Hello,
I have simple task what I would like to accomplish with Flow API but I struggle and can not get acceptable result.
My input is 4000K files with ~1 billion records. Records are “apple” “orange” and “other stuff”.
The result of the work I need to get from input is to have ALL apples in file ‘apples.txt’ and all oranges in file ‘oranges.txt’. I have in my dispose lets say m5.24xl (96 cores) node.
What I am doing is:
def parse_r(record) do
case String.split(record, ",") do
[_, fruit, _] ->
r?(fruit)
_ ->
""
end
end
# return apple, orange or empty for the rest
def r?("apple:" <> _, r), do: r
def r?("orange:" <> _, r), do: r
def r?(_, _r), do: ""
# for filter to ignore rest
def is_not_blank?(""), do: false
def is_not_blank?(string), do: true
# apple hashKey = 0, orange = 1
def get_partition("apple:" <> _ = l), do: {l, 0}
def get_partition(_ = l), do: {l, 1}
result =
# ~4000k files containing 1 billion of records
source_data("/home/ec2-user/data/konaElixir/#{hour}/fruits")
# asking to process batch of 10 files
|> Flow.from_enumerables(max_demand: 10)
# in each file split by new line
|> Flow.flat_map(&String.split(&1, new_line))
# parse into 'apple', 'orange' or ""
|> Flow.map(&parse_r/1)
# take only 'apple' or 'orange'
|> Flow.filter(&is_not_blank?/1)
# parition them apples to apples, oranges to oranges and I dont know I have to use 2 stage???
|> Flow.partition(hash: &get_partition/1, stages: 2)
# ignore duplicates of the same fruits (lets say fruit has ID)
|> Flow.uniq()
# prepare for output by adding new line
|> Flow.map(&add_new_line(&1, "\n"))
# accumulate apples and oranges
|> Flow.reduce(fn -> [] end, fn e, acc -> [e | acc] end)
|> Flow.emit(:state)
|> Flow.partition(stages: 2)
|> Flow.map(&write_to_file(&1, output_path))
|> Enum.to_list()
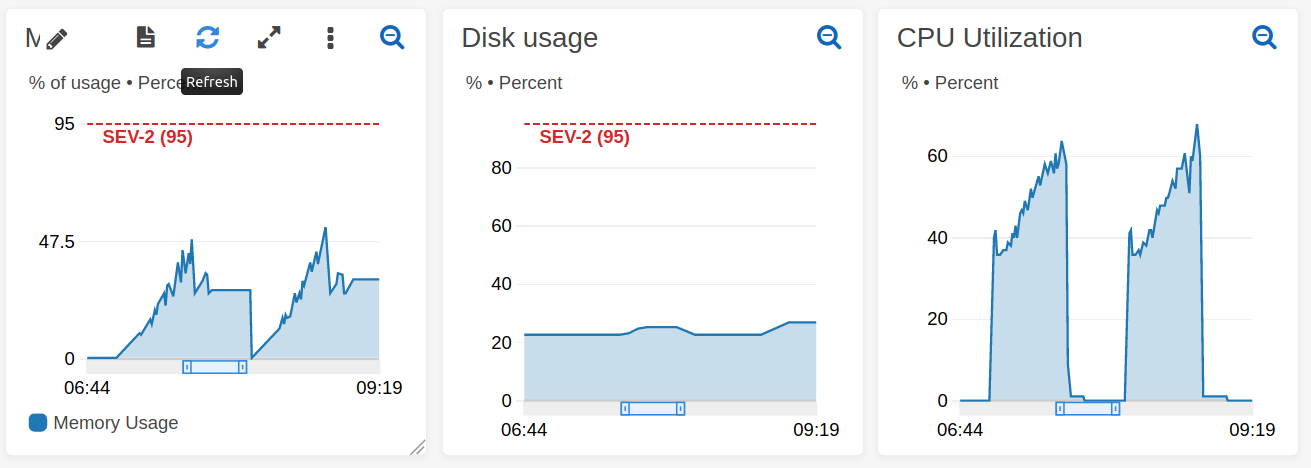
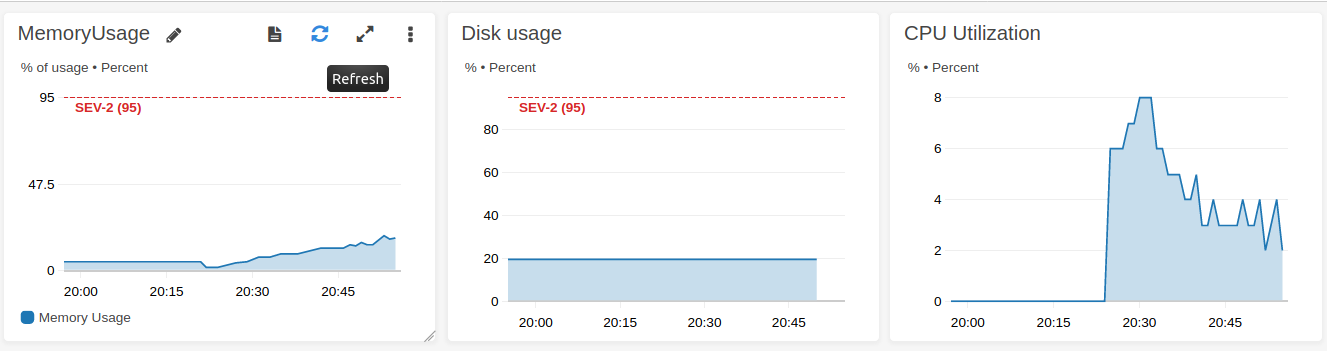
This implementation works but it is very inefficient My CPU load is only ~5%. I tried to remove stages: 2 but result is almost the same.
Could Elixir community please review and suggest the solution for this task and point me on mistakes? Thank you.