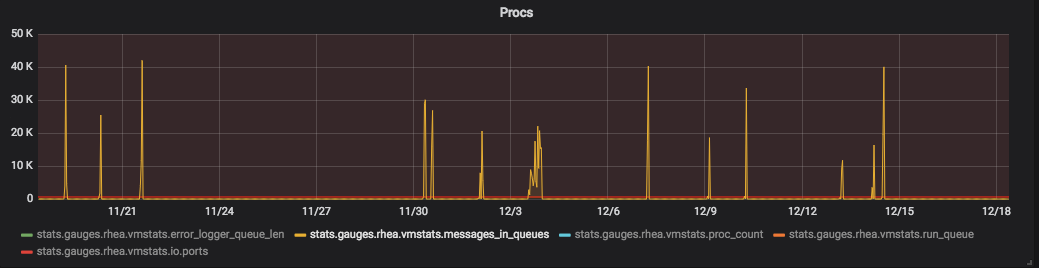
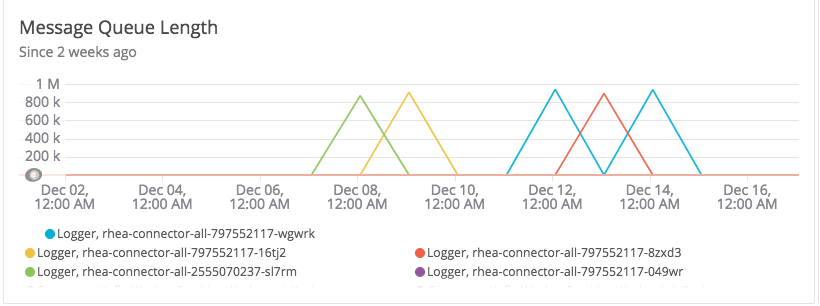
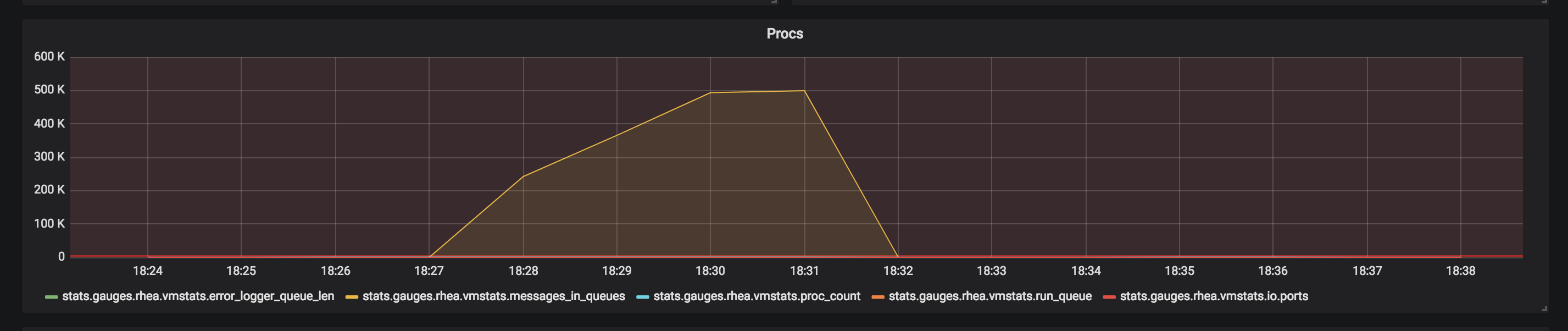
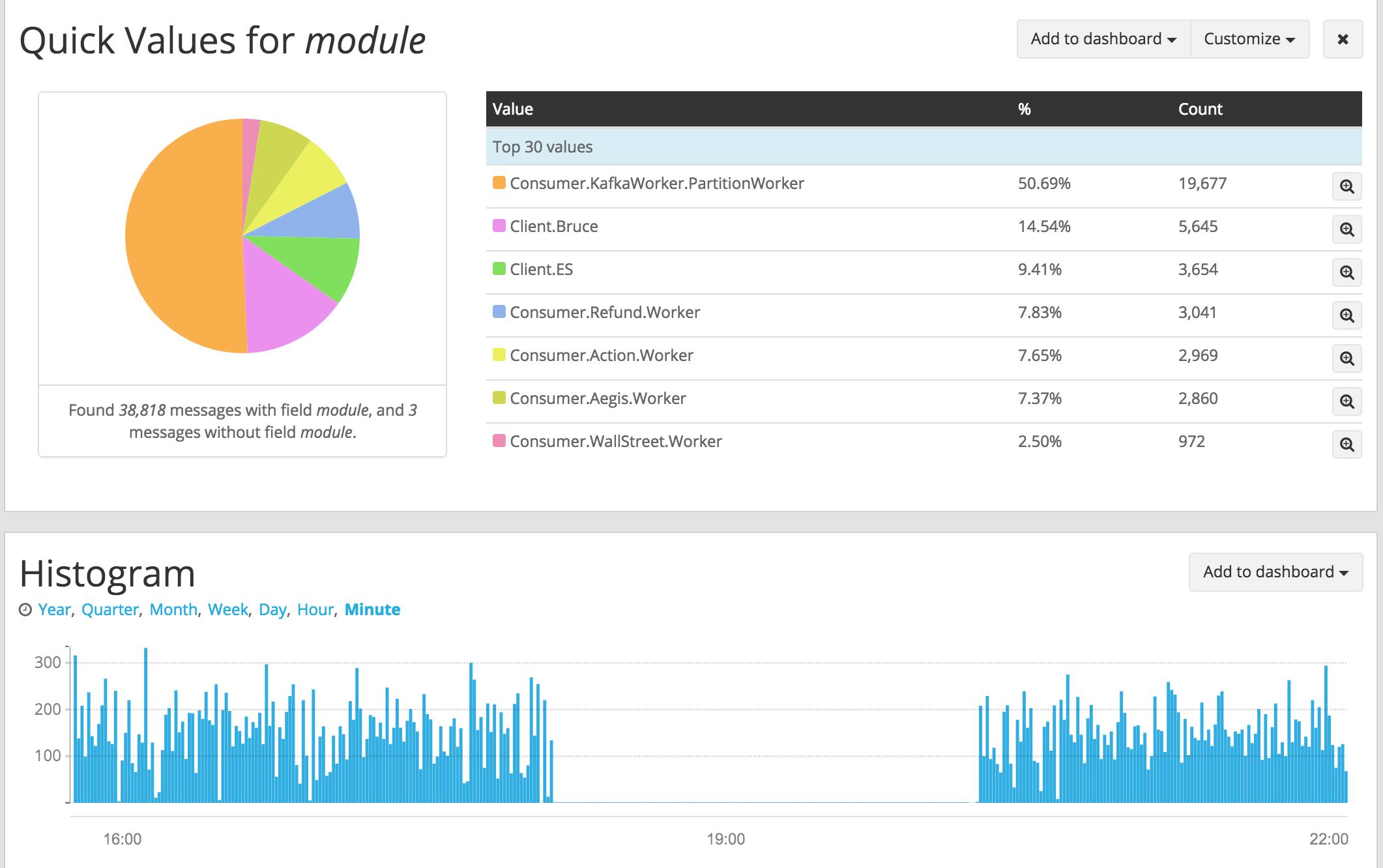
We were able to collect some info before the node crashed this time
> :recon.proc_count(:memory, 5)
[
{#PID<0.1967.0>, 540730196,
[
Logger,
{:current_function, {Logger.Backends.Console, :await_io, 1}},
{:initial_call, {:proc_lib, :init_p, 5}}
]},
{#PID<0.2201.0>, 10868184,
[
:vmstats_server,
{:current_function, {:gen_server, :loop, 7}},
{:initial_call, {:proc_lib, :init_p, 5}}
]},
{#PID<0.1918.0>, 10543500,
[
:code_server,
{:current_function, {:code_server, :loop, 1}},
{:initial_call, {:erlang, :apply, 2}}
]},
{#PID<0.1996.0>, 10010220,
[
:ssl_manager,
{:current_function, {:gen_server, :loop, 7}},
{:initial_call, {:proc_lib, :init_p, 5}}
]},
{#PID<0.2016.0>, 2917916,
[
Tzdata.EtsHolder,
{:current_function, {:gen_server, :loop, 7}},
{:initial_call, {:proc_lib, :init_p, 5}}
]}
]
> :recon.proc_count(:message_queue_len, 5)
[
{#PID<0.1967.0>, 823221,
[
Logger,
{:current_function, {Logger.Backends.Console, :await_io, 1}},
{:initial_call, {:proc_lib, :init_p, 5}}
]},
{#PID<0.8648.524>, 1,
[
current_function: {Consumer.KafkaWorker.LoopGuard, :attempt, 4},
initial_call: {:proc_lib, :init_p, 5}
]},
{#PID<0.8897.931>, 0,
[
current_function: {:prim_inet, :recv0, 3},
initial_call: {:erlang, :apply, 2}
]},
{#PID<0.8258.931>, 0,
[
current_function: {:gen_statem, :loop_receive, 3},
initial_call: {:proc_lib, :init_p, 5}
]},
{#PID<0.7971.931>, 0,
[
current_function: {:tls_connection, :"-ensure_sender_terminate/2-fun-0-",
1},
initial_call: {:erlang, :apply, 2}
]}
]
> :recon.info('<0.1967.0>')
[
meta: [
registered_name: Logger,
dictionary: [
"$initial_call": {:gen_event, :init_it, 6},
"$ancestors": [Logger.Supervisor, #PID<0.1965.0>]
],
group_leader: #PID<0.1964.0>,
status: :waiting
],
signals: [
links: [#PID<0.1968.0>, #PID<0.1970.0>, #PID<0.1971.0>, #PID<0.1966.0>],
monitors: [process: #PID<0.1938.0>],
monitored_by: [],
trap_exit: true
],
location: [
initial_call: {:proc_lib, :init_p, 5},
current_stacktrace: [
{Logger.Backends.Console, :await_io, 1,
[file: 'lib/logger/backends/console.ex', line: 173]},
{Logger.Backends.Console, :handle_event, 2,
[file: 'lib/logger/backends/console.ex', line: 56]},
{:gen_event, :server_update, 4, [file: 'gen_event.erl', line: 577]},
{:gen_event, :server_notify, 4, [file: 'gen_event.erl', line: 559]},
{:gen_event, :server_notify, 4, [file: 'gen_event.erl', line: 561]},
{:gen_event, :handle_msg, 6, [file: 'gen_event.erl', line: 300]},
{:proc_lib, :init_p_do_apply, 3, [file: 'proc_lib.erl', line: 249]}
]
],
memory_used: [
memory: 545669148,
message_queue_len: 826902,
heap_size: 10958,
total_heap_size: 59112578,
garbage_collection: [
max_heap_size: %{error_logger: true, kill: true, size: 0},
min_bin_vheap_size: 46422,
min_heap_size: 233,
fullsweep_after: 65535,
minor_gcs: 113
]
],
work: [reductions: 144940639077]
]
This atleast confirms that console backend is the one that has big message queue. Still wondering why it was not kicking the backpressure mechanism. From application metrics, it seems like all the processes were able continue to write logs (though nothing gets written to stdio) and make progress and we observe no application level errors during the timeframe either.