
markmark206
Journey – simpler scalability, reliability, and postgres-based persistence, with self-computing graphs
Every time I build a web app, I worry about a bunch of basic things (persisting data, knowing when to compute which things, keeping things working smoothly and reliably across reboots / crashes / redeployments / scaling / page reloads, etc, running scheduled one-time or – god forbid! – recurring things reliably, keeping my code simple and maintainable, understanding the history of user’s interactions with the app, and general stats, etc.)
I got tired of doing this over and over again, and I built a package, Journey, which, backed by Postgres-based persistence, provides these things. This made my web applications extremely simple and easy to build, run, and maintain. And! No additional infrastructure or online service subscription is required – it’s just my application and my postgres database!!
I thought I would publish the package, and share it here, in case anyone else finds this useful, or has any thoughts or feedback, or interesting use cases,
With Journey, the code of my apps is cleanly split into 1. “business logic” (the functions that do things, e.g. compute horoscopes, send emails or texts, make credit approval decisions, etc.), AND 2. the graph defining the flow of the application.
Then my liveview (for example) creates graph executions for users that go through the flow, and use those executions to save user-supplied values, and to read computed values to be rendered.
I put together a tiny liveview demo website that “computes” your “horoscope” (https://demo.gojourney.dev/), together with its source (GitHub - shipworthy/journey_horoscopes: An example LiveView app built on Journey. · GitHub). Notice how thin the liveview component is, esp given how “state-rich” the web page is.
If you just want a quick glance, here is an over-simplified (no scheduling, no clearing “PII”) version that captures its essence:
- the “business logic”:
defmodule MyBusinessLogic do
def compute_zodiac_sign(%{month: month, day: day}) do
IO.puts("compute_zodiac_sign: month: #{month}, day: #{day}")
my_sign = "Pisces"
{:ok, my_sign}
end
def compute_horoscope(%{zodiac_sign: zodiac_sign, first_name: first_name}) do
IO.puts("compute_horoscope: zodiac_sign: #{zodiac_sign}, first_name: #{first_name}")
horoscope = "#{first_name}, as a #{zodiac_sign}, you are skeptical of horoscopes. Expect a lovely surprise."
{:ok, horoscope}
end
end
- the graph defining the application’s inputs, computations and dependencies.
defmodule MyGraph do
import Journey.Node
def graph() do
Journey.new_graph(
"tiny horoscope example",
"v1.0.98",
[
input(:first_name),
input(:month),
input(:day),
compute(
:zodiac_sign,
[:month, :day],
&MyBusinessLogic.compute_zodiac_sign/1
),
compute(
:horoscope,
[:first_name, :zodiac_sign],
&MyBusinessLogic.compute_horoscope/1
)
],
f_on_save: fn execution_id, node_name, {:ok, result} ->
IO.puts("f_on_save: '#{execution_id}' value computed and saved: '#{node_name}' '#{result}'")
# Notify the liveview.
# Phoenix.PubSub.broadcast(...)
end
)
end
end
- executing instances of the graph
When a user interacts with the web page, my Liveview creates a graph’s execution for the user’s visit, sets inputs to it, and reads and renders computed values.
iex(3)> execution = Journey.start_execution(MyGraph.graph()); :ok
:ok
iex(4)> execution = Journey.set_value(execution, :day, 10); :ok
:ok
iex(5)> execution = Journey.set_value(execution, :month, 3); :ok
compute_zodiac_sign: month: 3, day: 10
:ok
f_on_save: 'EXECYJ43AG4X6HM3RJ518651' value computed and saved: 'zodiac_sign' 'Pisces'
iex(6)> execution = Journey.set_value(execution, :first_name, "Mario"); :ok
compute_horoscope: zodiac_sign: Pisces, first_name: Mario
:ok
f_on_save: 'EXECYJ43AG4X6HM3RJ518651' value computed and saved: 'horoscope' 'Mario, as a Pisces, you are skeptical of horoscopes. Expect a lovely surprise.'
iex(7)> Journey.values(execution)
%{
month: 3,
day: 10,
last_updated_at: 1755848525,
execution_id: "EXECYJ43AG4X6HM3RJ518651",
zodiac_sign: "Pisces",
first_name: "Mario",
horoscope: "Mario, as a Pisces, you are skeptical of horoscopes. Expect a lovely surprise."
}
If this sounds interesting to anyone, I am very interested in hearing your thoughts, questions, feedback, comments, use cases.
Here is where you can find journey:
Hexpm: Journey v0.10.57 — Documentation
Github repo: GitHub - shipworthy/journey: Durable Workflows in a[n Elixir] package. · GitHub
Demo website: https://demo.gojourney.dev/
Demo website source: GitHub - shipworthy/journey_horoscopes: An example LiveView app built on Journey. · GitHub
Thank you!
Mark.
PS When thinking about sharing Journey, I decided to play with a dual-license approach (free for projects with revenues under US$10k/month, with a small build key fee for other uses). I am curious if this might be an interesting approach for other current or future library developers, who might want to contribute to the Elixir (or some other) ecosystem, but are protective of their uncompensated time. If anyone has thoughts / questions / feedback on this, I am very interested to hear it!
PPS While the source code for the package is available, the dual-license approach means that this is not OSS, so I am posting it here, rather than in “Libraries”.
Most Liked
markmark206
Ah, this is a great question, thank you for asking, and thank you for bearing with me as I am figuring out how to describe this!
In my experience, Journey solves the accidental complexity of a lot of web applications. It handles a lot of the plumbing that I keep rebuilding, that’s not part of my app’s actual business logic. Things like:
Persistence and Recovery
- figuring out how to persist and recover user sessions, across reboots, outages, redeployments, page reloads, etc.,
- figuring out how to let my users resume their flow a month later.
Orchestration and Reliability
- figuring out when to compute what,
- figuring out how to do reliable one-time and recurring scheduling that survives redeployments and outages,
- figuring out how to do reliable retries when my application redeploys while anthropic has an outage (for example;),
- figuring out how to do all of these things as my application runs on multiple replicas, and scales up and down.
Observability and Insights
- figuring out what’s happening with a specific user (“Did Mario get approved?”),
- figuring out how to get business insights into my application (“what percentage of users got pre-approved, but didn’t claim the offer?”).
Code Simplicity
- figuring out how to structure my code so it (and my brain) does not turn into mashed potatoes over time,

- figuring out how to structure my code so its essence is easy to understand for both LLMs and humans (and fits into our tiny context windows;),
- figuring out how to manage the complexity of it all – making sure all of the pieces actually work together as i think they do.
I got tired of solving the same problems in every project, so I built Journey – it lets me describe my application as a graph, and then runs executions of the graph, while handling all of those things for me.
Let me make it a bit more specific. I’ll show a basic example to illustrate basic concepts, and then extrapolate to more practical applications.
Let’s say my amazing “hello and goodbye” app says “hello” and “goodbye” to everyone who visits my website.
The graph for this website has three nodes. The value of :name is provided by the visitor. The values of :hello and :goodbye are computed by the functions attached to the nodes.
~/src/journey $ iex -S mix
Erlang/OTP 27 [erts-15.1.2] [source] [64-bit] [smp:10:10] [ds:10:10:10] [async-threads:1] [jit]
Interactive Elixir (1.18.3) - press Ctrl+C to exit (type h() ENTER for help)
iex(1)> import Journey.Node
iex(2)> graph =
...(2)> Journey.new_graph("hello and goodbye", "v1.0.0", [
...(2)> # :name input node.
...(2)> input(:name),
...(2)> # :goodbye computation node, waits for :name
...(2)> compute(:hello, [:name], fn %{name: name} -> {:ok, "Hello, #{name}!"} end),
...(2)> # ':goodbye' computation node, waits for :hello and :name
...(2)> compute(:goodbye, [:hello, :name], fn %{name: name, hello: _} -> {:ok, "Goodbye, #{name}!"} end)
...(2)> ])
This graph now serves as the blueprint for my application.
Whenever a visitor enters their name, the application starts a new execution – a running instance – of the graph.
iex(3)> execution = Journey.start_execution(graph)
and saves the visitor’s name as the value of the :name node:
iex(4)> execution = Journey.set_value(execution, :name, "Mario")
(Journey handles persisting the execution’s values and invoking its functions.)
Now that :name has a value (“Mario”), Journey will call the function attached to :hello node, and its value becomes available (and my UI can now render it to my visitor;):
iex(5)> Journey.get_value(execution, :hello, wait_new: true)
{:ok, "Hello, Mario!"}
Now that :hello has a value, following the definition of the graph, Journey will call the function attached to :goodbye, and :goodbye’s value will also becomes available:
iex(6)> Journey.get_value(execution, :goodbye, wait_new: true)
{:ok, "Goodbye, Mario!"}
If at any point things got interrupted (our infrastructure crashed, user reloaded their page, user left and came back a year later), as long as we took a note of the execution’s id (e.g. by putting it in the url of the browser),
iex(7)> execution.id
"EXEC3XJVY5ZRX8BHYAYH0E3Y"
we will simply reload it when things are back up
iex(8)> execution = Journey.load("EXEC3XJVY5ZRX8BHYAYH0E3Y")
and continue where we left off
iex(9)> Journey.values(execution)
%{
name: "Mario",
last_updated_at: 1756270543,
execution_id: "EXEC3XJVY5ZRX8BHYAYH0E3Y",
hello: "Hello, Mario!",
goodbye: "Goodbye, Mario!"
}
Hopefully, this example made my earlier statement more specific:
it lets me describe my application as a graph, and then runs executions of the graph
To start extrapolating this to a more complex, real-life application, consider this graph, illustrating an example credit card approval process.
Let me call out a few things, around rich dependencies, some useful types of nodes (schedules, mutations), retries, and tools for introspection.
1. rich dependencies
in the “hello and goodbye” application, computations are unblocked as long as the upstream values have been provided. these dependencies could be more expressive
compute(:congratulate, unblocked_when({:preapproval_decision, &approved?/1}), &Compute.send_congrats/1),
and
compute(
:send_preapproval_reminder,
unblocked_when({
:and,
[
{:schedule_request_credit_card_reminder, &provided?/1},
{:not, {:credit_card_requested, &true?/1}}
]
}),
&Compute.send_preapproval_reminder/1
),
2. mutations
In this example, :ssn_redacted mutate node mutates the value of another node – as soon as :credit_score has been provided, the value of ssn is redacted, to protect the user’s PII.
mutate(:ssn_redacted, [:credit_score], fn _ -> {:ok, "<redacted>"} end, mutates: :ssn),
(re: “ssn” – apologies for the US-centric example, our Social Security Numbers… long story, let’s just say they are a problem.)
3. schedules (one-time)
schedule_once nodes unblock downstream nodes at the computed time (across reboots, redeployments, restarts, etc ).
(For example, :send_preapproval_reminder can be triggered a week after :congratulate. message was sent, if the customer did not request the card.
schedule_once(
:schedule_request_credit_card_reminder,
[:congratulate],
&Compute.choose_the_time_to_send_reminder/1
),
...
compute(
:send_preapproval_reminder,
unblocked_when({
:and,
[
{:schedule_request_credit_card_reminder, &provided?/1},
{:not, {:credit_card_requested, &true?/1}}
]
}),
&Compute.send_preapproval_reminder/1
),
4. schedules (recurring)
schedule_recurring nodes let you schedule things to happen recurrently (across reboots, redeployments, restarts, etc )
5. Tools for introspection (individual executions and system-wide)
“What happened with Mario’s application?”
Journey.Tools.summarize_as_text(execution) gives you an instant answer – what data has been provided, what data has been computed, what computations are blocked and why. To see it in action, go to https://demo.gojourney.dev/ and search for “Execution summary” in the “behind the scenes” view.
"Where are my users dropping off?”
You can look through executions to understand your customer’s behavior – you get analytics insights into your business process (“What percentage of your users entered their name but never proceeded to SSN?” “What percentage of users got the :send_preapproval_reminder reminder?” etc.)?
Journey.Insights.FlowAnalytics.to_text provides some initial insights, richer flow analytics is on its way.
To see this in action, go to https://demo.gojourney.dev/ and look for “Analytics (as text)” under “behind the scenes”,
6. Code Structure / Readability
Journey gives the code a neat structure. The workflow is defined in the graph. Most of the business logic can be defined in the “compute” functions attached to the graph’s compute nodes.
LLMs seem to be good at “here is journey documentation. here is my journey graph. explain what this application does. here is the output of summarize(). why did mario not get a reminder?”
7. Computation Retries
The functions attached to computation nodes are executed with retries. So if your :extract_attributes_from_candidates_resume computation failed because anthropic had an outage, it will retry, with a customizable retry policy – even if your own application was redeployed or otherwse restarted.
If the outage lasted all day, and the computation’s retry policy got exhausted, Journey.Tools.retry_computation/2 lets you re-kick the computation the next day.
Here is a tiny example of the code that re-tries a computation after normal retries were exhausted, from https://demo.gojourney.dev/
updated_execution =
Journey.Tools.retry_computation(
socket.assigns.execution_id,
String.to_existing_atom(node_name)
)
This retry logic persists across reboots / restarts / etc. Extrapolating OTP terminology, Journey uses DB-based, persisted supervision for running node computations.
A word of warning: while I found this functionality to be extremely useful in my production applications, this current incarnation of this package is relatively new. The upside is that I am actively working on refining its functionality, scalability, documentation, and developer experience, and if Journey is a good fit for your application, I am very interested in making sure it works well for you.

NFHorizon
I’m not quite understand what problem this repo aim to solve. do you mind show me more complex case? I’m excited to use new things to simplify my codes

dimitarvp
Hey, I remember I quite liked this idea. OP, are you still actively working on it? Any updates?
(I can see there are movements on GitHub but a quick glance does not tell me much of their significance and scope.)
Last Post!
markmark206
Yes, still actively working on this!
The current version of Journey works great, so I’ve been focusing on building and running applications with Journey, and planning and making iterative improvements (performance and scaling, dev ergonomics, refactoring).
I wish I had more time for examples and blog posts on this, but I did put together an example LiveView “Food Delivery” application, “JourDash” (sorry;).
You can run some “food deliveries” here: https://jourdash.gojourney.dev/
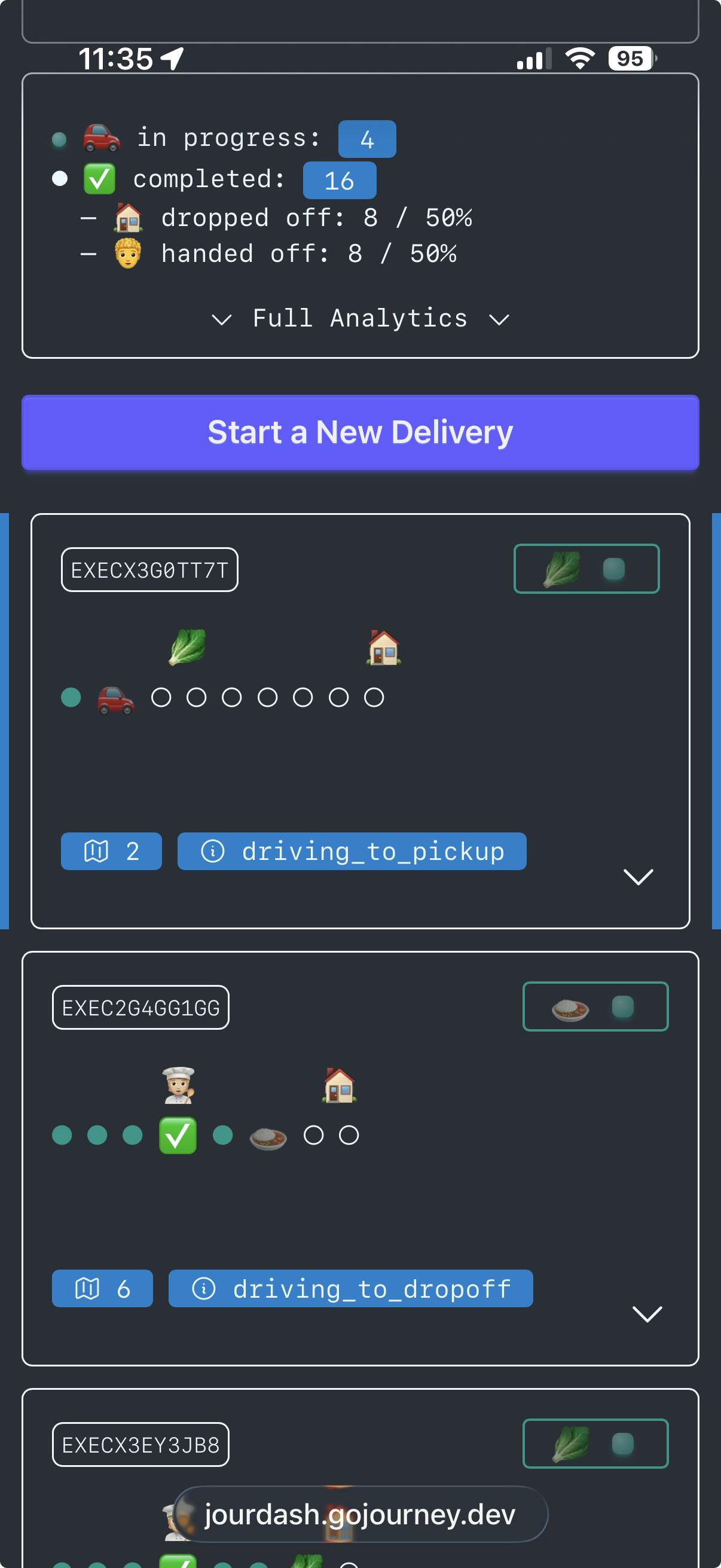
Journey does most of the heavy lifting in this application (the workflow engine, durable executions, persistence, scheduling, retry logic, basic analytics). So the code in the application is mostly just
- the definition of the graph and its computations +
- a bit of code running executions of the graph,
- the UI code. <<<< this is most of the code.
You can see the graph in JourDash’s github repo: jour_dash/lib/jour_dash/trip/graph.ex at main · shipworthy/jour_dash · GitHub .
As a side note, funny enough, LLMs seem to be great at looking at Journey graphs and answering questions like “What is this?”, “What is the business logic implemented by the graph?”, “What does Journey provide in this application?”, and “How much code would the application need to implement without Journey?”
If you are thinking of building something where Journey might be a good tool, I am happy to help (or help brainstorm)! Also, super-interested in feedback, ideas, suggestions for improvement.
PS And I did put together a goofy example of making a Useless Machine with Journey: Building a Useless Machine in Elixir - DEV Community
Popular in Discussions






Other popular topics





Chat & Discussions>Discussions
Latest on Elixir Forum
Sponsor Spotlight

Catch errors, track performance, monitor hosts and more.
Categories:
Sub Categories:
Forums
Popular Tags
- #ecto
- #liveview
- #troubleshooting
- #learning-elixir
- #deployment
- #library
- #erlang
- #testing
- #genserver
- #mix
- #absinthe
- #remote-other
- #otp
- #plug
- #how-to-question
- #macros
- #postgres
- #channels
- #elixirconf
- #exunit
- #discussion
- #code-sync
- #javascript
- #podcasts
- #onsite
- #dialyzer
- #docker
- #authentication
- #umbrella
- #full-time-contract
- #podcasts-by-brainlid
- #ecto-query
- #elixir-ls
- #phoenix_html
- #iex
- #blog-post
- #graphql
- #genstage
- #ai
- #websockets
- #supervisor
- #elixirconf-us
- #advent-of-code
- #distillery
- #processes
- #api
- #forms
- #metaprogramming
- #security
- #hex
Our Sponsors

Build Elixir applications with speed and confidence.

Supporting innovation across the BEAM ecosystem.

We build reliable cloud platforms for business-critical systems.
Catch errors, track performance, monitor hosts and more.

Error tracking, logs, uptime, and Just Enough APM. Built for developers.

Practical resources that improve the lives of professional developers.

Develop your skills with books, videos, and courses.

Enabling companies to succeed by building software people love.

The team behind Membrane, Popcorn, LiveDebugger. Available for hire.

Courses that'll move you from confusion to "Aha, now I get it!"