
aaronrussell
Omni - a universal Elixir client for LLM APIs
This thread is the home for updates and discussion across the Omni family of packages. What started as a single library for calling LLM APIs has grown into three packages that cover the full stack of building with LLMs in Elixir:
- omni - Universal Elixir client for LLM APIs. Streaming text generation, tool use, an structured output.
- omni_agent - Stateful LLM agents for Elixir - persistent, branching conversations, tool approval, and multi-session management.
- omni_tools - Ready-to-use tools for Omni-powered agents - filesystem, shell, REPL, web fetch, and web search.
Original post follows.
Hey everyone - I’ve been building with Elixir on and off for over 8 years, but somehow have never posted on the actual Elixir forum. Time to fix that…
Also, I’d love to share with you Omni - a library for working with LLM APIs across multiple providers through a unified interface. Anthropic, OpenAI, Google Gemini, Ollama, OpenRouter, and OpenCode Zen are supported out of the box.
# Resolve model
{:ok, model} = Omni.get_model(:anthropic, "claude-sonnet-4-6")
# Simple text generation
{:ok, response} = Omni.generate_text(model, "Hello!")
# Stream with composable callbacks
{:ok, stream} = Omni.stream_text(model, "Tell me a story")
{:ok, response} =
stream
|> Omni.StreamingResponse.on(:text_delta, &IO.write(&1.delta))
|> Omni.StreamingResponse.complete()
Tool use and structured outputs are supported. Pass tools in the context and Omni handles the execution loop automatically - calling the model, executing tool handlers, feeding results back, and repeating until the model is done. Structured output uses JSON Schema constraints with validation:
# Tool use - Omni manages the tool execution loop
{:ok, response} = Omni.generate_text(
model,
Omni.context(
messages: [Omni.message(role: :user, content: "What's the weather in London?")],
tools: [weather_tool]
)
)
# Structured output
alias Omni.Schema
{:ok, response} = Omni.generate_text(
model,
"Extract the contact details: Reach me at jane@example.com or call 01234 567890",
output: Schema.object(%{
email: Schema.string(description: "Email address"),
phone: Schema.string(description: "Phone number")
}, required: [:email, :phone])
)
Omni also offers a lightweight take on agents. Omni.Agent is a GenServer that manages its own conversation context and tool execution, and communicates with callers via standard process messages. You control behaviour through lifecycle callbacks. It’s a building block, not a framework - what you build on top (planning, memory, multi-agent orchestration) is your concern.
I know req_llm covers similar ground, which - slightly annoyingly - I didn’t realise existed until I was 90% of the way done with Omni ![]() . On the surface they have quite similar APIs, and both use Req, but how they handle implementing providers is a little different. Omni separates providers (the endpoint, configuration and auth) and dialects (wire format translation). The dialect does the heavy lifting, and as most providers share a dialect, adding a new provider is typically a small, mostly-declarative module. Everything is streaming-first -
. On the surface they have quite similar APIs, and both use Req, but how they handle implementing providers is a little different. Omni separates providers (the endpoint, configuration and auth) and dialects (wire format translation). The dialect does the heavy lifting, and as most providers share a dialect, adding a new provider is typically a small, mostly-declarative module. Everything is streaming-first - generate_text is built on top of stream_text, so there’s one code path through each dialect.
Anyway, please check it out. Let me know if you have any questions.
Most Liked
aaronrussell
A new package in the family: Omni UI - a LiveView interface for interacting with Omni-powered agents in the browser.
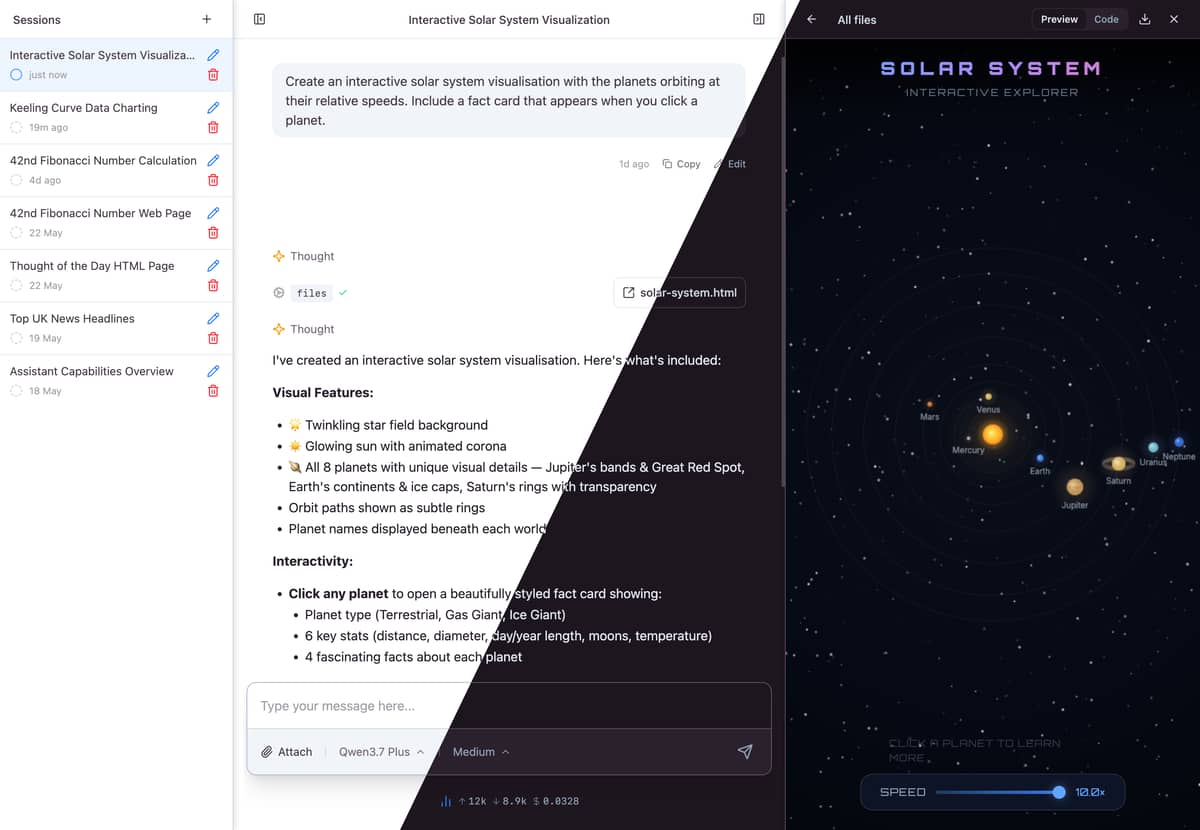
Omni UI is an example of how omni, omni_agent, and omni_tools can be used together to build agents in Elixir, and also a UI kit for building chat interfaces in your own app.
Either mount Omni.UI.AgentLive in your router for a batteries included chat interface with sessions, files, a REPL and web tools all wired up. Or use Omni.UI in your own LiveView and compose from the component library - you own the layout and agent tooling, the macro handles all the wiring.
Highlights
- Built on Omni — multi-provider LLM support, streaming, tool use, structured output, persistent sessions, branching conversations, and pluggable storage
- Drop-in agent chat — AgentLive mounts a complete interface with a files panel, Elixir REPL, and web tools wired up out of the box
- Build your own —
use Omni.UIadds session plumbing to any LiveView; compose with ChatUI and CoreUI components for the rendering layer - Themeable — semantic colour tokens with light and dark mode support
Links
- GitHub - The README has a quick start that gets you from zero to a running agent chat in about 10 lines of config.
- Hexdocs
And as it’s been a while since my last update, there’s been a few updates to other Omni packages:
Omni v1.5.4 hex | code
- New provider module: Near AI
- Updated model catalogue (Opus 4.8, Fable, Minimax M3, GLM 5.2 have all landed in the last month+)
Omni Agent v0.5.0 hex | code
- Session Manager now starts it’s own
TitleServicewhich will add session titles based on hueristic or a configured model - New
Manager.rename/3function for manually setting a session’s title - The
:tool_timeoutoption onOmni.Agentnow accepts a 1-arity function receiving the tool name, for per-tool timeouts
Omni Tools v0.4.1 hex | code
- New bang variants of the
Files.FSfunctions that raise descriptive errros WebSearchtool aligns API key resolution withOmni.Provider.resolve_auth/1- Fixed some “clause never used” warnings surfaced by Elixir 1.20’s type checker

egeersoz
aaronrussell
They’re both text generation focused - so fundamentally do the same thing. Just a different style and take.
Langchain has a few things Omni does not: multimodal, RAG text splitting, EEx prompt templates - and probably some other stuff. Omni is light-weight, only has 2 dependencies.
The main difference for users is the surface API. The mental model for Omni: is build a request, get a stream, consume it. For Langchain it’s build a chain, add some messages, run the chain. Omni’s style is functional, data oriented; Langchain’s is stateful structs, callbacks, framework-y.
Internally the big difference is how Omni splits Providers and Dialects into two things, which should make it relatively painless to add more providers over time. Langchain has one big fat module per provider which I think looks hard to maintain. In theory Omni could sit underneath Langchain and be that provider translation layer.
Last Post!
aaronrussell
Omni just received a pretty big update that reworks how it loads it’s model catalogue, and brings couple of breaking changes to watch out for too.
Omni v1.6.0 hex | code
Model data now comes through pluggable model sources, so you can choose where catalog data comes from - or plug in your own.
 What’s new?
What’s new?
Omni.Sourcebehaviour module - pluggable model sources, configurable globally or per provider.Omni.Sources.ModelsDev(the default) - a bundled models.dev snapshot, with an optional live mode that fetches fresh catalog data when starting your app:config :omni, :models, source: {Omni.Sources.ModelsDev, live: true}Omni.Sources.LLMDB- an alternative source backed by @mikehostetler’sllm_dbpackage (the model database used by ReqLLM):# with {:llm_db, "~> 2026.7"} in your deps config :omni, :models, source: Omni.Sources.LLMDB- The Ollama provider has now been split into two:
Omni.Providers.Ollamafor using local models, andOmni.Providers.OllamaCloudfor Ollama’s hosted cloud service.
A nice side effect: catalog-backed custom providers got much simpler - a provider now only needs an :id and a config/0, and its model list loads from the configured source automatically.
 Breaking changes
Breaking changes
A few config pattern changes that might affect users. If affected, you should get noisy boot-time errors with migration instructions:
- Custom providers must now declare a canonical id:
use Omni.Provider, id: :mistral - Moonshot AI’s provider ID has changed from
:moonshotto:moonshotai, and Ollama is now split into:ollama(local) and:ollama_cloud. These changes align Omni better with models.dev and llm_db’s naming conventions. - Provider registration moved from
config :omni, :providersto theproviders:key ofconfig :omni, :models. Full module names are required rather than provider ID atoms:config :omni, :models, providers: [:builtins, MyApp.Providers.Acme]
Full details in the changelog.
Popular in Announcing







Other popular topics





Latest on Elixir Forum
Sponsor Spotlight

Practical resources that improve the lives of professional developers.
Categories:
Sub Categories:
Forums
Popular Tags
- #ecto
- #liveview
- #troubleshooting
- #learning-elixir
- #deployment
- #library
- #erlang
- #testing
- #genserver
- #mix
- #absinthe
- #remote-other
- #otp
- #plug
- #how-to-question
- #macros
- #postgres
- #channels
- #elixirconf
- #exunit
- #discussion
- #code-sync
- #javascript
- #podcasts
- #onsite
- #dialyzer
- #docker
- #authentication
- #umbrella
- #full-time-contract
- #podcasts-by-brainlid
- #ecto-query
- #elixir-ls
- #phoenix_html
- #iex
- #blog-post
- #graphql
- #genstage
- #ai
- #websockets
- #supervisor
- #elixirconf-us
- #advent-of-code
- #distillery
- #processes
- #forms
- #api
- #metaprogramming
- #security
- #hex
Our Sponsors

Build Elixir applications with speed and confidence.

Supporting innovation across the BEAM ecosystem.

We build reliable cloud platforms for business-critical systems.

Catch errors, track performance, monitor hosts and more.

Error tracking for Elixir devs who love to ship. Start your free account.
Practical resources that improve the lives of professional developers.

Producing high quality Elixir screencasts since 2017.

Enabling companies to succeed by building software people love.

The team behind Membrane, Popcorn, LiveDebugger. Available for hire.

Courses that'll move you from confusion to "Aha, now I get it!"