
tompave
FunWithFlags: a feature toggle library plus its web GUI as a Plug
Hello there,
I would like to share a feature toggles library (AKA feature flags) I’ve been working on.
The main package is FunWithFlags, which provides global toggles (simple on/off), actor toggles (enabled or disabled for specific entities, e.g. a user), and group toggles (enabled or disabled for groups of actors).
The library uses Redis for persistence and ETS for caching.
I’ve also released FunWithFlags.UI, its optional web GUI available as a Plug for Phoenix or other Plug applications.
If you come from Ruby on Rails, it’s very similar to the flipper Ruby gem.
Example usage:
harry = %User{id: 1, name: "Harry Potter", groups: [:wizards, :gryffindor]}
hagrid = %User{id: 2, name: "Rubeus Hagrid", groups: [:wizards, :gamekeeper]}
dudley = %User{id: 3, name: "Dudley Dursley", groups: [:muggles]}
FunWithFlags.disable(:wands)
FunWithFlags.enable(:wands, for_group: :wizards)
FunWithFlags.disable(:wands, for_actor: hagrid)
FunWithFlags.enabled?(:wands)
false
FunWithFlags.enabled?(:wands, for: harry)
true
FunWithFlags.enabled?(:wands, for: hagrid)
false
FunWithFlags.enabled?(:wands, for: dudley)
false
A quick demo of the web GUI, here served from a Phoenix app:
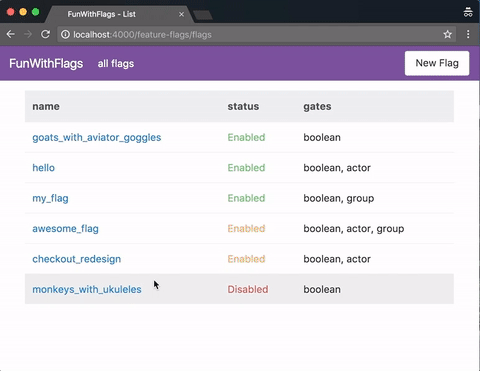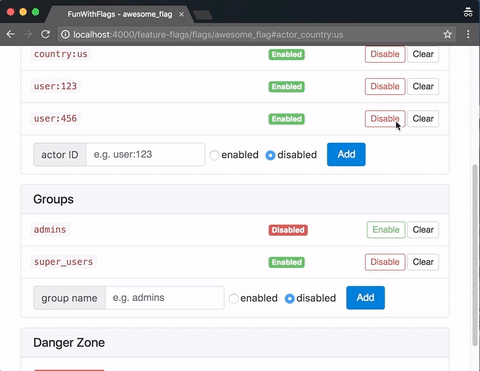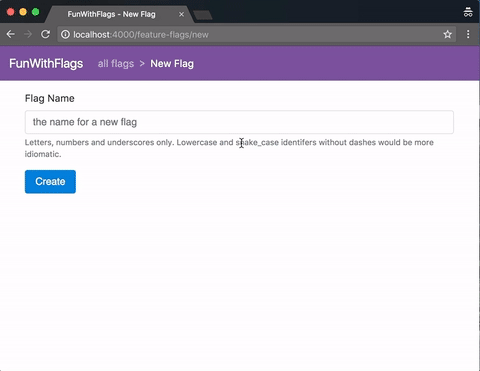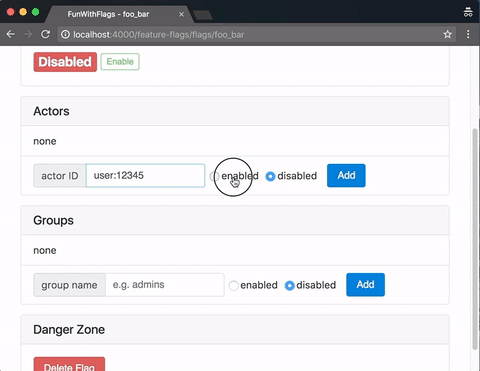
First Post!

brightball
Most Liked
tompave
Hi there,
I’ve released version 1.0.0 of this package and updated the web-UI plugin to support the new features.
This is a significant release because it adds two new kinds of toggles that I’m particularly happy about:
- percentage of time gates
- percentage of actors gates
They basically do what it says on the tin, and more details can be found on github.
The percentage of actors gate is a great starting block to build an AB testing harness, because it allows to enable a feature for a fixed subset of users with deterministic, consistent and repeatable results. In a web application, if used together with an analytics system to track conversion success rates, it can be used to run experiments and observe the effects on user behaviour.
tompave
Hello,
I’ve released new versions of this library and its GUI extension:
I’ve added a new PubSub adapter to support cache-busting notifications over distributed Erlang, to be used as an alternative to the Redis PubSub adapter.
The new adapter uses Phoenix.PubSub and its high level API, so it doesn’t really care about what’s used under the hood as transport. It works out of the box with pg2 when running in a cluster of nodes.
I’ve also refactored the internals to make them more modular. Specifically, now it would be really easy to add other persistence adapters, as all they need to do is to reimplement the API of the Redis module. Redis is still the default store, but I’m thinking of adding an Ecto adapter (CC @aseigo).
tompave
Docker perfectly supports mapping a set of named containers together, then they can share a set of ports to communicate and all sorts of things. If Heroku is broken enough not to support such setups (I’ve not used it) then move to another (because all that I have tried support distributed Elixir fine) or communicate over an SSH connection or teleport a connection or a variety of other ways. There is absolutely no reason to use Redis in an EVM system at all (maybe to integrate with others, but that is not what this is for).
(…)
Or use any of the other distribution protocols, can map the EVM over ssh or a proxy or teleport or a number of things, or write your own to go over tcp or udp or sctp or whatever, all of which then become just drop it in.
I feel like I’ve touched a nerve here. Apologies if I’ve said something technically naive, but let me explain better my point of view.
I understand where you’re coming from, but I don’t think that your approach is correct.
If a team or organization is running on Heroku (they’re a lot), and they’re looking at Elixir and Phoenix, and they’re trying to find their bearings in an unfamiliar ecosystem, then telling them what you wrote above won’t work. If the objective is to grow the Elixir userbase, then it will actually cause damage.
I can promise you that there is no way a sensible team is going to change their hosting and platform just because they want to run a different language. New teams on greenfield projects, maybe. If they can be bothered.
Again, my declared goal was to provide functionality in a form that is familiar to people moving into Elixir and Phoenix from other languages and frameworks. It’s about lowering the entry barrier, and I believe that it’s something that will helps the language and ecosystem gain traction.
We all know that experienced people who have used a dozen languages over more than 10 years can deploy Phoenix on Docker and setup a cluster of BEAM VMs and have Phoenix play ping-pong with PG2 and probably clean the dishes while hangover and walk the dog in the morning. Cool. What I think I’m after, however, are people who have used Rails or Django for years, are used to much simpler setups (where Redis is a staple for a number of reasons, and service or node autodiscovery is a scary beast), and are anxiously looking around for a more performant alternative. A lot of them have been moving to Node.js, but a lot have also been moving to Elixir and Phoenix.
Redis is definitely not something that will just work everywhere. Erlang can be deployed to micro containers (like to run on an RPi or so) that Redis will not work on as one of many examples. Plus that is extra stuff to set up, which makes setup more difficult (much more so with Redis).
(…)
Especially this, if an application is big enough for something like this Redis is even less useful as Redis is entirely useless when the system already has PostgreSQL, which entirely has all of Redis’s capabilities.
(…)
Redis is not a lightweight thing to install.
(…)
Which begs the question of 'Why Redis?" ^.^
(…)
/me is a bit miffed at Redis due to setup issues with it in the past…
This makes me think that you might not be very familiar with Redis, the same way I am clearly less familiar with Elixir, OTP and BEAM than you are.
Redis can handle thousands of clients and millions of calls per minute, and its latency is generally very low.
if an application is big enough for something like this Redis is even less useful as Redis is entirely useless when the system already has PostgreSQL, which entirely has all of Redis’s capabilities.
I’m sorry, but this is wrong and misinformed. A relational DB and Redis serve completely different requiremnts, and a complex and large-scale application can make very good use of both at the same time, for different things. Redis is also a good cache, and it can help shed some load from the DB.
I have the feeling that we are looking at this from completely different angles.
The design goals of the library are to help people working in an environment of PaaS and SaaS, where developers are used to accept the narrow constraints of some platforms and quickly spin up a managed Redis instance if needed.
On the other hand, I think that you’re mainly focused on the increased overhead of running Redis in a data center that you manage youself, which leads to the importance of doing as much as possible in the BEAM.
The things you suggested seem interesting though. Would you care to provide some examples?
Popular in Announcing








Other popular topics



Latest on Elixir Forum
Sponsor Spotlight

Deploy Phoenix to your own VPS with PaaS ease: push-to-deploy, zero downtime, auto SSL, managed Postgres. 14-day free trial at potions.io
Categories:
Sub Categories:
Forums
Popular Tags
- #ecto
- #liveview
- #troubleshooting
- #learning-elixir
- #deployment
- #library
- #erlang
- #testing
- #genserver
- #mix
- #absinthe
- #remote-other
- #otp
- #plug
- #how-to-question
- #macros
- #postgres
- #channels
- #elixirconf
- #exunit
- #discussion
- #code-sync
- #javascript
- #podcasts
- #onsite
- #dialyzer
- #docker
- #authentication
- #umbrella
- #full-time-contract
- #podcasts-by-brainlid
- #ecto-query
- #elixir-ls
- #phoenix_html
- #iex
- #blog-post
- #graphql
- #genstage
- #ai
- #websockets
- #supervisor
- #elixirconf-us
- #advent-of-code
- #distillery
- #processes
- #api
- #forms
- #metaprogramming
- #security
- #hex
Our Sponsors

Build Elixir applications with speed and confidence.

Supporting innovation across the BEAM ecosystem.

We build reliable cloud platforms for business-critical systems.

Catch errors, track performance, monitor hosts and more.

Error tracking, logs, uptime, and Just Enough APM. Built for developers.

Practical resources that improve the lives of professional developers.

Enabling companies to succeed by building software people love.
The deployment platform built for Elixir: PaaS ease, VPS control.

The team behind Membrane, Popcorn, LiveDebugger. Available for hire.

Courses that'll move you from confusion to "Aha, now I get it!"