I’ve continued my journey and committed to the project every now and then.
https://git.limo/redrabbit/git-limo
So here’s a little update  .
.
Distributed Setup
The current version is running on Fly  . I’ve got a small cluster (two nodes: FRA, LAX) setup with
. I’ve got a small cluster (two nodes: FRA, LAX) setup with :libcluster so adding new nodes should work automatically.
Each Fly instance has it own storage attached for storing Git repositories. When a user creates a new repository it is assigned to the local’s node storage and all the Git objects will be stored there:
I live in Austria, so my Git repositories are stored on the closest instance running in Frankfurt.
When accessing one of my repos from the US, the instance in Los Angeles will route all Git commands to the right node.
In order to get things working without too much latency, I had to refactor a big chunk of code to batch Git commands together and keep the number of roundtrips between instances low. In the end I’m quite happy with the results 
Try for yourself:
Repository Pools
I’ve implemented some kind of distributed routing pool on top of Erlang’s :global.
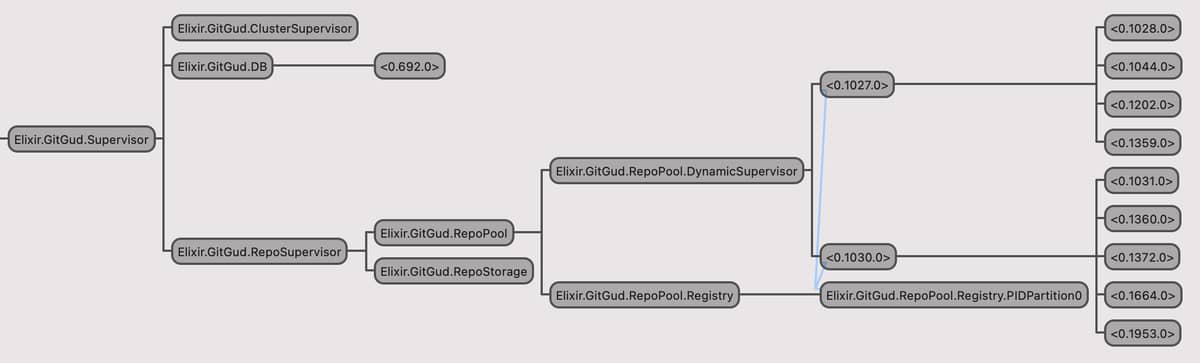
Here’s a screenshot of the supervision tree:
When a node start’s up, GitGud.RepoSupervisor does a few things:
- tags the local storage (if not already tagged) and registers the resulting id across the cluster.
- starts a
GitGud.RepoStorage worker for handling filesystem operations.
- starts a
GitGud.RepoPool supervisor for handling Git commands.
The GitGud.Repo schema has a :volume field which points to the storage VOLUME where it data is stored. When creating a repositories it is assigned to the local storage:
field :volume, :string, autogenerate: {GitGud.RepoStorage, :volume, []}
With this in mind, let see how we can run Git commands on a specific repository:
repo = GitGud.RepoQuery.user_repo("redrabbit", "git-limo")
{:ok, agent} = GitRekt.GitRepo.get_agent(repo)
{:ok, head} = GitRekt.GitAgent.head(agent, head)
{:ok, commit} = GitRekt.GitAgent.peel(agent, head)
{:ok, commit_msg} = GitRekt.GitAgent.commit_message(agent, commit)
IO.puts commit_msg
The above example prints the HEAD commit message for redrabbit/git-limo.
The interesting part here is GitRekt.GitRepo.get_agent/1 which is implemented by GitGud.Repo:
defimpl GitRekt.GitRepo, for: GitGud.Repo do
def get_agent(repo), do: GitGud.RepoPool.checkout(repo)
end
As you can see, it rely on GitGud.RepoPool for retrieving a Git agent from the pool on the right node. Let’s dive into it  .
.
Internally, the pool can be seen as a DynamicSupervisor of DynamicSupervisors. GitGud.RepoPool.checkout/1 being the entry-point for fetching agents. It also provides a few nice things:
- auto scale – grows/shrinks the number of agent processes based on demand.
- global cache – agents in a pool share a global ETS table.
- round robin – agents are distributed using round-robin.
- node aware – a pool will always start on the right node based on the repo’s
VOLUME.
Git Agents
The GitRekt.GitAgent module is the backbone for running Git commands. While the public API is quite easy to grasp, it hides a lot of complexity.
An agent is basically a wrapper around GitRekt.Git. Here’s a very basic usage example:
{:ok, agent} = GitRekt.GitAgent.start_link("path/to/workdir")
{:ok, tags} = GitRekt.GitAgent.tags(agent)
for tag <- tags do
IO.puts "Tag #{tag.name} -> #{Base.decode16(tag.oid)}"
end
In the above example, agent is a dedicated process for running Git commands.
Note that it is also allowed to run Git commands in the current process as well:
{:ok, agent} = GitRekt.Git.repository_open("path/to/workdir")
{:ok, branches} = GitRekt.GitAgent.branches(agent)
for branch <- branches do
IO.puts "Branch #{branch.name} -> #{Base.decode16(branch.oid)}"
end
In the above example, agent is a NIF-resource representing a libgit2 repository.
Transactions
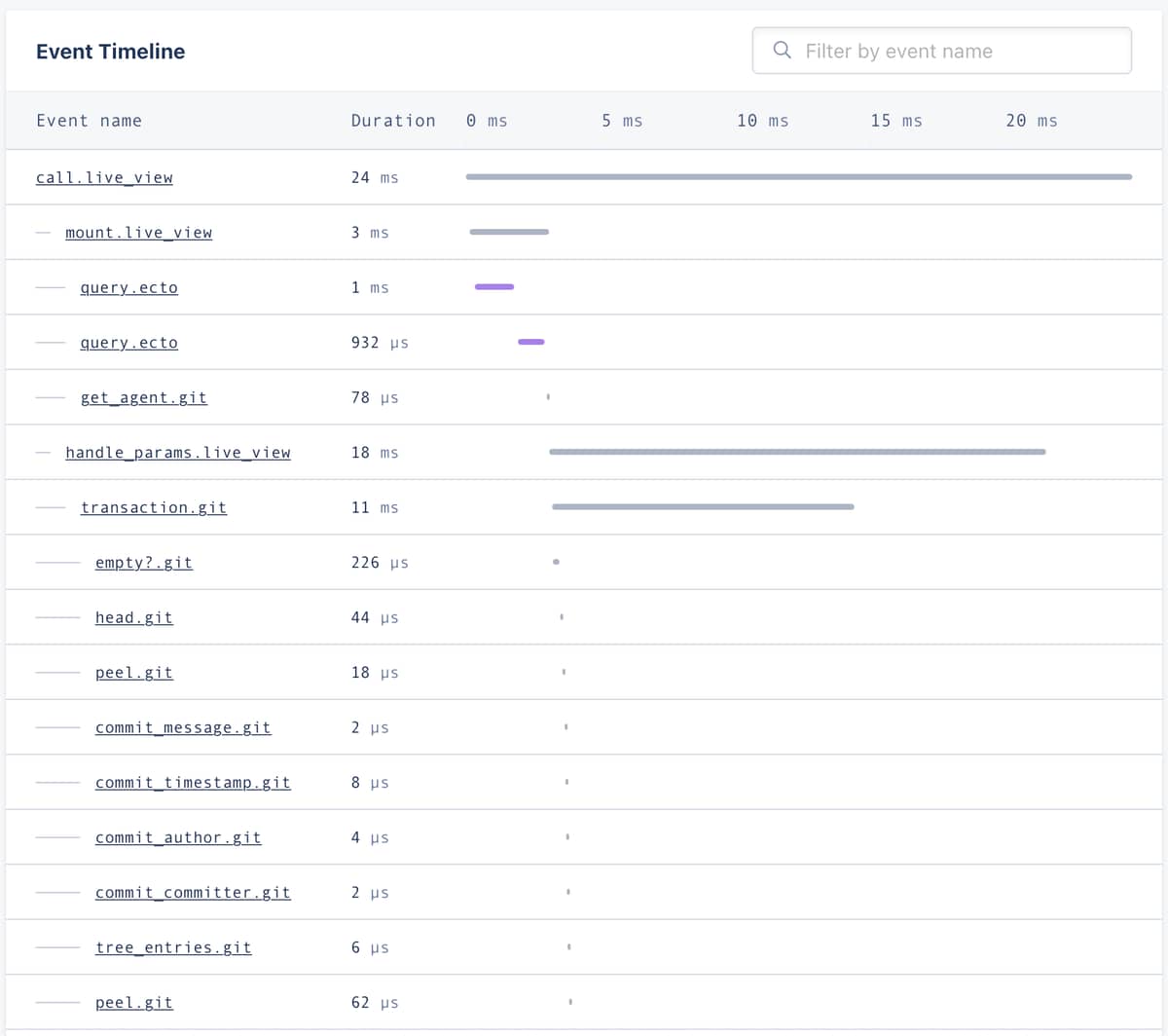
GitRekt.GitAgent provides support for transactions aka. batching a bunch of Git operations in one call. This is very important when running Git commands on a separate node:
# agent is a PID running on an other node
{:ok, head} = GitRekt.GitAgent.head(agent, head) #1
{:ok, commit} = GitRekt.GitAgent.peel(agent, head) #2
{:ok, commit_msg} = GitRekt.GitAgent.commit_message(agent, commit) #3
IO.puts commit_msg
Running the above code would make three separate GenServer.call/2 resulting in quite some latency. We can fix this by batching the commands in a transaction:
# agent is a PID running on an other node
{:ok, commit_msg} =
GitRekt.GitAgent.transaction(agent, fn agent ->
with {:ok, head} <- GitRekt.GitAgent.head(agent, head),
{:ok, commit} = GitRekt.GitAgent.peel(agent, head) do
GitRekt.GitAgent.commit_message(agent, commit)
end)
In the above example, the three commands are execute in a single call on the dedicated agent process. Reducing the overall latency…
Caching
An additional feature of GitRekt.GitAgent is caching. When running transaction/3 we can pass a cache key as the 2nd argument:
def commit_info(agent, commit) do
GitAgent.transaction(agent, {:commit_info, commit.oid}, fn agent ->
with {:ok, author} <- GitAgent.commit_author(agent, commit),
{:ok, committer} <- GitAgent.commit_committer(agent, commit),
{:ok, message} <- GitAgent.commit_message(agent, commit),
{:ok, parents} <- GitAgent.commit_parents(agent, commit),
{:ok, timestamp} <- GitAgent.commit_timestamp(agent, commit),
{:ok, gpg_sig} <- GitAgent.commit_gpg_signature(agent, commit) do
{:ok, %{
oid: commit.oid,
author: author,
committer: committer,
message: message,
parents: Enum.to_list(parents),
timestamp: timestamp,
gpg_sig: gpg_sig
}}
end
end)
end
You may have noticed the {:commit_info, commit.oid} tuple given to transaction/3. This tells the agent that the transaction should be cached using this key.
Calling commit_info/2 two times in a row would result in the following log output:
[debug] [Git Agent] transaction(:commit_info, "b662d32") executed in 361 µs
[debug] [Git Agent] > commit_author(<GitCommit:b662d32>) executed in 6 µs
[debug] [Git Agent] > commit_committer(<GitCommit:b662d32>) executed in 5 µs
[debug] [Git Agent] > commit_message(<GitCommit:b662d32>) executed in 1 µs
[debug] [Git Agent] > commit_parents(<GitCommit:b662d32>) executed in 4 µs
[debug] [Git Agent] > commit_timestamp(<GitCommit:b662d32>) executed in 11 µs
[debug] [Git Agent] > commit_gpg_signature(<GitCommit:b662d32>) executed in 6 µs
[debug] [Git Agent] transaction(:commit_info, "b662d32") executed in ⚡ 3 µs
We can observe that the first call executes the different commands one by one and cache the result while the second one fetches the result directly from the cache without having to actually run the transaction.
There’s a lot more to tell about GitRekt.GitAgent’s internals (streaming support, mechanism to prevent the garbage collector for deleting NIF-resources, etc.). If you’re interested I can write a small post about it.
LiveView
On the frontend, I’ve managed to introduce Phoenix LiveView and replace all my React/Relay components with a LiveView counterpart. For example, the GitGud.Web.TreeBrowserLive is used to navigate across a Git repository tree. Here’s a list of all views/components:
GitGud.Web.BlobHeaderLiveGitGud.Web.BranchSelectLiveGitGud.Web.CommentFormLiveGitGud.Web.CommentLiveGitGud.Web.CommitDiffLiveGitGud.Web.CommitLineReviewLiveGitGud.Web.GlobalSearchLiveGitGud.Web.IssueEventLiveGitGud.Web.IssueFormLiveGitGud.Web.IssueLabelSelectLiveGitGud.Web.IssueLiveGitGud.Web.MaintainerSearchFormLiveGitGud.Web.TreeBrowserLive
Fast Git Backend Server
I also refactored the Git backend aka. GitRekt.WireProtocol which was slow and consumed a lot of resources.
When pushing a repository, the incoming PACK file is now directly streamed to the disk. This increases raw performances about 700% and greatly reduced the amount of RAM and CPU used for the operation.
The performance boost allows to fetch/push across nodes in a cluster setup. When you push via SSH you will send the PACK to the nearest node which is then streamed to the right node in the cluster.



 .
. .
. .
.



















