pixels wants to be kind of like a normal distribution, so gradually decreasing the number of activations. That’s what we’re aiming for. There’s another really important and actually easier to read version of this, which is what if we just took those first two bottom pixels, so the least common 5%, and counted up how many were in, sorry, the least common 5%. The least common, not least common either, let’s try again. In the bottom two pixels, we’ve got the smallest two equally sized groups of activations. We don’t want there to be too many of them because those are basically dead or nearly dead activations. They’re much, much, much smaller than the big ones. And so taking the ratio between those bottom two groups and the total basically tells us what percentage have zero or near zero or extremely small magnitudes. And remember that these are with absolute values. So if we plot those, you can see how bad this is. And in particular, for example, at the final layer, nearly from the very start, really, nearly all of the activations are just about entirely disabled. So this is bad news. And if you’ve got a model where most of your model is close to 0, then most of your model is doing no work. And so it’s really not working. So it may look like at the very end, things were improving. But as you can see from this chart, that’s not true. The vast majority are still inactive. Generally speaking, I found that if early in training you see this rising crash, rising crash at all, you should stop and restart training because your model will probably never recover. Too many of the activations have gone off the rails. So we want it to look kind of like this the whole time, but with less of this very thick yellow bar, which is showing us most are inactive.
[lession16.txt]
Notebooks 10_activations.ipynb, 11_initializing.ipynb, 12_accel_sgd.ipynb
Having either the polyline or the histogram would help visualize Axon models. Rohan Relan provided a notebook that uses a publish/subsribe example for getting information out of the training loop and into a Kino visualization. Axon model hooks, Model hooks — Axon v0.6.1, provide a technique for getting activations from layers that can be published to Kino.