I found this thread very helpful, but I would like to ask some additional questions / clarifications!
I am trying to speed up some text_embedding creations.
I have a data migration where we want to back-fill embeddings for existing entries. I tried various batch sizes for this and settled on 500.
I tried to create the changesets with the embedding with Enum.map and Task.async_stream. But they yield the same time. I realized that all the time is spend on generating the embedding.
I also tried to create multiple servings, both manually and with nimble_pool, but the results were the same. This leads me to believe that even though I had multiple servings the embedding creation is still sequential.
Then I found this thread and went back to a single serving and tried to tweak it.
All these finish the embedding changeset creation step in 55-57 seconds.
My vector size is 384.
I am caching the serving, is that a bad idea?
I tried the following setups:
1, In my config I have: config :nx, default_backend: EXLA.Backend
and create the serving by just calling Bumblebee.Text.TextEmbedding.text_embedding(model_info, tokenizer) as is. - I used this in all the scenarios above.
This leads me to believe that even though I had multiple servings the embedding creation is still sequential.
Only one computation can be running at a time on the given device, so spawning multiple servings is not going to help (unless you have a cluster of multiple nodes, each with its own serving).
Just to be sure, you are using Nx.Serving.batched_run/2 and not Nx.Serving.run/2 right?
This is slower, it takes 76 seconds.
Just the computation or everything including application boot? Note that with compiler: EXLA the serving is going to compile everything into an efficient computation, which may take a bit, but then the computations themselves are faster.
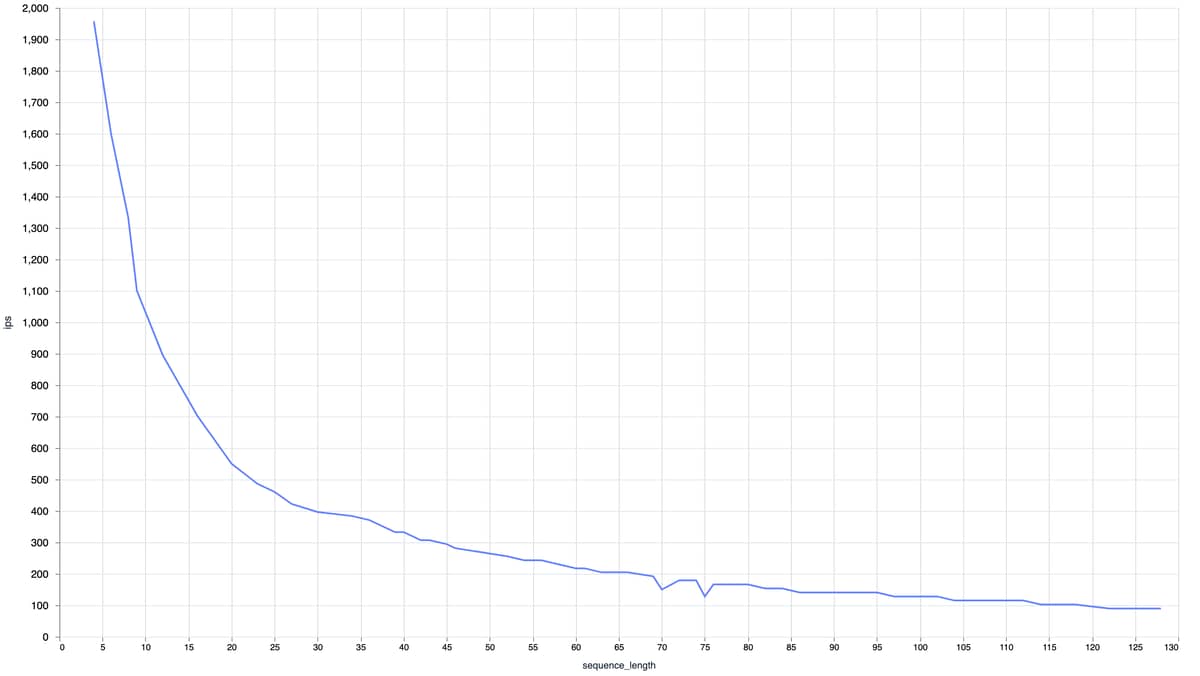
How do I determine the batch size and the sequence_length?
sequence_length is used to pad/trim the input, usually you want to set it to the longest sequence the model supports, unless you know your inputs are always short and it can be reduced. batch_size depends on several factors, when running on a CPU increasing the batch_size at some point makes the computation take linearly as long since there is no more room for for parallelisation, when running on a GPU it depends on how much computation you can fit into the GPU memory; and in both cases depends on the expected number of requests (if it’s small then it doesn’t make sense to use large batch_size).
I am using Nx.Serving.run/2 now. I will try out Nx.Serving.batched_run/2.
These are the docs: Nx.Serving — Nx v0.5.3
I imagine I can just use Bumblebee.Text.TextEmbedding.text_embedding/3 in the place of Nx.Serving.new(Nx.Defn.jit(&print_and_multiply/1))?
So sequence_length is the length of my entry? What is the default?
What is the upside of having a high batch_size on a CPU? What range would you recommend trying?
If you are just running it once for back-filling then Nx.Serving.run/2 may be fine, but it runs right away so you want chunk the list and pass a list of inputs to Nx.Serving.run/2 instead of Task.async_stream (in which case all runs are sequential anyway). Starting a serving under you app supervision tree and batched_run is mainly for long-running and handling concurrent requests.
So sequence_length is the length of my entry?
The input text is tokenized into a sequence of numbers (roughly one per word, sometimes many per word), the model needs a fixed-length sequence, so if the text is short we usually pad the sequence with zeros, if it’s too long it is truncated. The reason for fixed-length is basically so that we can compile the model upfront once with known input shape and run inference quickly. If you don’t set :compile then :sequence_length will effectively be the length of the input each time, but this means that the model is compiled multiple times (per each different input length).
What is the upside of having a high batch_size on a CPU?
Even though it doesn’t have as much parallel qualities as GPU, the XLA compiler can still do some parallelisation, so it could be the case that computation with batch_size: 4 is just a bit slower than batch_size: 1 (and not 4x slower), but it depends on model. It doesn’t hurt to have a big larger :batch_size. It depends on the model, but I would try like 8, 16.
I’m using bumblebee to compute the embedding of user messages (I’m using HF sentence-transformers/paraphrase-multilingual-mpnet-base-v2), with the goal of semantically cache the response of a LLM and save CPU time (and money). Bumblebee needs on average 50% more time than the equivalent Python code, wrapped by a FastAPI server.
I went through this thread, but it’s not clear to me what I should to to improve Bumblebee’s performance. I’m compiling the model (Axon.compile(model_info.model, template, %{}, compiler: EXLA)), which increases the performance relative to the JIT compilation, but it’s still slow compared to Python.
It is hard to say without more information on how you are running the model. Per above, the results will vary depending if you are batching or not and if you are padding or not. Can you provide a snippet with more information on how you are starting the serving and calling it?
Hi @aus, that looks good to me. Just make sure that input_mask_expanded and result.hidden_state are allocated on the EXLA Backend and not the binary backend. You can print them to the terminal to confirm.
At the end, this may still be slower than the Python version for two reasons:
EXLA for CPU is not as fast as it should be
We don’t support dynamic shapes, which means you need to precompute/pad to 128. You could try passing larger inputs to both and ensure they both perform same at 128 entries or not
I believe you can call the tokenizer without a length and the size of the tensor it returns.
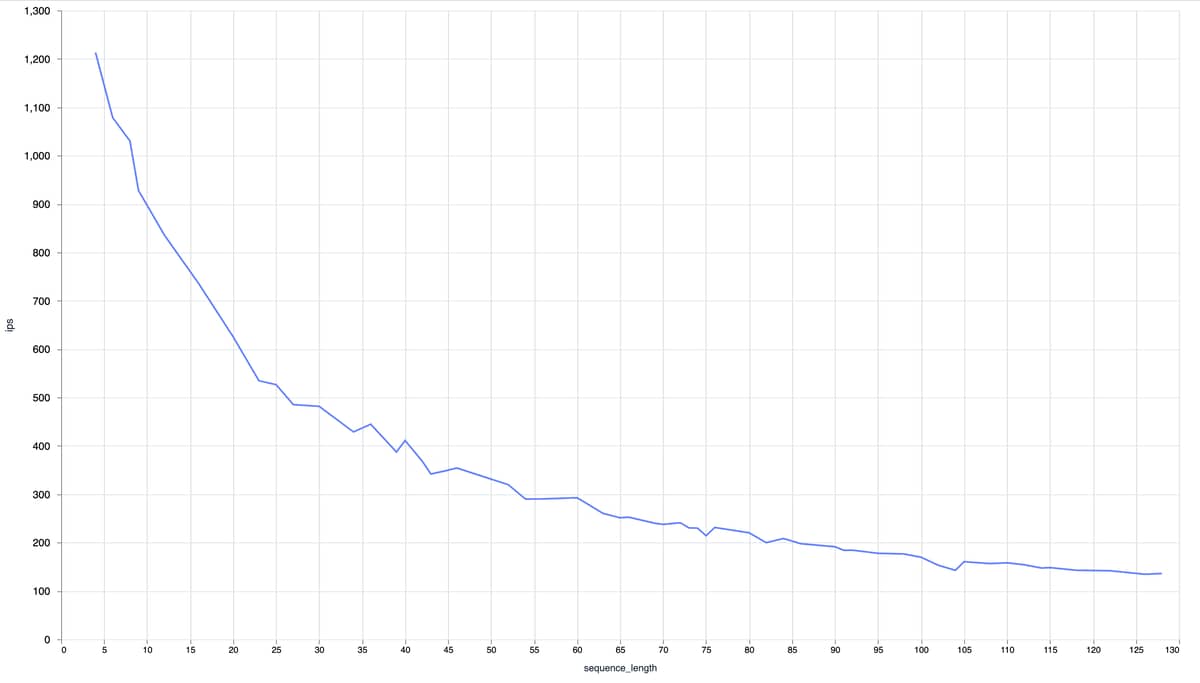
I experimented with running a model through ortex today, but I don’t see how this improves the situation with different sequence lengths. As soon as I send inputs with different sizes to my serving, I get an error that I cannot merge batches due to incompatible templates, which makes sense. Sending the full tokenizer output to the Ortex model does not offer a performance gain compared to running EXLA with the full sequence length.
Could you benchmark Ortex without the serving? Basically calling it as the input arrives (which is what PyTorch would do)? Because otherwise, you are right, serving will still be the limitation (unless you want to give the main branch a try and provide multiple functions for different sequence lengths sizes).
This also achieves full CPU utilization on my MacBook in comparison to EXLA
So it seems like Ortex does not benefit that much from using Nx.Serving, as the model does not need to be precompiled to certain input shapes, in contrast to when using EXLA, is that right?
I am not sure if we should generalize that to Ortex but we can conclude that’s true for Ortex+sberts running on CPU. I assume GPUs will be happier with batching than CPUs, even if not compiled.
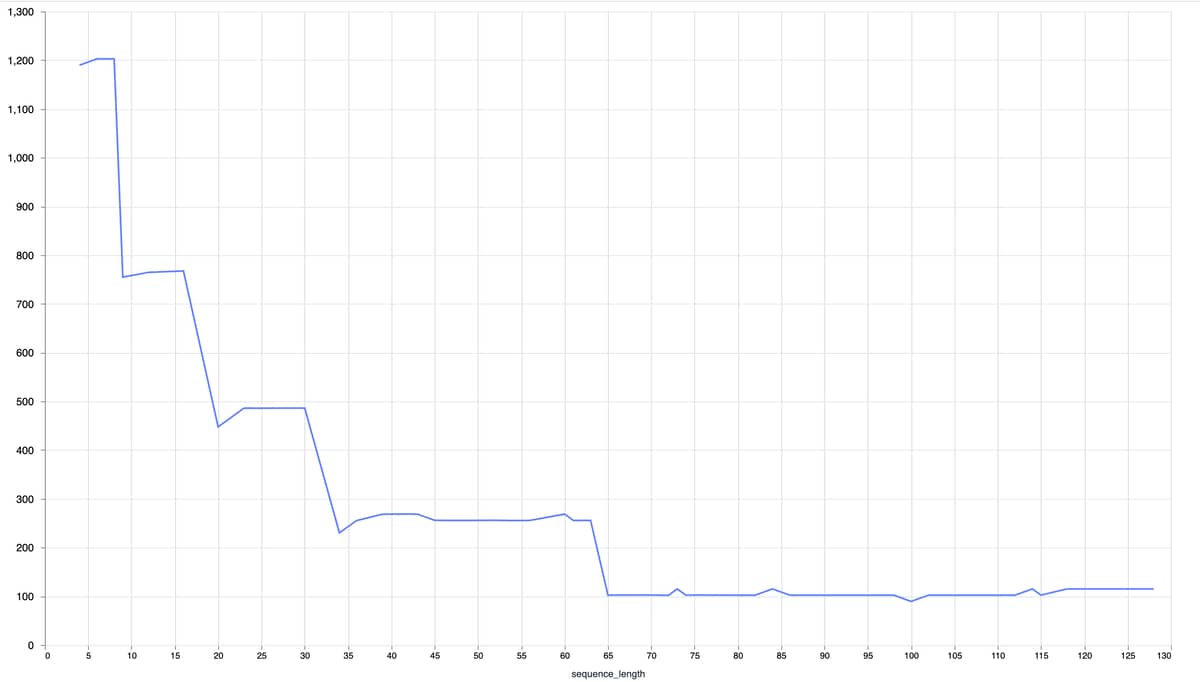
@steffend on Bumblebee main you can specify multiple sequence lengths, in which case we compile multiple versions of the computation and inputs are batched depending on the length. This way short sequences don’t have overly long padding. Here’s an example:
# Text embedding with multiple lengths
```elixir
Mix.install([
{:bumblebee, github: "elixir-nx/bumblebee"},
{:rustler, ">= 0.0.0", optional: true},
{:nx, github: "elixir-nx/nx", sparse: "nx", override: true},
{:exla, github: "elixir-nx/nx", sparse: "exla", override: true},
{:kino, "~> 0.10.0"}
])
Nx.global_default_backend(EXLA.Backend)
```
## 🐈⬛
```elixir
repo = "sentence-transformers/all-MiniLM-L6-v2"
{:ok, model_info} = Bumblebee.load_model({:hf, repo})
{:ok, tokenizer} = Bumblebee.load_tokenizer({:hf, repo})
serving =
Bumblebee.Text.TextEmbedding.text_embedding(model_info, tokenizer,
compile: [batch_size: 32, sequence_length: [16, 32, 64, 128, 512]],
defn_options: [compiler: EXLA]
)
Kino.start_child({Nx.Serving, serving: serving, name: MyServing})
```
```elixir
short_text = "this is a test"
Nx.Serving.batched_run(MyServing, short_text)
```
```elixir
long_text = String.duplicate("this is a test with a much longer text", 50)
Nx.Serving.batched_run(MyServing, long_text)
```
The first input falls under a shorter sequence length, meaning we use less padding and the computation is faster. The second input falls under the largest length, so we pad to 512 and the computation takes longer.
So to summarize this topic: Elixir + Nx perform quite well for generating sentence embeddings. It is very important to make sure that the model is compiled for the right sequence lengths though, as the input is padded.
For varying input lengths, the newest Bumblebee code on GitHub now supports specifying multiple sequence lengths, as seen in post 36.
Another option is using Ortex and an ONNX model. Here is an example livebook that uses this approach: Running the all-mpnet-base-v2 sentence transformer in Elixir using Ortex · GitHub. In that case, using a serving does not improve the performance that much, at least when running on CPU. Therefore one can also just call Ortex.run directly.
Thanks for all the replies and insights. I’m happy to see that this lead to some improvements in Bumblebee and Nx!
I’m also happy to report that we’re currently working on moving our production setup from Python to Elixir+Nx at my job