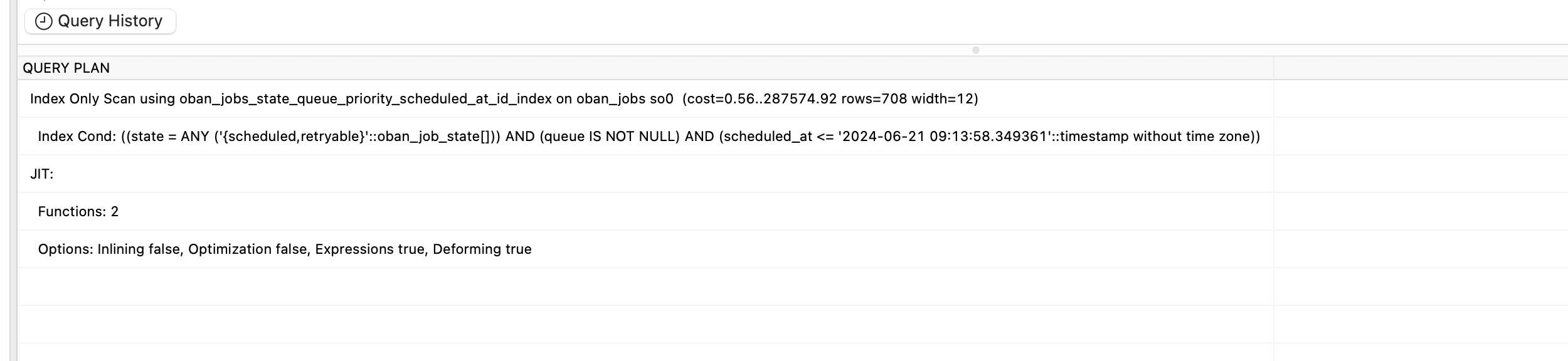
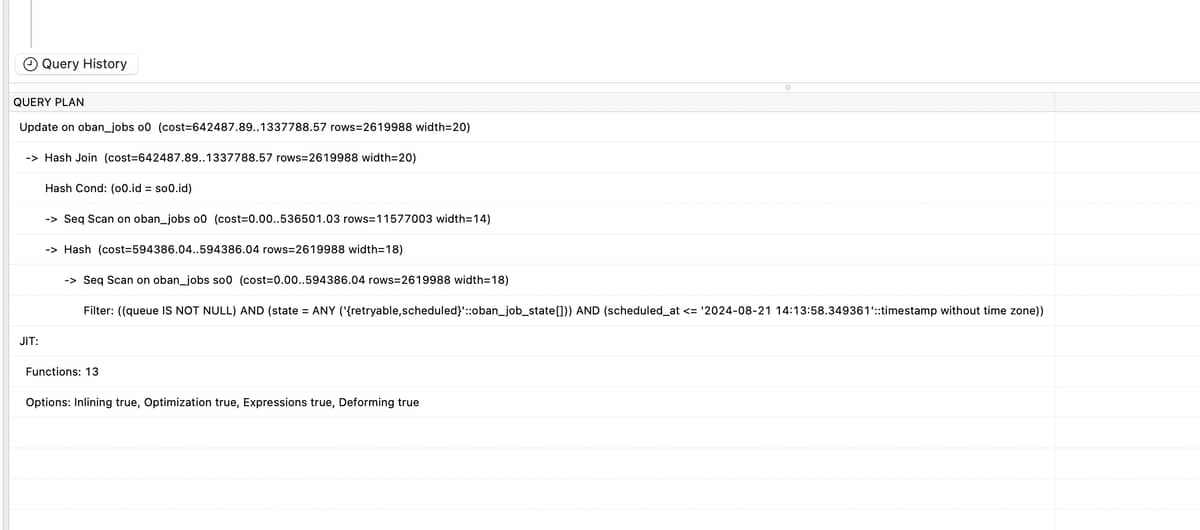
We’ve been doing some analyzing of the oban queries hitting our postgres database. We’ve found that every aproximately every 5s an UPDATE is done to set ‘scheduled’/‘retryable’ jobs to ‘available’. However, the query:
UPDATE
"public"."oban_jobs" AS o0
SET
"state" = $1
FROM (
SELECT
so0."id" AS "id",
so0."state" AS "state"
FROM
"public"."oban_jobs" AS so0
WHERE
(so0."state" IN ($4,
$5))
AND (NOT (so0."queue" IS NULL))
AND (so0."scheduled_at" <= $2)
LIMIT
$3) AS s1
WHERE
(o0."id" = s1."id") RETURNING o0."id",
o0."queue",
s1."state"
takes, on avarage, 4 seconds to execute. Somehow, no index seems to be used in the subquery (which seems to be the culprint here). However, just executing the subquery successfully uses oban_jobs_state_queue_priority_scheduled_at_id_index.
We’re not that time dependant that a few seconds really matters for us, but we were curious to see if this is a know issue, or something that we’re doing wrong.
The reindexer reduced the size of our index to around 1 GB. But the performance issues remain. We currently have a rentention of one week. Is it recommended to have a low retention period? Or would that not impact the performance in any meaningful way?
About 4 hours after reindexing, the query planner seem to have changed. The query is now using the right index and the queries are visibly faster. Thank you!
Edit: I think I’ll start a new thread for this specific problem.
Sorry that it took a bit to respond! We were at ElxirConf in Orlando.
A lower retention period can really help performance. It comes down to how many jobs you’re running, more than the total time.
You are most welcome. Great to hear that it worked, that’s marvelous!
New indexes won’t impact the planner until the next vacuum analyze. Ecto also caches prepared statements, and those won’t change until the connections that own them are closed (or the app restarts).