It is kind of by design. I have a separate package called “oban_cron” that I haven’t published yet, but it does exactly what you’re asking about. I’ve debated making it part of oban itself, but it works nicely as a separate package.
Quantum is really powerful, but it doesn’t make sense in every situation IMO. There are a couple of downsides that I hoped to address with a focused package:
Work without connected nodes. Quantum uses node communication for leadership, to prevent double-enqueuing a job.
Have a smaller footprint. Quantum is a lot of code when all you want to specify is {"0 14 * * MON", MyApp.SomeWorker} in some configuration.
I remember in the Rails days using Sidekiq but then also lugging around Clockwork just for scheduling. When glancing your readme one of the first things I looked for was repeated scheduled tasks.
I wonder what others think about putting oban_cron into the main repo.
Informally I’ll consider “hearts” on this post to be in favor of including it directly in Oban. If anybody has arguments against inclusion please post!
I think that it would be a great addition to Oban.
The current version of Quantum is unstable when clustering in certain cases. We’ve experienced some of them in the company I work for which caused some undesirable effects such as tasks not running or running once per each node in the cluster.
This is acknowledged in Quantum and they are working in a solution.
Oban has been rock solid and reliable since we started using it in the project. So it could be a wonderful alternative.
Nice work. Looking forward to replacing Quantum with this. After just glancing at your commit, that makes me really happy to see. I had nothing against Quantum but being able to drop a whole library with a ton of code for a few dozen lines of code is a huge win.
One question. In your new docs you put “Jobs are considered unique for most of each minute”. What type of race conditions or edge cases should we be aware of to hit the points where it might not be unique?
Jobs are marked as unique for 59 seconds, not 60 seconds. There has to be some wiggle room between the unique period and the next enqueue cycle. That leaves a one second window where a theoretical double-enqueue is possible. That situation would only happen if you can restart your node fast enough that it enqueued at the start of one second, booted up and enqueued at the end of the same second.
If I’m understanding correctly, this supports running a job on a single node in a cluster periodically.
It might be beyond the scope of Oban, but is there a way to run a job on every node in a cluster periodically? I’ve used Quantum that way for things like refreshing credentials periodically.
Oban v0.11.0 is published with a variety of bug fixes and the addition of CRON jobs. There is an optional migration that will prevent issues recording beats when job ids get into the 64bit range.
Anybody using the UI beta should upgrade, the oban_update notification change is essential to keeping stats updated.
Job id’s greater than 2,147,483,647 (PG int limit) can’t be inserted into the running array on oban_beats. The array that Ecto defines uses int instead of bigint, which can’t store the larger integers. This migration changes the column type to bigint[], a locking operation that may take a few seconds.
Added
[Oban] Added crontab support for automatically enqueuing jobs on a fixed schedule. A combination of transactional locks and unique jobs prevents scheduling duplicate jobs.
Fixed
[Oban.Migrations] Add a comment when migrating oban_jobs to V5 and when rolling back down to V4.
[Oban.Query] Apply the configured log level to unique queries.
[Oban.Notifier] Prevent open connections from accumulating when the circuit is tripped during the connection phase. This change may leave notifications in a state where they aren’t listening to all channels.
Changed
[Oban.Notifier] Replay oban_update notifications to subscribed processes.
Oban v0.12.0 is out with some fun features, testing improvements, bug fixes and a helpful (optional) migration for large pruning operations. Thanks to all of the contributors who made this one possible!
The queries used to prune by limit and age are written to utilize a single partial index for a huge performance boost on large tables. The new V7 migration will create the index for you—but that may not be ideal for tables with millions of completed or discarded jobs because it can’t be done concurrently.
If you have an extremely large jobs table you can add the index concurrently in a dedicated migration:
create index(
:oban_jobs,
["attempted_at desc", :id],
where: "state in ('completed', 'discarded')",
name: :oban_jobs_attempted_at_id_index,
concurrently: true
)
Added
[Oban] Add start_queue/3 and stop_queue/2 for dynamically starting and stopping supervised queues across nodes.
[Oban] Expose circuit_backoff as a “twiddly” option that controls how long tripped circuit breakers wait until re-opening.
[Oban.Testing] Accept a value/delta tuple for testing timestamp fields. This allows more robust testing of timestamps such as scheduled_at.
[Oban.Telemetry] Emit [:oban, :trip_circuit] and [:oban, :open_circuit] events for circuit breaker activity. Previously an error was logged when the circuit was tripped, but there wasn’t any way to monitor circuit breakers.
Circuit breaker activity is logged by the default telemetry logger (both :trip_circuit and :open_circuit events).
Fixed
[Oban.Query] Avoid using prepared statements for all unique queries. This forces Postgres to use a custom plan (which utilizes the compound index) rather than falling back to a generic plan.
[Oban.Job] Include all permitted fields when converting a Job to a map, preserving any optional values that were either specified by the user or came via Worker defaults.
[Oban.Migrations] Guard against missing migration modules in federated environments.
Changed
[Oban] Allow the multi name provided to Oban.insert/3,4 to be any term, not just an atom.
[Oban.Query] Use a consistent and more performant set of queries for pruning. Both pruning methods are optimized to utilize a single partial index.
Redis is excellent in many capacities but persistent storage isn’t one of them. When background jobs are doing work that is important to your business then you should treat them like the rest of your data.
You’d have to do a massive amount of background work to overload a production PG database. Redis is fast, but it is single threaded and when you do complex work on the server (e.g. with lua scripts) then it can get overloaded as well—a medium-traffic system I work on has 70k+ timeout errors from Redis over the past several months. Application level pooling doesn’t help much either because the server on the other end is still only single threaded.
This one might be application specific. I am cautious about extracting meaning about Redis based on this. I do agree, though, that having persistence through Postgres for jobs is really useful and is one of the best parts of using PG for a job server. My application does about 10k+ inserts/job processes per second to Redis (through Sidekiq LUA scripts) at peak and I haven’t seen these timeouts before.
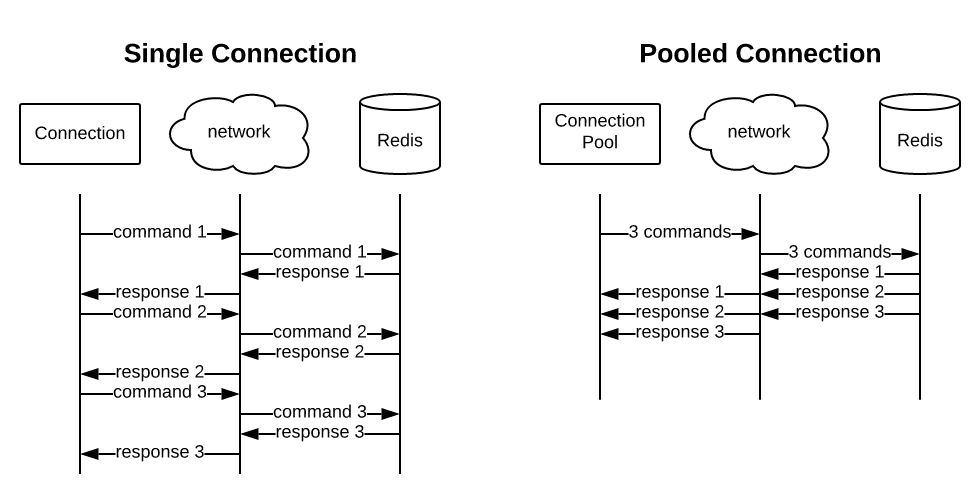
Application pooling is pretty significant with Redis, and I would say is almost required for production usage, because it parallelizes the network traffic with Redis. The work is still single-threaded, but the network time is significantly reduced. Here is an image that demonstrates the same amount of work in a singular vs pooled Redis environment. The pooling would have a significant impact here.
None of this has much to do with Oban, though. Postgres works great for 99% of applications, and could be tuned with something like Citus for extremely high throughput environments. Many people will choose not having another tool in their stack, so they’ll choose Oban.
Totally fair. That is definitely application specific and Redis is being used as the glue between a lot of things in that system (in addition to Sidekiq LUA and Kiq LUA scripts). I only meant to illustrate that Redis can have timeouts too when it gets enough load.