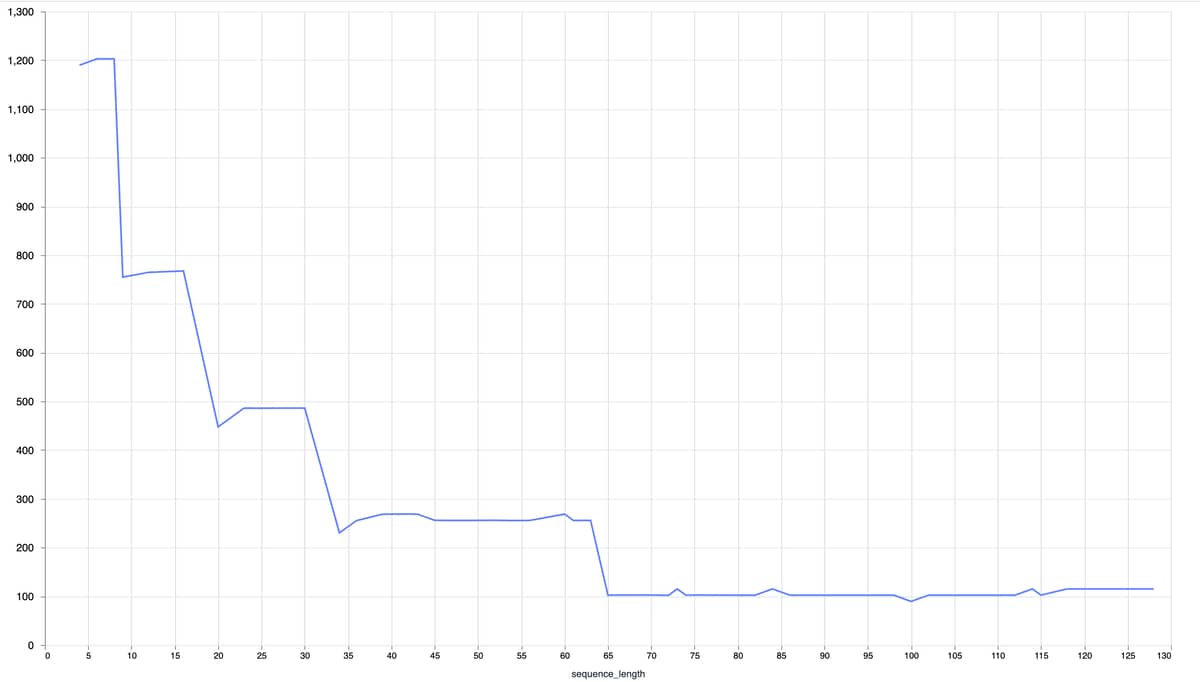
Thank you very much, this is awesome. Indeed a quick benchmark shows a staircase like pattern with the configured batch sizes: