
bradley
Improving AI Tooling with Ash Documentation
I’ve been developing Ash resources and noticed that while AI tools work well when I provide existing examples, they struggle when creating new resources or tackling less-documented use cases. I’m exploring ways to improve AI responses by incorporating the Ash documentation.
One idea is to use the newly released Model Context Protocol from Anthropic, combined with a Retrieval-Augmented Generation (RAG) system, AWS Bedrock Knowledge Bases, or tools like Cline. This would involve downloading HEX docs for the Ash libraries, feeding them into a RAG system or knowledge base, and making them accessible for AI queries.
However, there are some challenges:
- Ash documentation is extensive, covering multiple libraries within the ecosystem.
- The docs are constantly updated, so I’d need a way to keep them in sync.
Alternatively, I’m considering whether the Model Context Protocol could directly access Ash documentation without requiring the setup and maintenance of a separate RAG system.
While this problem is most noticeable with Ash, it’s not unique to it—it applies to any HEX library. However, Ash is where I’ve experienced the most issues, as LLMs tend to wildly make things up when attempting to assist with it.
Before diving in, I’d like to ask:
- Has anyone tried a similar approach?
- Are there simpler solutions or existing tools for integrating HEX library documentation with LLMs effectively?
Any insights or suggestions would be much appreciated! ![]()
Most Liked

dmitriid
For those interested, Tidewave works:
- follow the installation instructions
- if you’re running in wsl, install mcp_proxy (see docs, the python one worked for me) on windows, not in wsl
- add MCP server to your editor (e.g. Cursor)
"tidewave-phoenix": { "command": "mcp-proxy", "args": [ "http://localhost:4000/tidewave/mcp" ] }
Enjoy.
Here’s a simple rules file I now have in my Cursor that is always loaded:
# Ash Resources and Documentation
- Always use the eval tool to list or introspect Ash resources.
- When documentation about the Ash framework or its features is requested, use package_docs_search to retrieve relevant HexDocs.
And it works:
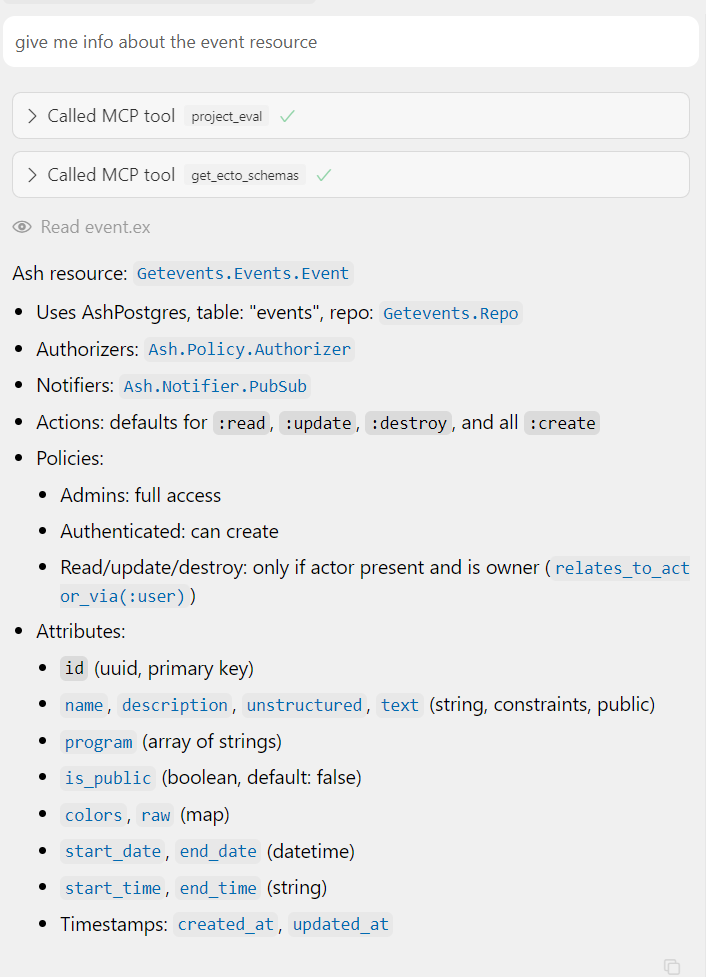
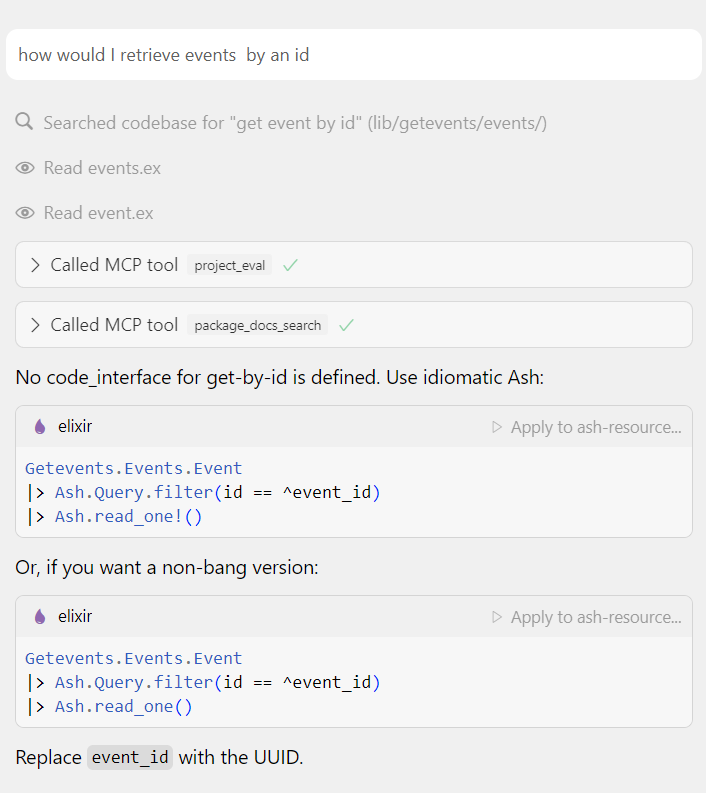

mjrusso
Try this out: https://hex2txt.fly.dev
You’ll want to use the hex2context notebook, which tries to find and include only the most relevant sections of documentation. (I just shipped this ten minutes ago, and there’s tons of opportunities for improvement. Note that the notebook computes all embeddings locally, but swapping in paid models should be relatively trivial. I haven’t tested different embeddings models out yet; any real-world feedback would be super useful.)
To run the notebook: Run - Livebook.dev
Direct link to source: hex2txt/notebooks/hex2context.livemd at main · mjrusso/hex2txt · GitHub
bradley
Just wanted to share an update, @mjrusso. I’ve been using hex2text alongside Cursor’s documentation indexing, and it’s been working pretty well. All I do is point it to the hex2text link for the library I need, and voila! I’d really love to see something like this integrated into Hex proper.
Overall, this workflow is decent, but Cursor’s index doesn’t always get utilized when I expect it to, and it still generates a fair amount of incorrect Ash code. That said, it’s still the best solution I’ve tried so far—better than Windsurfer, Copilot, Zed, Cline, and Aider.
Also, cursor just added support for MCP which is a bonus.
Popular in Questions








Other popular topics





 Latest Ash Threads
Latest Ash Threads
Latest on Elixir Forum
Sponsor Spotlight

Supporting innovation across the BEAM ecosystem.
Categories:
Sub Categories:
Forums
Popular Tags
- #ecto
- #liveview
- #troubleshooting
- #learning-elixir
- #deployment
- #library
- #erlang
- #testing
- #genserver
- #mix
- #absinthe
- #remote-other
- #otp
- #plug
- #how-to-question
- #macros
- #postgres
- #channels
- #elixirconf
- #exunit
- #discussion
- #code-sync
- #javascript
- #podcasts
- #onsite
- #dialyzer
- #docker
- #authentication
- #umbrella
- #full-time-contract
- #podcasts-by-brainlid
- #ecto-query
- #elixir-ls
- #phoenix_html
- #iex
- #blog-post
- #graphql
- #genstage
- #ai
- #websockets
- #supervisor
- #elixirconf-us
- #advent-of-code
- #distillery
- #processes
- #forms
- #api
- #metaprogramming
- #security
- #hex
Our Sponsors

Build Elixir applications with speed and confidence.
Supporting innovation across the BEAM ecosystem.

We build reliable cloud platforms for business-critical systems.

Catch errors, track performance, monitor hosts and more.

Error tracking for Elixir devs who love to ship. Start your free account.

Practical resources that improve the lives of professional developers.

Develop your skills with books, videos, and courses.

Producing high quality Elixir screencasts since 2017.

The team behind Membrane, Popcorn, LiveDebugger. Available for hire.

Courses that'll move you from confusion to "Aha, now I get it!"