I’ve just released version 1.1.1 of the Honeydew job queue library and added “instant” Ecto work queues to turn your schema into a job queue.
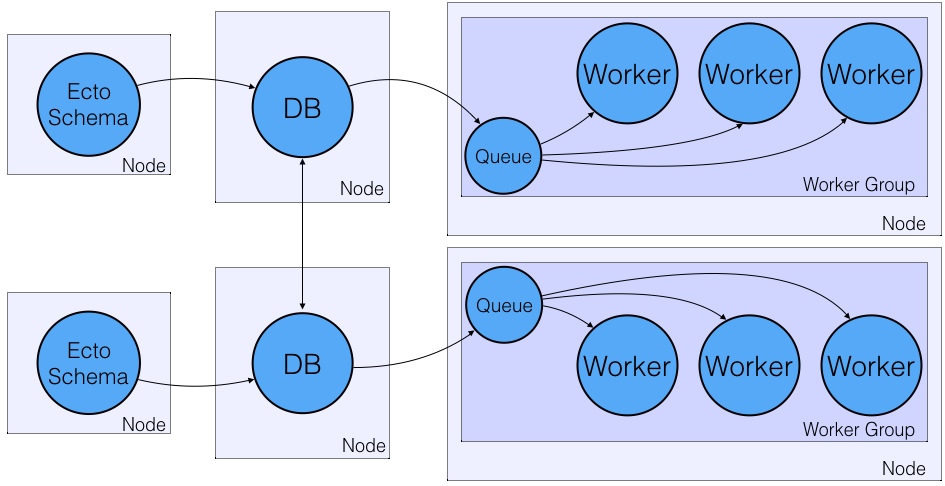
By adding a couple fields to your schema, Honeydew will automatically run background jobs related to your schema on your worker nodes whenever you insert a new row. For instance, if a user uploads a song file, and you want to transcode it into a number of different formats, or if a user uploads a photo and you want to run your object classifier against it.
This is done without a separate database table, and entirely without an external stateful queue process for you to worry about. Since your schema’s table is the work queue itself, they’re always in sync and issues relating to the the lack of atomicity between your row’s insertion and the enqueue are eliminated, in fact, your application code never enqueues jobs at all.
This specific queue type integrates well into the rest of the Honeydew ecosystem, supporting almost all of the library’s features (failure modes, suspend/resume, etc).
Check out the README for a lengthier description and an example project.
Hope folks find it useful, feedback is always welcome. ![]()























