I have an app that is misbehaving. It’s deployed to Gigalixir and there are two problems with it as far as I can tell: one is that it has mysterious memory spikes that are causing OOM / killed problems, the other one is a slow binaries leak when I make HTTP requests to download external files.
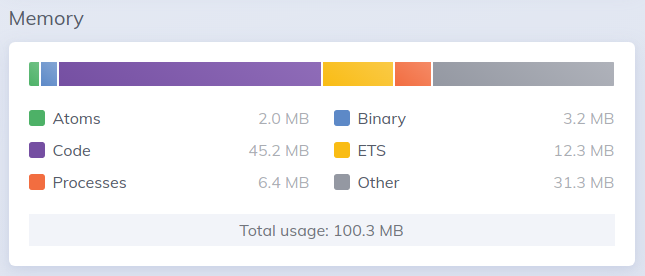
While I am struggling with the first issue, maybe the solution to the second will soft out the first too. So the bin leak issue can be easily observed on the app. Freshly after it’s deployed, Phoenix LiveDashboard shows minimal memory usage:
Now, the only thing I have to do to cause trouble is to download some files, and it doesn’t matter how I really do it. I can use HTTPoison with sync or async response, or I can use Mojito / Mint. I don’t have to write files to disk, I can ignore them. I can download them in a spawned process / Task, and never care about return value. The memory used by BEAM on the server just keeps growing.
For example, when I do several HTTP requests like this, to download a 17MB file, and completely ignore it:
iex> task = Task.async(fn -> Mojito.get(url, [auth]); :ok end); Task.await(task)
:ok
iex> task = Task.async(fn -> Mojito.get(url, [auth]); :ok end); Task.await(task)
:ok
iex> task = Task.async(fn -> Mojito.get(url, [auth]); :ok end); Task.await(task)
:ok
iex> task = Task.async(fn -> Mojito.get(url, [auth]); :ok end); Task.await(task)
:ok
iex> task = Task.async(fn -> Mojito.get(url, [auth]); :ok end); Task.await(task)
:ok
iex> task = Task.async(fn -> Mojito.get(url, [auth]); :ok end); Task.await(task)
:ok
iex> task = Task.async(fn -> Mojito.get(url, [auth]); :ok end); Task.await(task)
:ok
iex> task = Task.async(fn -> Mojito.get(url, [auth]); :ok end); Task.await(task)
:ok
iex> task = Task.async(fn -> Mojito.get(url, [auth]); :ok end); Task.await(task)
:ok
iex> task = Task.async(fn -> Mojito.get(url, [auth]); :ok end); Task.await(task)
:ok
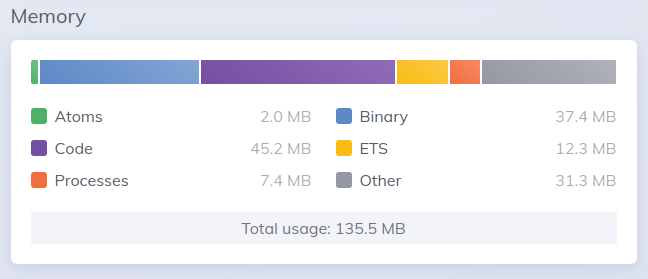
I can see the BEAM memory growing in both AppSignal and LiveDashboard:
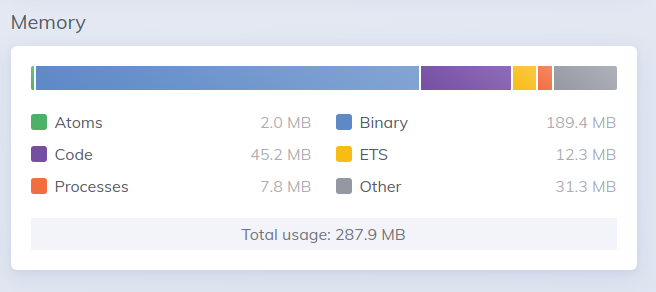
and then after several more requests:
The system has a low number of fullsweep_after_flag set, and I tried setting it to 0 with no difference:
iex> :erlang.system_flag(:fullsweep_after, 0)
0
So the memory keeps growing in the “Binaries” section, and I am pretty sure it’s the HTTP response (that I ignore) accumulating and eating up the memory.
Interestingly, manuallly triggering GC run does not help either. :erlang.garbage_collect() has no effect.
The only thing that does help to release the memory is running :recon.bin_leak/1
So I do have a binaries leak, and I suspect it’s nothing specific to my code but rather a configuration / setting / flag issue.
The binaries stay at around 250-300 MB and never get cleaned up unless I manually kick in :recon.bin_leak/1.
Since this app is running on a low memory instance (0.6GB), this is a real issue as it experiences occasional crashes because it runs out of memory.
I am using Elixir releases, with Elixir 1.1.2 and Erlang 23.1. As part of this adventure I already upgraded from Elixir 1.1.1 and Erlang 22.2, where the issue was the same.
Any ideas? I am running out of hair to pull.

 ), but the usage of Tasks is sticking out to me as something I think we should try to avoid, since this could cause the same kind of inter-process copying that we do not want. Are you sure that they are necessary?
), but the usage of Tasks is sticking out to me as something I think we should try to avoid, since this could cause the same kind of inter-process copying that we do not want. Are you sure that they are necessary?