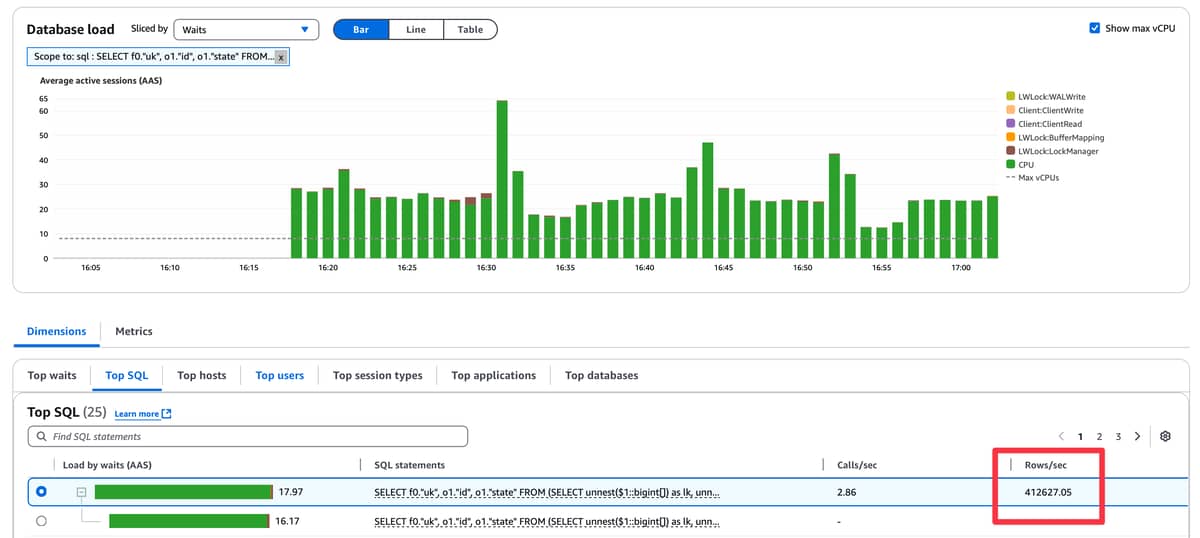
We’re seeing some pretty bad performance issues with the Oban Pro 1.5 upgrade.
This query in particular appears to be the problem:
SELECT f0."uk", o1."id", o1."state" FROM (SELECT unnest($1::bigint[]) as lk, unnest($2::text[]) AS uk, unnest($3::text[]) AS us) AS f0 INNER JOIN "public"."oban_jobs" AS o1 ON TRUE WHERE ((NOT (pg_try_advisory_xact_lock($4::int, f0."lk"::int)))) OR (o1."meta" @> jsonb_build_object('uniq_key', f0."uk") AND o1."state"::text = ANY(regexp_split_to_array(f0."us", ',')))
with JOIN "public"."oban_jobs" AS o1 ON TRUE in particular seeming suspicious.
It is returning a huge number of rows:
1 Like
Discussed in Slack, turns out it’s related to our usage of DynamicPartioner.
1 Like
Could you clarify, please?
1 Like
Oban Pro v1.5.1 is out with some bug fixes, including a query fix for this issue.
1 Like
The new enhanced unique functionality is not compatible with partitioned tables (see the warning on Oban.Pro.Engines.Smart — Oban Pro v1.5.1), so that leaves us to rely on a fallback query for uniqueness checks. That fallback query is problematic in that it’s returning up to 500k rows in our use case.
1.5.1 unfortunately did not fix our issue so we’ve rolled back to 1.4 for the time being.
1 Like
There were a few issues to solve to really optimize that query. The resulting query is 500-1000x faster depending on the number of partitions and retained jobs, and should be more dramatic with larger datasets.
That will be in v1.5.2 later this week.