
artem
How you would do a cross-aggregate projection with Commanded?
Hi all
I am new to Commanded and whole world of CQRS, trying to evaluate whether it would suite my case. I would appreciate suggestions on how you would do a cross-aggregate projection.
I am thinking about a small specialized Human Resources related service. Candidates submit their resumes, Recruiters submit their vacancies. Commanded and CQRS should work just fine for whichever slices and dices I’d want to have e.g. for listing the highest paying vacancies in a particular field.
But I can’t wrap my head about recommendations. If I have a primitive recommendation engine to recommend candidates with elixir skill to recruiters looking for elixir skill and the other way around, does it essentially mean that I need to build a projection (a PostgreSQL table most probably) on every vacancy/candidate update? Possibly even rebuild the whole table on every small aggregate change?
- Is it normal and expected or am I missing something?
- Or is it conceptually okay to have separate projections for candidates/recruiters and “derive” recommendations by querying them with an sql JOIN? Even if recommendations will become more computationally intensive later (e.g. require calling a machine leaning mode)?
- Or is it a known problem with the known recommendations?
- How would you do it? I will be grateful for any pointers.
Most Liked

tcoopman
Hi Artem,
I think there are multiple solutions to what you’re talking about and they are not as much commanded related, but are practices related to EventSourcing in general.
Most of this depends on how you’re modelling your solution.
Firstly, a side remark that might be not super relevant for your question, but I’d like to add it anyway:
In Domain-Driven Design (DDD) I like to make it very explicit what an aggregate is: An aggregate is responsible to keep certain constraints consistent at all times.
On the other hand in EventSourcing a stream is some logical grouping of events. For example everything that happens on 1 resume, could be a stream, but I would only call it an aggregate when you also have constraints that you need to guard.
So coming back to your question, it now depends on how you model everything.
Is a person a stream? a resume? looking for candidates?
Depending on how you model that, your need for projections will also change.
For example, I guess this would be your default model:

(green is the query, orange events)
But you could also use a process manager:
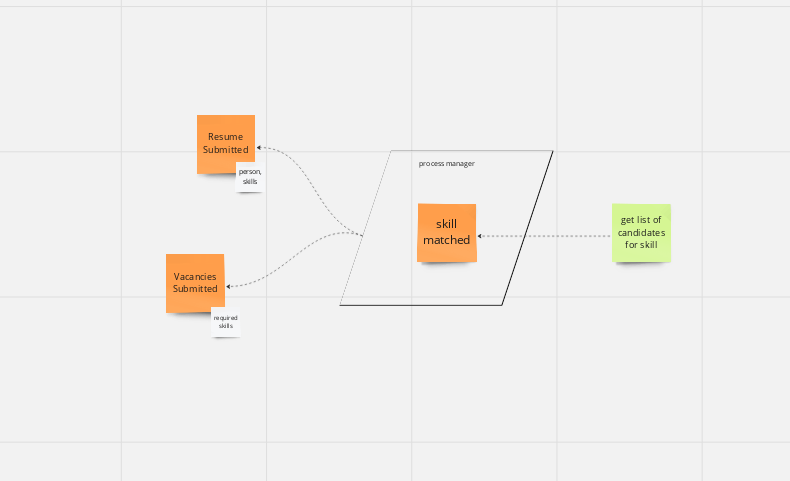
In this case, we have a process manager that links skills and vacancies, so that our projection is a bit simpler.
But we still have a total free choice on what the projection writes. it can be 1 table, multiple tables, it can be multiple projections.
If you want advice on that, I propose that you work out your question in a bit more detail. How do recommendations look like? What information do they need to contain. Why would you have to rebuild the whole table on every change?
Last Post!
artem
Thank you for the explanation and illustrations, @tcoopman !
Indeed, why can’t I query the projections of resumes and vacancies and have matching as a part of a query.
Why would you have to rebuild the whole table on every change?
I somehow had it in my mind that the final projection (or a query to a projection) would be rows of vacancies with matching candidates and the other way around, so for example I was thinking of a projection table sort 'of vacancy having rows like with columns like:
vacancy_id, description, skills_needed, matched_resume_ids_or_even_full_content_as_json_array. With this projection in mind whenever a new resume is posted or removed I guess a system would need not to add a row to a table, but to change/replace the already existing one.
I suppose I would also need to learn how to handle removed/deactivated aggregated. Your image for “resume submitted” events will work perfectly when resumes are only submitted, but now I realize that I will probably need to do something when resume is deactivated for whichever reason (expired, manually unpublished) and I’d want final projections be somehow easily queryable to active resumes only.
Popular in Questions








Other popular topics




Latest on Elixir Forum
Sponsor Spotlight

Catch errors, track performance, monitor hosts and more.
Categories:
Sub Categories:
Forums
Popular Tags
- #ecto
- #liveview
- #troubleshooting
- #learning-elixir
- #deployment
- #library
- #erlang
- #testing
- #genserver
- #mix
- #absinthe
- #remote-other
- #otp
- #plug
- #how-to-question
- #macros
- #postgres
- #channels
- #elixirconf
- #exunit
- #discussion
- #code-sync
- #javascript
- #podcasts
- #onsite
- #dialyzer
- #docker
- #authentication
- #umbrella
- #full-time-contract
- #podcasts-by-brainlid
- #ecto-query
- #elixir-ls
- #phoenix_html
- #iex
- #blog-post
- #graphql
- #genstage
- #ai
- #websockets
- #supervisor
- #elixirconf-us
- #advent-of-code
- #distillery
- #processes
- #forms
- #api
- #metaprogramming
- #security
- #hex
Our Sponsors

Build Elixir applications with speed and confidence.

Supporting innovation across the BEAM ecosystem.

We build reliable cloud platforms for business-critical systems.
Catch errors, track performance, monitor hosts and more.

Error tracking for Elixir devs who love to ship. Start your free account.

Practical resources that improve the lives of professional developers.

Producing high quality Elixir screencasts since 2017.

Enabling companies to succeed by building software people love.

The team behind Membrane, Popcorn, LiveDebugger. Available for hire.

Courses that'll move you from confusion to "Aha, now I get it!"