
sorentwo
Oban - Reliable and Observable Job Processing
Hello!
tl;dr Announcing Oban, an Ecto based job processing library with a focus on reliability and historical observability.
After spending nearly a year building Kiq, an Elixir port of Sidekiq with most of the bells and whistles, I came to the realization that the model was all wrong. Most of us don’t want to rely on Redis for production data, and Sidekiq is a largely proprietary legacy system. Not the best base for a reliable job processing system.
So, I took the best parts of Kiq and some inspiration from EctoJob and put together Oban. The primary goals are reliability , consistency and observability. It is fundamentally different from other background job processing tools because it retains job data for historic metrics and inspection.
Here are some of the marquee features that differentiate it from other job processors that are out there (pulled straight from the README):
- Isolated Queues — Jobs are stored in a single table but are executed in distinct queues. Each queue runs in isolation, ensuring that a jobs in a single slow queue can’t back up other faster queues.
- Queue Control — Queues can be paused, resumed and scaled independently at runtime.
- Job Killing — Jobs can be killed in the middle of execution regardless of which node they are running on. This stops the job at once and flags it as
discarded. - Triggered execution — Database triggers ensure that jobs are dispatched as soon as they are inserted into the database.
- Scheduled Jobs — Jobs can be scheduled at any time in the future, down to the second.
- Job Safety — When a process crashes or the BEAM is terminated executing jobs aren’t lost—they are quickly recovered by other running nodes or immediately when the node is restarted.
- Historic Metrics — After a job is processed the row is not deleted. Instead, the job is retained in the database to provide metrics. This allows users to inspect historic jobs and to see aggregate data at the job, queue or argument level.
- Node Metrics — Every queue broadcasts metrics during runtime. These are used to monitor queue health across nodes.
- Queue Draining — Queue shutdown is delayed so that slow jobs can finish executing before shutdown.
- Telemetry Integration — Job life-cycle events are emitted via Telemetry integration. This enables simple logging, error reporting and health checkups without plug-ins.
Version v0.2.0 was released today. Please take a look at the README or the docs and let me know what you think!
https://github.com/sorentwo/oban
— Parker
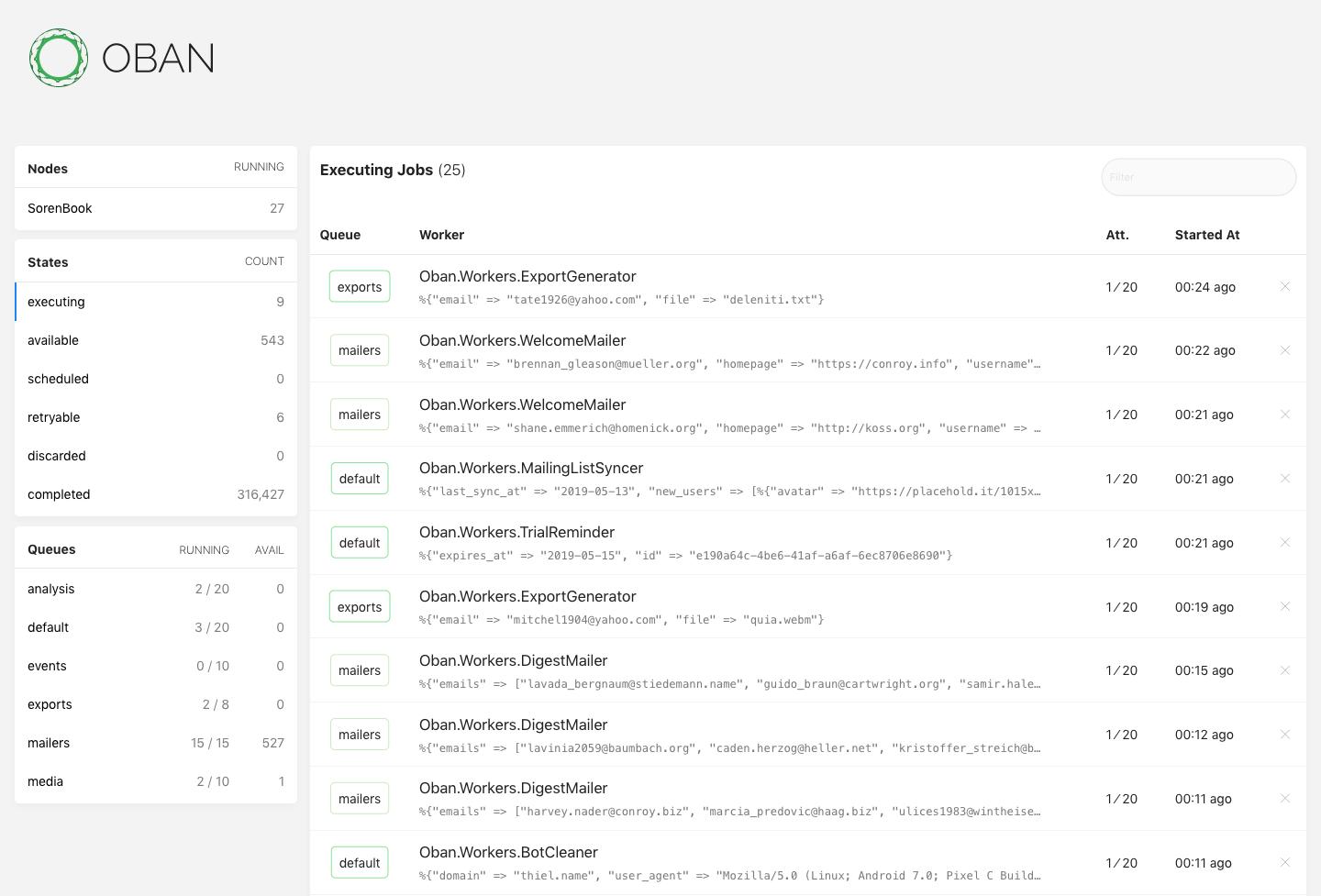
One more thing! A stand-alone dashboard built on Phoenix Live View is in the works.
The killer feature for any job processor is the UI. Every sizable app I know of relies on a web UI to introspect and manage jobs. It is very much a WIP, but here is a preview of the UI running in an environment with constant job generation:
Most Liked
sorentwo
Today I’m very excited to announce the release of Oban v1.0.0-rc.1. This release has been a long time coming and it packs a lot of new features, performance improvements, stability fixes and updated defaults for pruning and heartbeats. If there aren’t any regressions or breaking changes then I’ll release 1.0.0 in one week.
This release does require a migration, but I crammed as many features as I could into it: priority jobs, tags, a discarded_at timestamp and a massively improved notifications trigger.
Thanks to everybody that contributed and reported issues. ![]()
From the CHANGELOG:
Migration Required (V8)
This is the first required migration since 0.8.0, released in 09/2019. It brings with it a new column, discarded_at, a streamlined notifications trigger, job prioritiy and job tags.
Added
-
[Oban] Add
timezonesupport for scheduling cronjobs using timezones other than “Etc/UTC”. Using a custom timezone requires a timezone database such as tzdata. -
[Oban] Add
dispatch_cooldownoption to configure the minimum time between a producer fetching more jobs to execute. -
[Oban] Add
beats_maxageoption to configure how long heartbeat rows are retained in theoban_beatstable. Each queue generates one row per second, so rows may accumulate quickly. The default value is now five minutes, down from one hour previously. -
[Oban.Job] Add
discarded_attimestamp to help identify jobs that were discarded and not completed. The timestamp is added by the V8 migration and it is also included in the originalcreate tablefrom V1 as a minor space saving optimization (packing datetime columns together because they use a predictable 4bytes of space). -
[Oban.Job] Add numerical
priorityvalue to control the order of execution for jobs within a queue. Theprioritycan be set between 0 and 3, with 0 being the default and the highest priority. -
[Oban.Job] Add
tagsfield for arbitrarily organizing associated tags. Tags are a list of strings stored as anarrayin the database, making them easy to search and filter by.
Changed
-
[Oban] Change the default
prunevalue from:disabledto{:maxlen, 1_000}. Many people don’t change the default until they realize that a lot of jobs are lingering in the database. It is rare that anybody would want to keep all of their jobs forever, so a conservative default is better than:disabled. -
[Oban] Change
oban_beatsretention from one hour to five minutes. The value is now configurable, with a default of300s. The lower bound is60sbecause we require one minute of heartbeat activity to rescue orphaned jobs. -
[Oban.Queue.Producer] Introduce “dispatch cooldown” as a way to debounce repeatedly fetching new jobs. Repeated fetching floods the producer’s message queue and forces the producer to repeatedly fetch one job at a time, which is not especially efficient. Debounced fetching is much more efficient for the producer and the database, increasing maximum jobs/sec throughput so that it scales linearly with a queue’s concurrency settings (up to what the database can handle).
-
[Oban.Query] Discard jobs that have exhausted the maximum attempts rather than rescuing them. This prevents repeatedly attempting a job that has consistently crashed the BEAM.
-
[Oban.Query] Use transactional locks to prevent duplicate inserts without relying on unique constraints in the database. This provides strong unique guarantees without requiring migrations.
Removed
- [Oban.Notifications] An overhauled and simplified insert trigger no longer emits
updatenotifications. This was largely an internal implementation detail and wasn’t publicly documented, but it does effect the UI.
sorentwo
This is purely a comparison of how the libraries are structured and their features. Between building Kiq and Oban I investigated nearly every library in the ecosystem (EctoJob, Exq, Honeydew, Que, Rihanna and Verk). I learned something from each one and owe all of the authors a debt of gratitude.
There are far too many differences between the various libraries to summarize them here. Therefore I’m going to cheat a bit and make a table highlighting the differences between only the libraries you asked about.
| Feature | Oban | EctoJob | Rihanna |
|---|---|---|---|
| perform return | output doesn’t matter | multi transaction | success tuple |
| job scheduling | triggered, polled | triggered, polled | polled |
| args storage | jsonb | jsonb | erlang terms |
| error retention | all full historic errors | none | last error |
| execution time | unlimited | configured timeout | unlimited |
| orphaned jobs | rescued, guarded by locks | inside a transaction | guarded by locks |
| queues | multiple with single table | one per table | single |
| queue limits | configured limit per queue | configured limit per queue | configured globally |
| queue changes | pause, resume, scale | none | none |
| graceful shutdown | worker draining | no | no |
| job cancelling | yes | no | no |
| runtime metrics | with telemetry | no | no |
| historic metrics | with retained jobs | no | no |
| integrations | with telemetry, pubsub | no | no |
This is all based on my understanding of the other libraries through docs, issues and source code. It may not be entirely accurate! If I got anything wrong please let me know (@mbuhot @lpil)
sorentwo
That was my initial inclination as well, but I ended up using JSONB instead of a few reasons:
- It makes it much easier to enqueue jobs in other languages. The primary system I work on uses Elixir, Python and Ruby on the backend. It is essential that jobs can be enqueued from outside of Elixir/Erlang.
- Searching and filtering is an important part of the UI and historic observation. By storing arguments as JSONB we can actually leverage indexes for full text search. A common situation we have is trying to determine if a job was ran for a particular customer or with particular arguments.
Thanks for the feedback!
Popular in Announcing










Other popular topics








 Latest Oban Threads
Latest Oban Threads
Latest on Elixir Forum
Sponsor Spotlight

Supporting innovation across the BEAM ecosystem.
Categories:
Sub Categories:
Forums
Popular Tags
- #ecto
- #liveview
- #troubleshooting
- #learning-elixir
- #deployment
- #library
- #erlang
- #testing
- #genserver
- #mix
- #absinthe
- #remote-other
- #otp
- #plug
- #how-to-question
- #macros
- #postgres
- #channels
- #elixirconf
- #exunit
- #discussion
- #code-sync
- #javascript
- #podcasts
- #onsite
- #dialyzer
- #docker
- #authentication
- #umbrella
- #full-time-contract
- #podcasts-by-brainlid
- #ecto-query
- #elixir-ls
- #phoenix_html
- #iex
- #blog-post
- #graphql
- #genstage
- #ai
- #websockets
- #supervisor
- #elixirconf-us
- #advent-of-code
- #distillery
- #processes
- #forms
- #api
- #metaprogramming
- #security
- #hex
Our Sponsors

Build Elixir applications with speed and confidence.
Supporting innovation across the BEAM ecosystem.

We build reliable cloud platforms for business-critical systems.

Catch errors, track performance, monitor hosts and more.

Error tracking for Elixir devs who love to ship. Start your free account.

Develop your skills with books, videos, and courses.

Enabling companies to succeed by building software people love.

The deployment platform built for Elixir: PaaS ease, VPS control.

The team behind Membrane, Popcorn, LiveDebugger. Available for hire.

Courses that'll move you from confusion to "Aha, now I get it!"