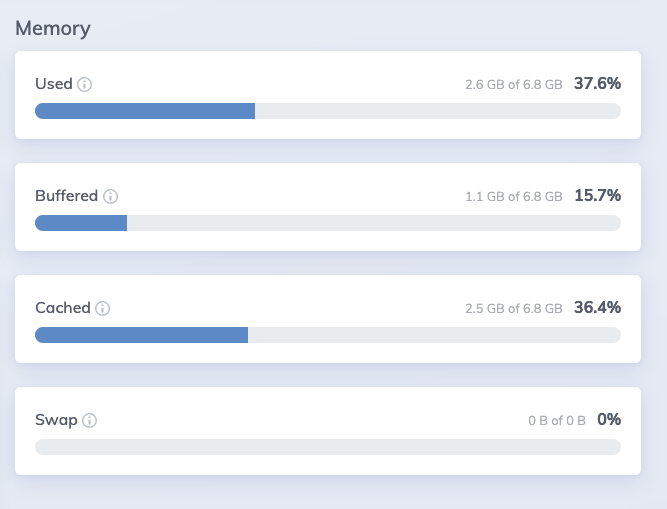
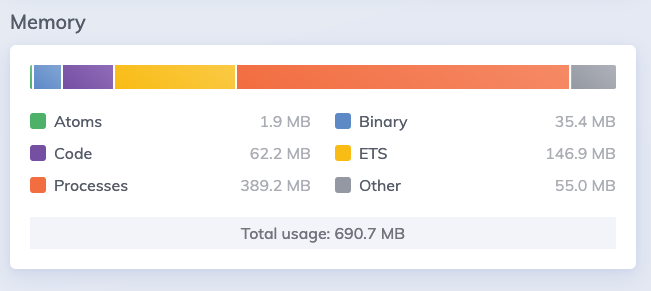
I had similar issues and would be interested to find a solution, but I didn’t find such flag.
In fact, figuring out which processes were even responsible for allocating memory was difficult on BEAM.
I ended up sampling the state of the system every 30s or so and be warned if we detect a process that exceeds something like 15 MB of memory.
The code I’m using is something like:
defmodule Infra.Bloat.Find do
@info_keys [
:current_function,
:initial_call,
:status,
:message_queue_len,
:links,
:dictionary,
:trap_exit,
:error_handler,
:priority,
:group_leader,
:total_heap_size,
:heap_size,
:stack_size,
:reductions,
:garbage_collection,
:suspending,
:memory
]
@fifteen_megs 1024 * 1024 * 15
def processes do
Process.list()
|> Enum.map(fn pid ->
Process.info(pid, @info_keys)
end)
|> Enum.filter(&(&1[:memory] && &1[:memory] >= @fifteen_megs
end
end
I run Infra.Bloat.Find every 30s and log if something was found. Then, I look at the logs and if something showed up I fix the memory leak.
The usual suspects, according to my experience are:
- long running GenServers that do very little work, preventing GC from kicking in. Suspending these processes when idle does the job here.
- Absinthe GraphQL resolvers that were written in naive way, basically exploding the returned size of the payload and / or doing a lot of N+1 queries. Data loader / and / or adding pagination to these helps a lot.
- processing uploaded files, and/or processing JSON. I ended up writing a pretty shitty streaming subset of JSON parser because of the API I’m using tends to return super large arrays of things in JSON and this was crashing the system easily.
With GraphQL resolvers or just a web requests that are crashing your pod, you need to know that BEAM is able to allocate a lot of memory very very fast, so you won’t catch all of such spikes. Some will kill your pod, others won’t but will go unnoticed, so I ended up just running the sampling code constantly on production and making sure nothing new exceeds the arbitrary memory limit I’ve set up. This seems to work really well at scale and I am able to detect memory leak issues before they are the problem.