I’m trying to figure out how to ingest a stream of messages from an MQTT broker in an efficient way. The problem involves many different sensors that publish a measurement once every minute. A server (one node for now) subscribes to these messages and picks these messages up from the broker. The stream of messages should be partitioned by sensor (so one stream of messages un-bundles into many streams, one for each sensor) so they can be processed separately. Then it would be desirable to have all messages accumulated every period of ten minutes, before they can be handed over to the business logic. The business logic is encapsulated in an OTP process (a GenServer for each sensor). The accumulation is required to calculate an average out of the ten measurements that arrived in each window.
As I’m reading Concurrent Data Processing in Elixir I’m trying to bend my head over this problem and see how my envisioned system maps onto concepts of the Flow library. I’m excluding Broadway here, because I can’t find a mature library that acts as a Broadway producer from an MQTT broker.
Am I on the right track with this? Is Flow a good fit for this use-case? Or is this better solved in the Functional Core (I’m borrowing terms from the Designing Elixir Systems with OTP book). Will Flow allow me to partition(?) the data per sensor, and create windows (or maybe I need triggers here) for each interval of ten minutes, after which I can emit the received messages once the period has passed?
I’m having a hard time understanding the Flow concepts, but I’m getting there (I have read the hexdocs five times by now).
How many sensors are we talking about? Emitting once every minute is slow enough that you should only worry about performance and partitioning if there are enough sensors.
Also what should happen if something fails? Is it ok if you drop messages? What should happen if after 6 minutes your accumulation logic crashes. Is it ok to just restart from the current message or do you need to restart from the first message?
Do you need to store all incoming data for later usage? Or can you just drop it. What about the accumulation, do you need to store that or just emit it somewhere?
These would be the kind of questions I’d ask myself before making a decision on anything. Because they will affect how you want to design your solution.
Depending on some of the answers to the above question. I’d probably start with a MQTT client and handle the logic myself. I don’t know flow so I can’t comment if it would be a good choice for you.
Yes, the averaged measurements would have to end up in a time series database. I was thinking about inserting them in the database as part of the Functional Core.
How many sensors are we talking about? Emitting once every minute is slow enough that you should only worry about performance and partitioning if there are enough sensors.
A few hundred at first, but should be able to scale (I know, the most generic answer ever )
Also what should happen if something fails? Is it ok if you drop messages? What should happen if after 6 minutes your accumulation logic crashes. Is it ok to just restart from the current message or do you need to restart from the first message?
I was hoping for the broker to be able to retain all unacknowledge messages, so they can be re-delivered when something fails. I’ve worked with queues and topics before, but I didn’t delve deep into the possibilities of MQTT brokers yet.
Do you need to store all incoming data for later usage? Or can you just drop it. What about the accumulation, do you need to store that or just emit it somewhere?
Only the averages would need to be retained somewhere, in a time series database.
I don’t know flow so I can’t comment if it would be a good choice for you.
I’m trying to get a feel of how Flow could work here, but I appreciate your feedback.
If you do not need the actual values the time series database can do the aggregation. You can then pull from the DB, which will simplify the architecture.
You suggest to stream the events directly to the database? Didn’t think of that yet
I still need to trigger some business logic when events flow in though, so I don’t know how that would play out in this dorect-to-time-series-db-setup…
Can you save your accumulation after every message or only after 10 messages? Because that will make a big difference if you can let the broker handle unacknowledged messages or not. Basically if you save accumulation after every message then you can acknowledge right after saving. In the other case you’d need to wait 10 minutes. that’s something the message broker probably doesn’t support…
A time series database might definitely be worth looking at, but for me it would depend if the added complexity of the extra database (although there are postgres extensions as well) is worth it.
I’ve built something similarly in the past. With rabbitMq and postgres. I could easily handle 1000s msg/sec on a fairly regular server. Don’t remember the exact details but nothing very beefy was needed.
Can you save your accumulation after every message or only after 10 messages? Because that will make a big difference if you can let the broker handle unacknowledged messages or not. Basically if you save accumulation after every message then you can acknowledge right after saving. In the other case you’d need to wait 10 minutes. that’s something the message broker probably doesn’t support…
I want to checkpoint after every message (not only after aggregating over ten minutes), so no need to have long-running transactions, or something like that, before acknowledging (does it even work that way, with MQTT brokers?).
A time series database might definitely be worth looking at, but for me it would depend if the added complexity of the extra database (although there are postgres extensions as well) is worth it.
TimescaleDB is on my radar
I’ve built something similarly in the past. With rabbitMq and postgres. I could easily handle 1000s msg/sec on a fairly regular server. Don’t remember the exact details but nothing very beefy was needed.
That would be a nice end-game: being able to process a constant stream of events at this rate.
I’m not familiar enough with them to answer for sure, but I think the protocol supports acknowledgement by the client. Of course the broker needs to support it as well, and it needs to be activated (because there is overhead involved of course)
yes you can make sure, that the MQTT-client has at least once received the message, but as I understand it OP wants to manually ACK when a message is processed.
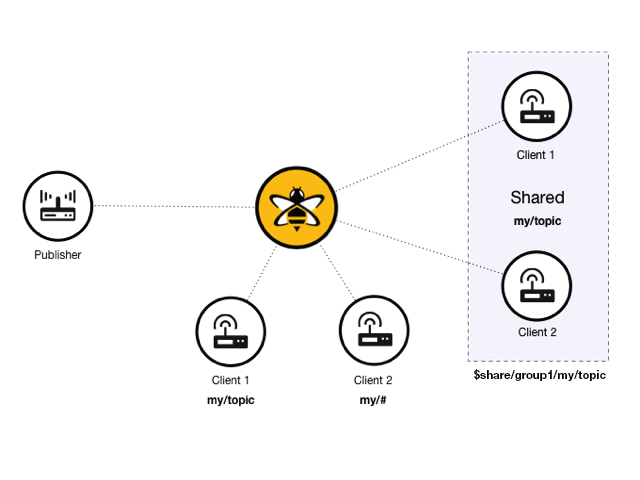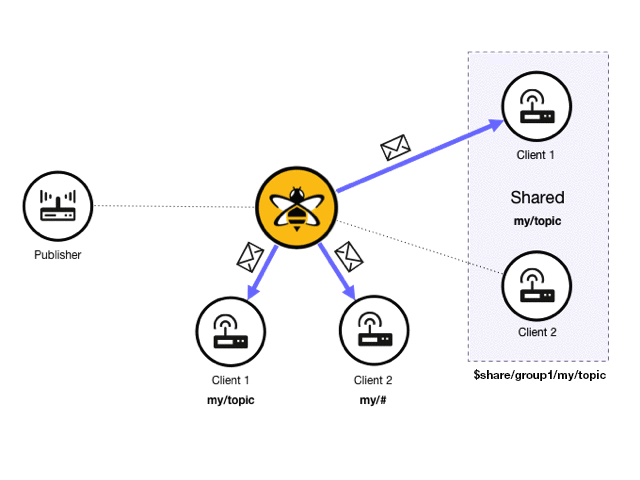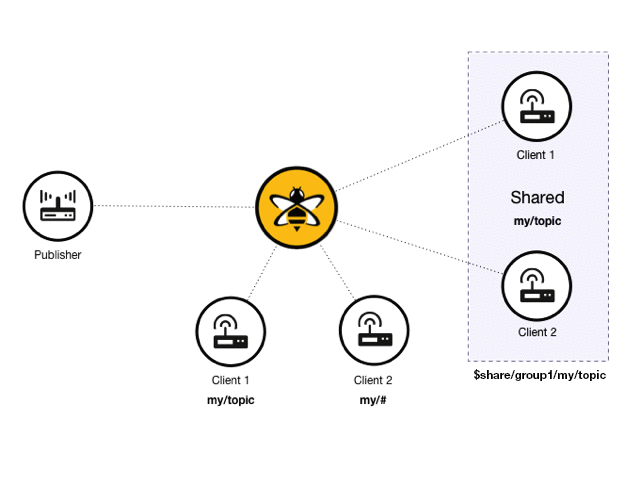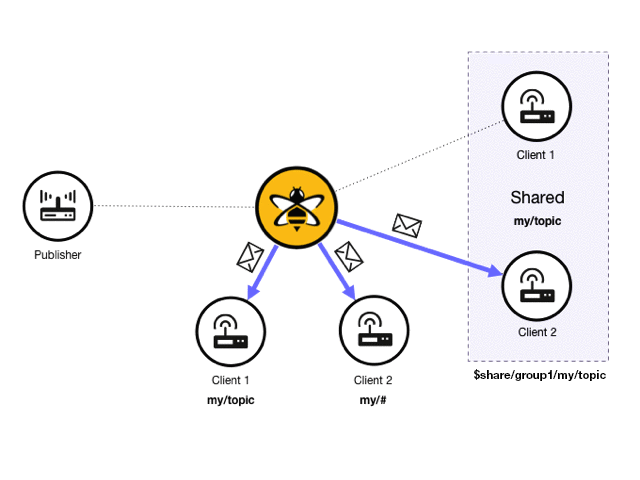
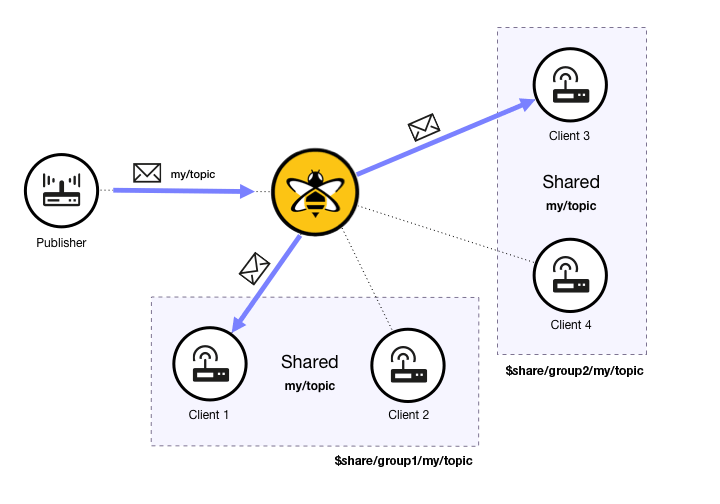
Shared subscriptions are an MQTT v5 feature that allows MQTT clients to share the same subscription on the broker. In standard MQTT subscriptions, each subscribing client receives a copy of each message that is sent to that topic. In a shared subscription, all clients that share the same subscription in the same subscription group receive messages in an alternating fashion. This mechanism is sometimes called client load balancing , since the message load of a single topic is distributed across all subscribers.
HiveMQ is architected for scale and reliability. MQTT broker scales up to 10 million connected devices and uses industry standards to ensure data is not lost.
Followed by Genstage based Flow
To intercept and perform business logic before storage.
Use Clickhouse for Timeseries storage
It’s an OLAP + Time series db, faster than Timescale & Influx DB.
This is just plain marketing. This is not a USP of HiveMQ, all serious brokers do that, see EMQX, Verne.
And if you have any special needs for auth I’d look closely how HiveMQ handles that.
I have no affiliation with any of the tech I put in my reply.
What I meant was:
Lots of IoT → Message Queue to take the blunt of force → Genstage for backpressure while ingesting data → Fast storage with capability to take writes fast.
Else
IoT → Some Broadway compatible Message Queue → App → Fast storage
—-
P.S. I have no experience with IoT, backend, complex system design.
—-
P.P.S. Checkout how Plausible Analytics ingest data into Clickhouse.
Just a quick plug for VictoriaMetrics as time series DB. I’m evaluating it for my needs right now. It’s designed to be a “better” backend for grafana metrics. One of it’s features that I needed was arm 32bit support