
leandrocp
MDEx - Fast and Extensible Markdown
MDEx is a fast and extensible Markdown parser and formatter.
Fast
Leverage Rust to parse, manipulate and render documents using:
- comrak - a Rust port of the official GitHub markdown library compliant with the CommonMark spec.
- ammonia - HTML sanitization.
- autumnus - syntax highlighter powered by Tree-sitter and Neovim themes.
Extensible
A Req-like API to manipulate documents in a pipeline with support for plugins, for eg mdex_mermaid
Features
- Fast
- Compliant with the CommonMark spec
- Plugins
- Formats:
- Markdown (CommonMark)
- HTML
- JSON
- XML
- Quill Delta
- Floki-like Document AST
- Req-like Document pipeline API
- GitHub Flavored Markdown
- Discord and GitLab Flavored-ish Markdown
- Wiki-style links
- Streaming incomplete fragments
- Emoji shortcodes
- Built-in Syntax Highlighting for code blocks
- Code Block Decorators
- HTML sanitization
- ~MD Sigil for Markdown, HTML, JSON, XML, and Quill Delta
First Post!

Eiji
Very interesting package with lots of features that took my attention! Here are just a few questions/suggestions:
-
It would be nice to see a comparison table with existing solutions like
Earmark- short summary side-by-side sometimes does more than thousands of words -
Would it be hard to add support for a custom markdown rules or even custom sets of rules (other markdown syntax - if any)? For example see how many interesting features adds
ex_docto the markdown. It’s import to answer if using your library developer could do the same thing. Would it be harder or simpler? -
Would it be hard to add support for
Earmark(and other packages)? Imagine a case where there is a critical bug in theRustparser - forElixirapp it means stopping entire app.
If people would prefer your solution then sooner or later they may ask such a questions … Maybe this is not the same kind of feedback you are interested, but since writing parser is not trivial and especially because Earmark is in the ecosystem for a many, many years people working in production may ask you such type of questions.
Instead of forcing something new (i.e. something unknown) it’s always better to provide something that can fallback in the worst case. This often helps in migrating a big part of a project.
Most Liked
leandrocp
MDEx v0.9 is now available with some new cool features!
Delta format
Thanks to @Jskalc we can now convert Markdown to Delta:

Streaming
Initial (experimental) support to put incomplete fragments of Markdown into the document. Useful for AI/LLM tools:

You can see a demo (video) at Leandro Pereira on X: "Here's a short demo of Markdown streaming in MDEx 👀 Note it's still experimental and disabled by default. https://t.co/uEdEEalbb8" / X
Inspect Document as a tree
To help visualize the nodes in a document:
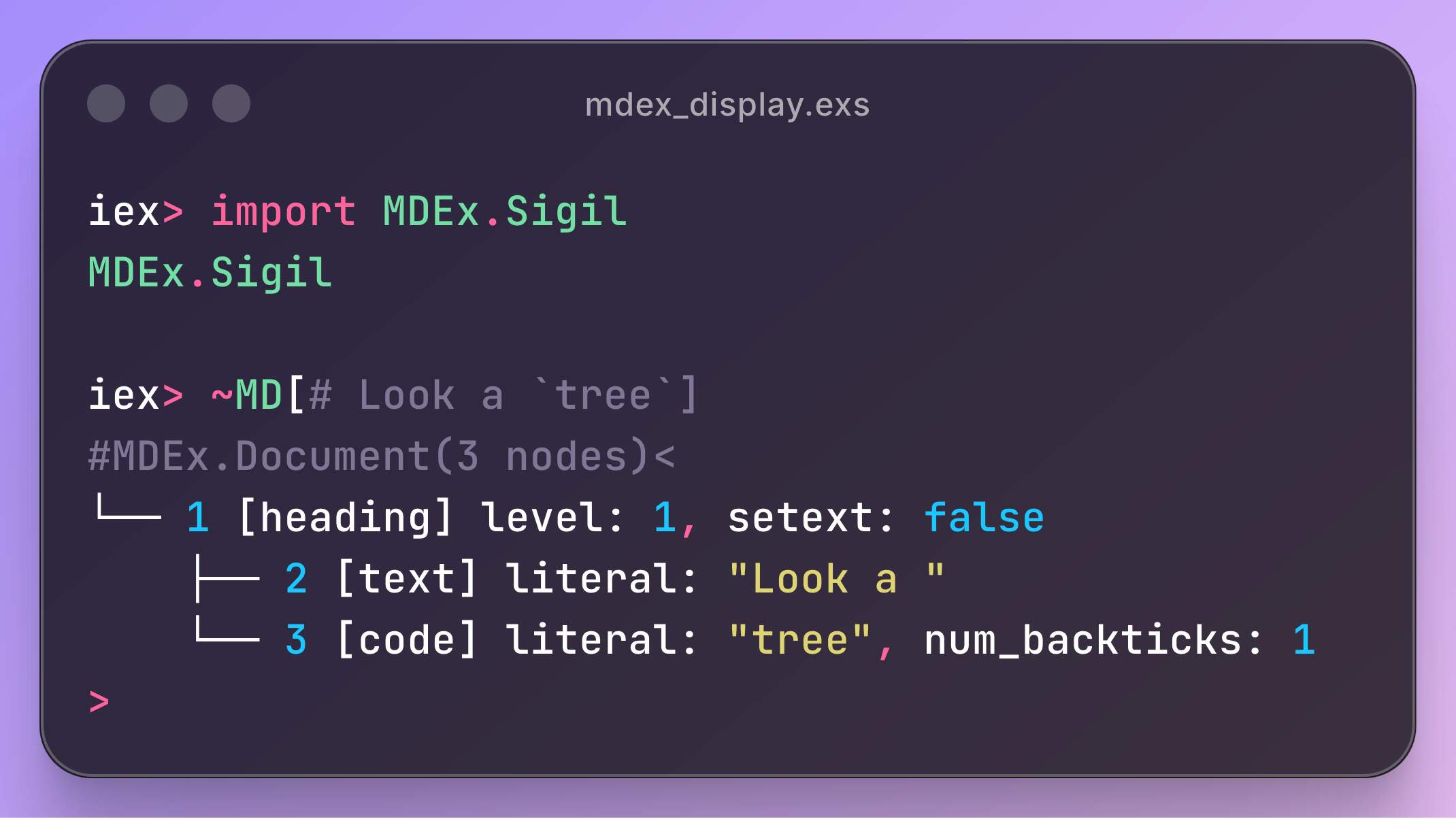
It can be disabled if you prefer the regular struct inspect.
Unified Document API
Removed the MDEx.Pipe module in favor of unifying all operations in the MDEx.Document. Note this is a breaking change:

I’ll be working on Support Phoenix tags? · Issue #571 · kivikakk/comrak · GitHub so we can (hopefully) get Elixir and Phoenix components rendering inside Markdown. Enjoy!
leandrocp
MDEx v0.7.0 is out with a new ~MD sigils supporting assigns and Elixir expressions:
import MDEx.Sigil
assigns = %{lang: "elixir", sample: "spawn(fn -> send(current, {self(), 1 + 2}) end)"}
~MD"""
## Lang: <%= String.capitalize(@lang) %>
```elixir
<%= @sample %>
```
"""
Outputs:
%MDEx.Document{
nodes: [
%MDEx.Heading{nodes: [%MDEx.Text{literal: "Lang: Elixir"}], level: 2, setext: false},
%MDEx.CodeBlock{
nodes: [],
fenced: true,
fence_char: "`",
fence_length: 3,
fence_offset: 0,
info: "elixir",
literal: "spawn(fn -> send(current, {self(), 1 + 2}) end)\n"
}
]
}
Or using the HTML modifier:
"<h2>Lang: Elixir</h2>\n<pre class=\"athl\" style=\"color: #abb2bf; background-color: #282c34;\"><code class=\"language-elixir\" translate=\"no\" tabindex=\"0\"><span class=\"line\" data-line=\"1\"><span style=\"color: #61afef;\">spawn</span><span style=\"color: #848b98;\">(</span><span style=\"color: #c678dd;\">fn</span> <span style=\"color: #abb2bf;\">-></span> <span style=\"color: #61afef;\">send</span><span style=\"color: #848b98;\">(</span><span style=\"color: #abb2bf;\">current</span><span style=\"color: #848b98;\">,</span> <span style=\"color: #848b98;\">{</span><span style=\"color: #61afef;\">self</span><span style=\"color: #848b98;\">(</span><span style=\"color: #848b98;\">)</span><span style=\"color: #848b98;\">,</span> <span style=\"color: #d19a66;\">1</span> <span style=\"color: #abb2bf;\">+</span> <span style=\"color: #d19a66;\">2</span><span style=\"color: #848b98;\">}</span><span style=\"color: #848b98;\">)</span> <span style=\"color: #c678dd;\">end</span><span style=\"color: #848b98;\">)</span>\n</span></code></pre>"
That’s one step into the direction of supporting Markdown in LiveViews with components.
leandrocp
MDEx v0.11 is out with 2 new cool features:
- Initial support for Phoenix Components
Now you can render Phoenix Components inside Markdow, either inside a LiveView or just use the ~MD[...]HEEX sigil. Example:
def render(assigns) do
~MD"""
Hello from MDEx :wave:
Today is _{Calendar.strftime(DateTime.utc_now(), "%B %d, %Y")}_
<ReqEmbed.embed url={@video_url} class="aspect-video rounded-xl my-6" />
Built with:
- <.link href="https://crates.io/crates/comrak">comrak</.link>
- <.link href="https://hex.pm/packages/mdex">MDEx</.link>
"""HEEX
end
More info at Phoenix LiveView HEEx — MDEx v0.13.2
- Syntax Highlighter with Light/Dark themes
The syntax highlighting engine now supports dual/multi themes so you can have automatic light/dark themes:
options = [
syntax_highlight: [
formatter: {
:html_multi_themes,
themes: [light: "github_light", dark: "github_dark"],
default_theme: "light-dark()"
}
]
]
Full example at Lumis light/dark theme — MDEx v0.13.2
I’m also opening a sponsorship program if you want to support MDEx in that way please see GitHub - leandrocp/mdex: Markdown for Elixir. Fast, Extensible, Phoenix-native. AI-ready. Built on top of comrak, ammonia, and lumis. · GitHub
Last Post!
leandrocp
Popular in Announcing







Other popular topics





Latest on Elixir Forum
Sponsor Spotlight

Producing high quality Elixir screencasts since 2017.
Categories:
Sub Categories:
Forums
Popular Tags
- #ecto
- #liveview
- #troubleshooting
- #learning-elixir
- #deployment
- #library
- #erlang
- #testing
- #genserver
- #mix
- #absinthe
- #remote-other
- #otp
- #plug
- #how-to-question
- #macros
- #postgres
- #channels
- #elixirconf
- #exunit
- #discussion
- #code-sync
- #javascript
- #podcasts
- #onsite
- #dialyzer
- #docker
- #authentication
- #umbrella
- #full-time-contract
- #podcasts-by-brainlid
- #ecto-query
- #elixir-ls
- #phoenix_html
- #iex
- #blog-post
- #graphql
- #genstage
- #ai
- #websockets
- #supervisor
- #elixirconf-us
- #advent-of-code
- #distillery
- #processes
- #api
- #forms
- #metaprogramming
- #security
- #hex
Our Sponsors

Build Elixir applications with speed and confidence.

Supporting innovation across the BEAM ecosystem.

We build reliable cloud platforms for business-critical systems.

Catch errors, track performance, monitor hosts and more.

Error tracking, logs, uptime, and Just Enough APM. Built for developers.
Producing high quality Elixir screencasts since 2017.

Enabling companies to succeed by building software people love.

The deployment platform built for Elixir: PaaS ease, VPS control.

The team behind Membrane, Popcorn, LiveDebugger. Available for hire.

Courses that'll move you from confusion to "Aha, now I get it!"