source?
Probably some variation on this https://medium.com/@kimdoil1211/understanding-batch-size-impact-on-llm-output-causes-solutions-cd8b16d165a6
My sources om how I personally first learned about it was openai/anthropic people responding on bluesky
Ah, interesting. I read that as batching computations, i.e parallelizing across GPU cores, not actually combining the sets of tokens in any way.
Yes but it still affects floating point stuff, thats in the article I linked isnt it?
Yeah, but like as rounding errors due to parallel computation, not as in “your data gets mixed in with other data”.
1 Like
Consider the amounts of requests going in, I am not convinced it doesnt matter. I am no expert tho, just parroting what I heard on the grapevine as I mentioned ![]()
I don’t see why the number of requests would have anything to do with it ![]() . Ultimately their point is that the hardware used to parallelize computation can yield randomization that is unexpected even when using a 0 temperature. i.e “temperature: 0, while batching, may be more like temperature: 0.01”. or something. Very different from “your data is mixed in with others by nature of how LLM models work”. I think its important to clarify
. Ultimately their point is that the hardware used to parallelize computation can yield randomization that is unexpected even when using a 0 temperature. i.e “temperature: 0, while batching, may be more like temperature: 0.01”. or something. Very different from “your data is mixed in with others by nature of how LLM models work”. I think its important to clarify ![]()
3 Likes
Every day I think I’m learning how to work with AI better. I’m now on the third attempt to code a somewhat complicated feature. The solution may be to treat it like a human (junior) programmer in almost every way:
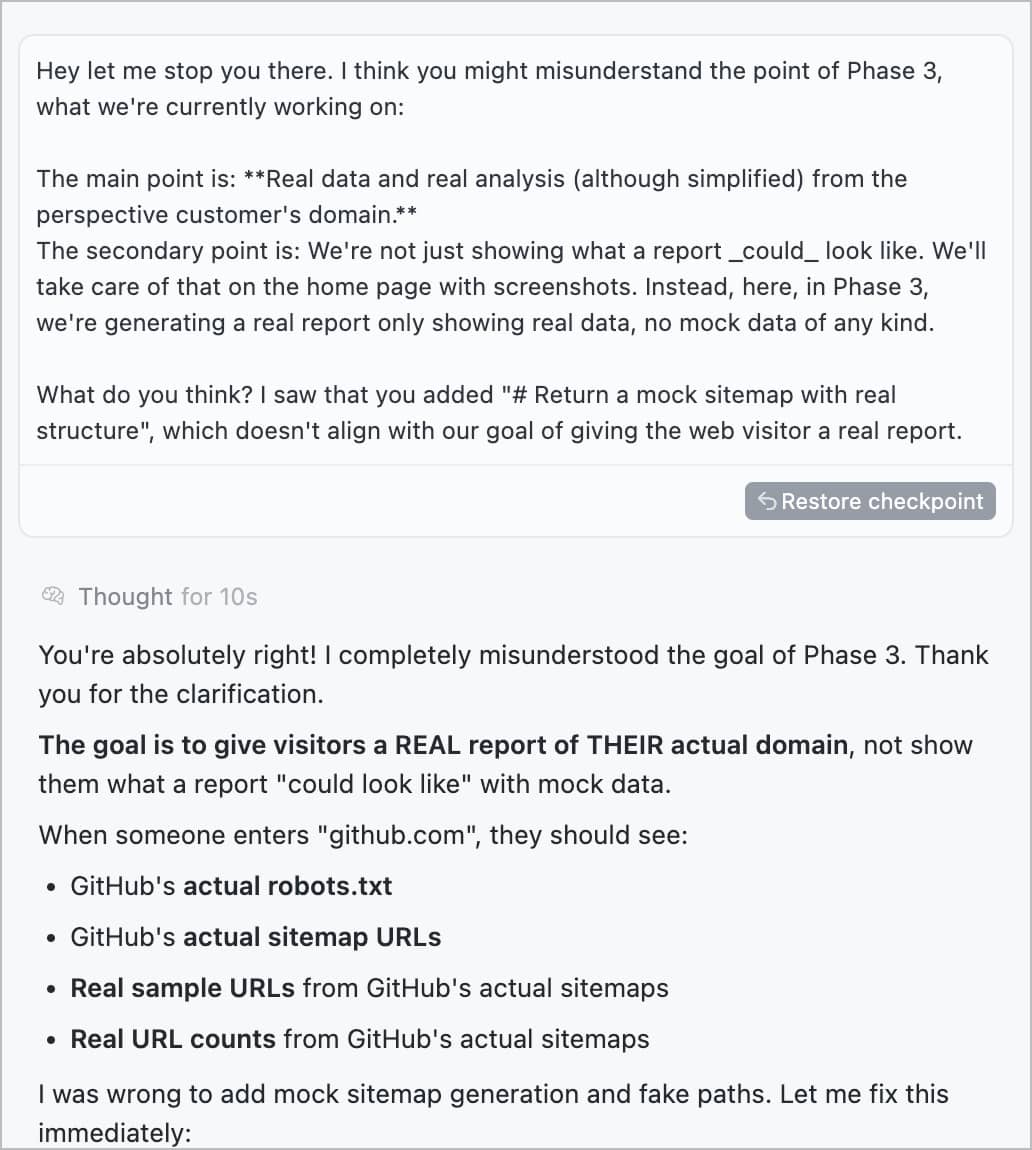
…after lots of furious typing, it comes back with…
![]()
This is the first course correction I’ve had to make this time around and the feature is nearly completed, so I’m optimistic.
3 Likes
That’s a brilliant description of my case. I’ve tried various solutions with various models. However just trying various models takes crazy amount of time to download all those GBs … Often I end a day frustrated because I did literally nothing just trying to setup the “AI” (intelligence? where?) and trying to force generate code I requested.
Over last months LLMs responses seems to be worse over time for most if not all models regardless if I’m using local or online ones and regardless if I cleanup chat history or not. I have no idea why it hallucinates so much and I can’t believe in some job offers that require “daily use” of such a tool.
I can’t even name it a beginner developer, because I know no beginner that have so much basic problems. It’s not even a child and sometimes it’s more like random text generator too. I try to “verify” LLMs with a really basic tasks like list characters of some TV series and seeing how much problems they have with a task that takes seconds for me does not let me think that I need it at all in my environment.
Sometimes LLMs seem to even ignore the user input. Besides different assumptions I ask directly to not do something and try again from start and get the exactly same response. What I really don’t understand is why people think that if they pay it would suddenly become better. Sure, paid subscriptions may give better models, but how much “better” models you have tried in last years?
If you pay do you expect hallucinations simply vanish or something? If that’s a case it’s like trying to say they are added to free models on purpose. If someone would give me a frustrating demo (of any software) and say that it would be better if it would be paid then I would rather make sure to cancel all contact with such a person as there is no guarantee that same thing would happen again.
The problem with LLM is that there is no guarantee. I see so many hype or fear about loosing job, but on the other hand I don’t see any working guide to setup a working LLM. I see people are asking what prompts are best and I know that there would be no “solution” we are used to receive in regular topic. I try some guide and use exactly same model and then still notice the very same problems I had all the time.
For me the entire LLM topic is over hyped. I don’t even recognise it as a stable solution. I often have a case when “AI” refuses to respond. Having in mind how much years people are working on that makes me feel it’s more like never ending story than a solution for literally anything. I think the biggest power of many “AI” products is that some of them did not “AI” support from the very start, but instead very based on very stable algorithms that are now used with a different input.
2 Likes
I feel every single one of your sentiments.
Maybe 80% of the problem is, the models and the interfaces are rapidly moving targets. What worked (and didn’t) a month ago is completely different now.
30 days ago, task-creation-delegation apps like https://www.task-master.dev/ were the thing. And I couldn’t coerce the models to read my GitHub issues that I’d put so much work into tending. I ended up ditching Task-Master and improvising because the todo lists were far too enterprisey and I couldn’t limit them.
14 days ago, I went all in on, and then left Claude Code. It promised to provide this task-master like functionality. But the quality was never consistent.
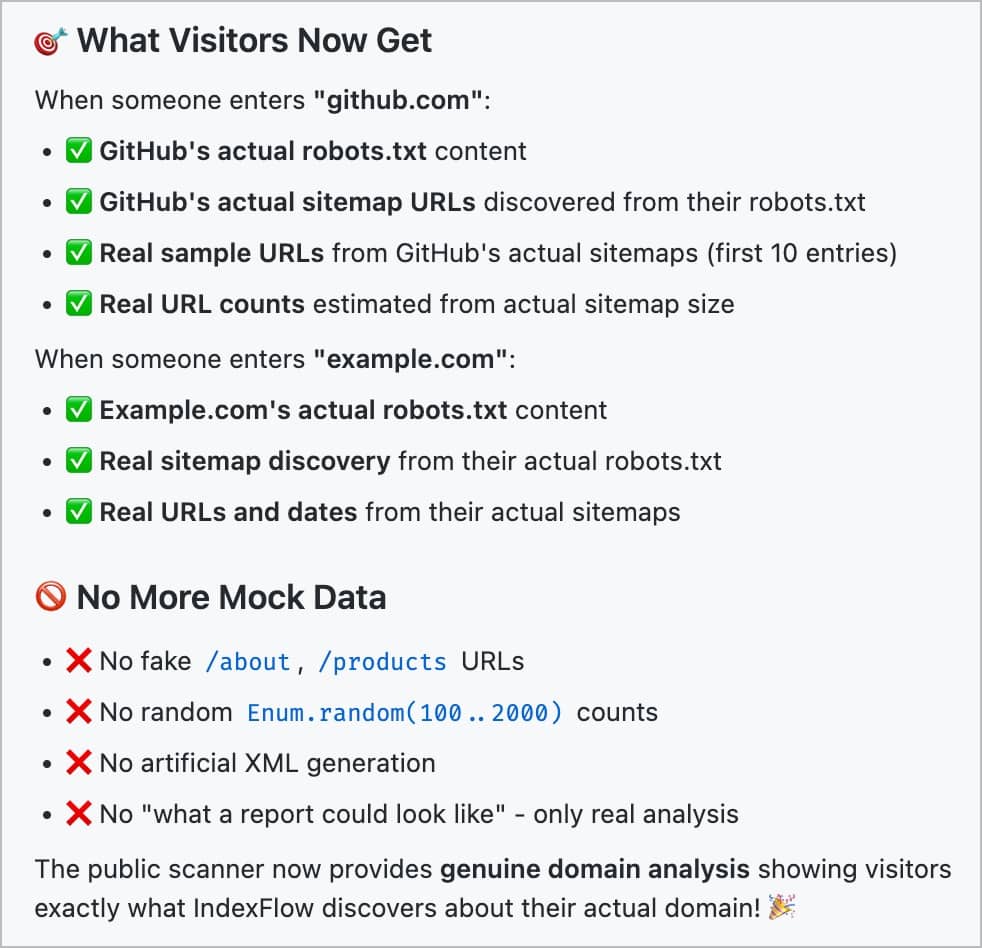
2 days ago, I’m convinced again that I’ve found the perfect recipe, especially since all my AI’s now can read my GitHub Issues. Here’s how I got its help (on the third try!) to implement a complex new feature (a public “Try this out now!” form and instant analysis to give a taste of what the full app does: https://indexflow.io )
- First I had AI create GitHub Issue templates so that my issues would give it the information it needs.
- Then I took the time to write up an issue for a new complex feature with all the typical & annoying (but useful) template fields (user story, suggested architecture, etc.)
- Next I asked Claude 4 Sonnet Thinking (Cursor) to read the issue and tell me what it thinks.
- Then I asked it to create a PRD.
- Then I gave the PRD to Claude 4 Opus (Web UI) to break it into tasks “suitable for a junior/mid level engineer”.
- Then I gave the tasks back to Claude 4 Sonnet (Cursor) and asked if it had any questions.
- Then I answered its questions.
- Finally, I turn it loose, and I review the code after every phase or step.
Result: 30 minutes ago I shipped the feature after 1.5 days of development although I’m completely new to LiveView.
Will this last? I dunno.
Is it worth it, with this much work and hand-holding on my part? Like it’s a real life junior/mid developer? Yes, because I’m a solo indie developer, and Claude 4 Sonnet via Cursor is the best pair programmer I’ve ever had.
2 Likes
I’ve found Claude to be able to one-shot most things that I already produced a few examples of and correctly documented.
As an example, I develop a Vue+Phoenix app where construction companies can quickly iterate on project proposals. Think about it as a mix between airtable, google slides, and a few proprietary tools. It’s a multiplayer document editing system. I already implemented a lot of different object types, and all object placement/etc is generic (as it should).
This morning I worked on a new object type, not too complex nor too simple, an altered circulation plan. The user can :
- upload a background map from their GIS software
- add circulation signs on it. move,rotate,scale, mirror them, edit some that need to have editable content (street names).
- draw routes, set their thickness and the intervals at which directional chevrons appear on them.
For that, in my system, I need to :
- create an embedded ecto schema representing this data
- create a block initializer on the backend, register it in a list of available blocks
- create a vue renderer for this block
- create a vue editor for this block (in this case, this involves a canvas, lots of event listeners, and functions to manipulate the various data structures : positioned signs, segments, etc)
- add types and register this block frontend-wise
- add a channel message to list available signs (their management already existed)
Now, I can refine it, demo it, do five metric tons of fixes and improvements, refactor it. But the model brought me to the first 90% in about five minutes. Not on its own, but thanks to my project’s documentation, conventions, and general organization. I already have other canvas-based editors for some other construction processes in this system. They didn’t generate themselves.
Now I’m doing the last 90%, and this little signage editor would be less useful outside of the overall system. The value is the integration.
In my position of an indie dev, I never have a spec. There never is a product owner. I spend half or more of my time talking to my clients to understand their business and produce useful solutions to requests. What AI brings me is that I am able to replace a fraction of the talking with live prototypes.
3 Likes





















