
Fl4m3Ph03n1x
How to use ETS as a global cache?
Background
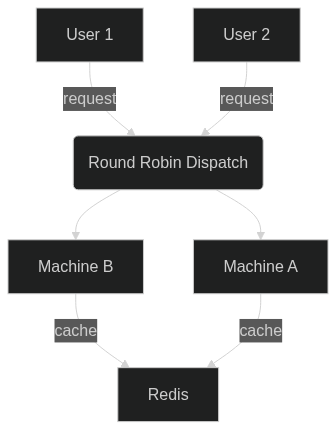
I have an Elixir application that has 2 machines. Each machine receives requests on a round robin base.
Both machines are connected to a single Redis instance, which works as a global cache.
If machine A receives a request, it caches the request/response in Redis. Should machine B get the same request, it won’t need to re-calculate the answer.
Questions
I know that ETS is usually used for caching.
However this cache is local to machine A and local to machine B.
My goal here would be to replace Redis with an ETS instance and achieve a global cache for my elixir applications using ETS. Thus far I was not able to find any article detailing configurations for such, so I wonder:
- Is it possible to use ETS as a global cache via HTTP, the same way Redis is being using in the above example?
- If so how can I do it?
- If it is possible, is it worth the effort, or does the community advice I use Redis instead? (maybe because it is easier to setup, for example)
Marked As Solved

cevado
yes, for sure.
If machine A and machine B are both elixir machines, you could use either Cachex or Nebulex, both takes advantage of a cluster of machines to distribute ets tables across nodes
I particularly think that if you have an elixir application is more simple and less expensive clusterizing your nodes and use ets than use redis.
Also Liked

tangui
This is what http_cache_store_disk and http_cache_store_memory do when cluster_enabled is set to true: they exchange cached responses by using distributed erlang and store them either in ETS table or on disk (and in this latter case, metadata is still stored in memory).
They take into account that nodes can have different requirements such as available disk space or memory and therefore they handle cached response autonomously. A cached response can be discarded from one node and still be available on another.
If you want to cache HTTP responses from Phoenix / Plug, you can take a look at plug_http_cache.

D4no0
What about running separate caches on both instances? You will waste a little bit more ram, however you will get rid of a lot of complexity, which IMO is perfect, as ram is dirt cheap these days.

LostKobrakai
It’s possible. You could always build a http endpoint around ets and server http requests that way. But none of that comes “built in” and I doubt it’s worth it in the general case.
On the beam you also have mnesia which allows you to share kind of an ets table across the cluster, but it’s not quite straight forward to use. That’s local state synchronized across the cluster and not accessing one shared resource.
Without much detail on why you need a global cache I’d probably suggest staying with redis, lacking any reasonable means of doing a tradeoff with other options.
Last Post!

Popular in Questions



Other popular topics



Latest on Elixir Forum
Sponsor Spotlight

Build Elixir applications with speed and confidence.
Categories:
Sub Categories:
Forums
Popular Tags
- #ecto
- #liveview
- #troubleshooting
- #learning-elixir
- #deployment
- #library
- #erlang
- #testing
- #genserver
- #mix
- #absinthe
- #remote-other
- #otp
- #plug
- #how-to-question
- #macros
- #postgres
- #channels
- #elixirconf
- #exunit
- #discussion
- #code-sync
- #javascript
- #podcasts
- #onsite
- #dialyzer
- #docker
- #authentication
- #umbrella
- #full-time-contract
- #podcasts-by-brainlid
- #ecto-query
- #elixir-ls
- #phoenix_html
- #iex
- #blog-post
- #graphql
- #genstage
- #ai
- #websockets
- #supervisor
- #elixirconf-us
- #advent-of-code
- #distillery
- #processes
- #api
- #forms
- #metaprogramming
- #security
- #hex
Our Sponsors
Build Elixir applications with speed and confidence.

Supporting innovation across the BEAM ecosystem.

We build reliable cloud platforms for business-critical systems.

Catch errors, track performance, monitor hosts and more.

Error tracking, logs, uptime, and Just Enough APM. Built for developers.

Develop your skills with books, videos, and courses.

Enabling companies to succeed by building software people love.

The deployment platform built for Elixir: PaaS ease, VPS control.

The team behind Membrane, Popcorn, LiveDebugger. Available for hire.

Courses that'll move you from confusion to "Aha, now I get it!"