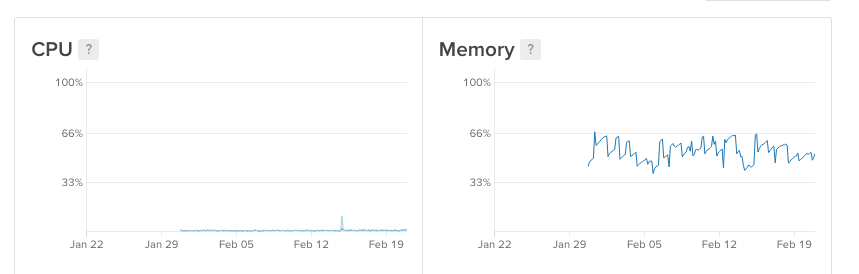
I have deployed my phoenix server to digitalocean and it crashed three times in the last month without having any real traffic. The only traffic is coming from me (testing the website) and the dummy bots trying out different urls which do not exist (GET /phpMyAdmin/scripts/setup.php and so on…).
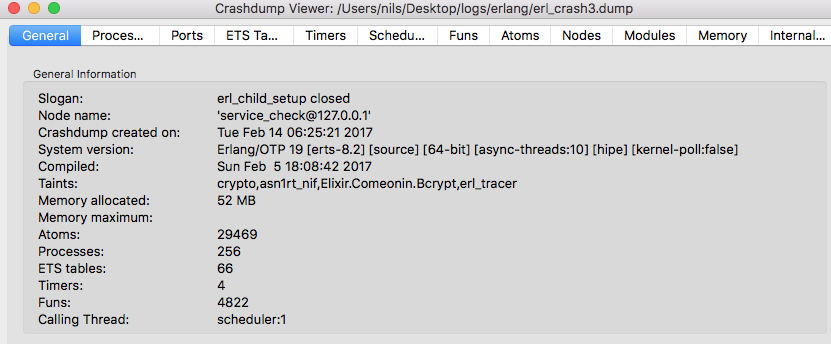
From the erl_crash.dump the error says:
“Slogan: erl_child_setup closed”
The only thing I could find on google was this thread: [erlang-questions] Need help with the error dump - erl_child_setup closed
And it says that a crash like this was fixed in erlang 19.1, since I am using erlang 19.2 thats not the bug I am facing.
You can find the full crash dump here: Dropbox - Error - Simplify your life
I wasn’t sure where to post this (phoenix, plug, cowboy, erlang github) since I cannot say for sure where this error happens, so I am trying it here first.
Some more information on my setup:
erlang: 19.2
elixir: 1.4.1
Deployment: Building a release with edeliver and distillery locally in a docker container running ubuntu:16.04 (same ubuntu as on digitalocean).
The following packages are used, extracted from mix.lock:
> base64url: 0.0.1
bunt: 0.2.0
canada: 1.0.1
canary: 1.1.0
comeonin: 3.0.1
connection: 1.0.4
cowboy: 1.1.2
cowlib: 1.0.2
credo: 0.6.1
db_connection: 1.1.0
decimal: 1.3.1
dialyxir: 0.4.4
distillery: 1.1.2
ecto: 2.1.1
edeliver: 1.4.2
elixir_make: 0.4.0
fs: 0.9.2
gettext: 0.13.1
guardian: 0.14.2
jose: 1.8.0
logger_file_backend: 0.0.9
mime: 1.0.1
phoenix: 1.2.1
phoenix_ecto: 3.2.1
phoenix_html: 2.9.3
phoenix_live_reload: 1.0.8
phoenix_pubsub: 1.0.1
plug: 1.3.0
poison: 2.2.0
poolboy: 1.5.1
postgrex: 0.13.0
ranch: 1.3.2
scrivener: 2.2.1
scrivener_ecto: 1.1.3
uuid: 1.1.6
So its just a phoenix web project, nothing special going on and not a lot of traffic. I don’t now where to look anymore, some thinks I will try:
- Build release on digitalocean server and not in docker container
- start server without a release and directly from sourcecode
It is hard to test any changes since the server will sometimes run for days without a problem and then crashes at six in the morning… This time the crashed happened within 12 hours since the last deployment.
Is anybody else facing something like that or has any ideas what I should try?