Afaik this is the error when the pid requesting a query result exits before the result of the query was delivered. E.g. if your http request handling process dies because it hit its max execution time, but the query is still queued / the results not yet returned.
5 Likes
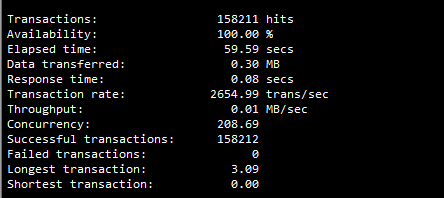
I installed postgresql v11.5 on a server with 16cores & 16GB of RAM. I configured siege with a concurrency of 1000. The phoenix app had other modules but I tested only the module that inserts record into the database.
 .
.
I used default phoenix/os configuration with the exception of the file descriptors.
I check the log file and there was no error, the db server wasn’t that busy as most of the processes were idle.
A few observations and will be glad if I can be educated on it.
-
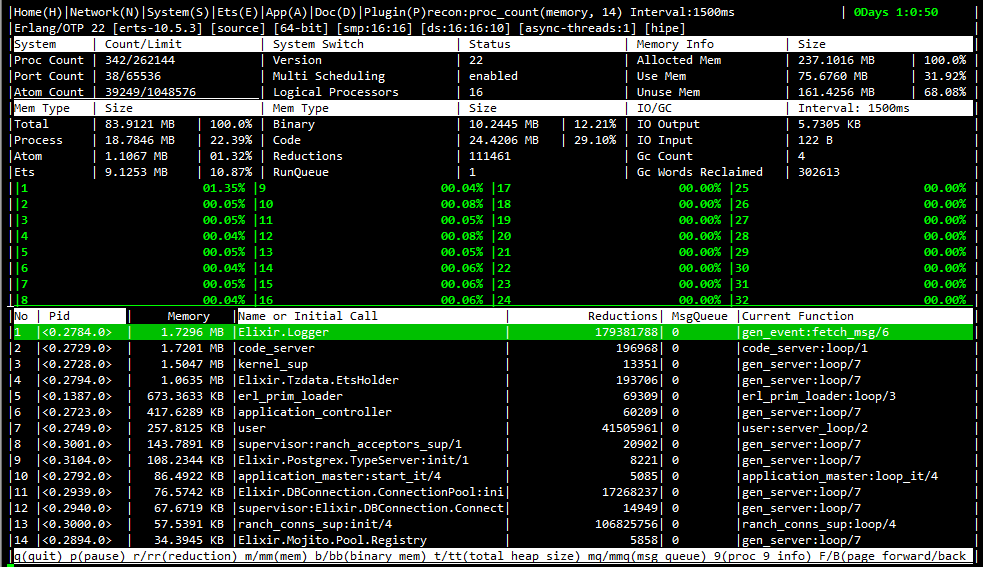
Allocated Memory within the VM is different from what is seen at the OS level.
-
From the observer_cli, what is the essence of the numbers 1 to 32.
3.An general advise on deploying application to production.
Thanks a lot.
A system allocates in block sizes, generally 4kb at a time, a program doesn’t have to allocate in block sizes (though the BEAM mostly does). In addition, memory that is reclaimed from processes on the BEAM aren’t immediately returned to the OS until it seems they won’t be used again soon (allocation from the kernel is slow, so minimize it).
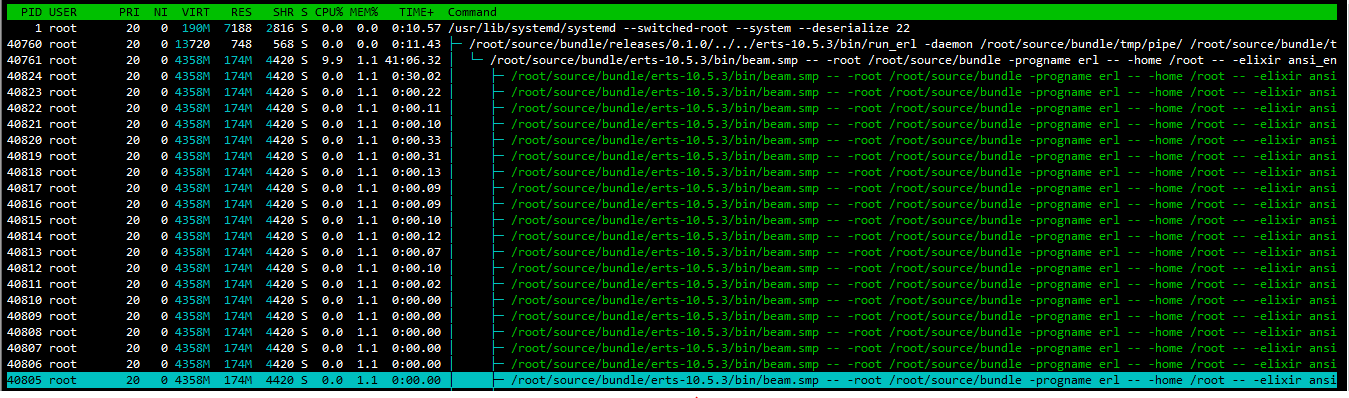
Does that system happen to have 32 cores/hyper-threads (can’t see it in the htop screenshot, looks like it was cut off)?
To expand on this, you should send all Ecto telemetry values to a statsd server so you can see what effects a different pool size has. This is easily done with telemetry_metrics, e.g.:
Telemetry.Metrics.summary("#{repo_name}.query.queue_time_ms",
event_name: "#{repo_name}.query",
measurement: fn x -> Map.get(x, :queue_time, 0) end,
unit: {:native, :millisecond}
)
You can set up InfluxDB and make it ingest statsd numbers in 10 minutes if you use Docker.
Also, depending on your setup, you may need to take other things into account such as roundtrip-time to the database.
2 Likes
I checked with lscpu - 1 socket, 16cores and each core is running a single thread.
What’s the full and complete output of elixir --version?
Erlang/OTP 22 [erts-10.5.3] [source] [64-bit] [smp:16:16] [ds:16:16:10] [async-threads:1] [hipe]
%{
build: “1.9.2 (compiled with Erlang/OTP 22)”,
date: “2019-11-02T13:05:46Z”,
otp_release: “22”,
revision: “96c9500”,
version: “1.9.2”
}
@NobbZ - thanks, I’ve edited my post with the info.
1 Like
He was asking for the complete output, the header line telling about the current Erlang environment is probably what he wanted to see, as it contains informations about the active schedulers of the beam and other important details about the runtime.
2 Likes
Yep, thanks @Nobbz. So @kodepett, your runtime has 16 processing schedulers running and 16 nif dirty schedulers running, which makes 32, so I’m definitely leaning to that being what those are then. I’m not certain of course so if anyone else could clarify… 
There is also 1 async thread though, that does waiting instead of processing so I could see it not being counted.
1 Like
Correct!
Just to be sure, are you running Phoenix with MIX_ENV=prod?
They were referring to this Mint and this Mojito, both written in Elixir.
1 Like
Just to be sure, are you running Phoenix with
MIX_ENV=prod?
I’m using a release generated with mix release and not distillery. My VM sits on top of hypervisor.
I will like to know if wrapping a db call(Repo) or http request(Mojito) in a try and catch is ok, since there’s a possibility of these calls throwing an exception.
Secondly - is it ok to have a lot of pattern matching within a module, will that affect performance since the patterns will have to be evaluated in turns.
The question still stands though: have you set MIX_ENV=prod when you assembled the release?
While using try/catch is OK, why do you need to use try/catch? If those actions fail it is generally not a problem, the Elixir process may terminate, but you will continue serving requests.
That’s totally fine too.
1 Like
The question still stands though: have you set MIX_ENV=prod when you assembled the release?
MIX_ENV=prod mix compile and MIX_ENV=prod mix release were the commands used to generate the release.
While using try/catch is OK, why do you need to use try/catch? If those actions fail it is generally not a problem, the Elixir process may terminate, but you will continue serving requests.
This is a web request, if the process fails to due an exception, the client will not receive a response. Wrapping db calls or http request in a try/catch block will allow you to respond the client in the event of an exception.
On the beam you’ll most often use additional processes to have things fail independently instead of trying to catch problems with try/catch. Your webrequest can then observe what’s happening in the other process and react accordingly.
1 Like
I’m not sure I follow, the web request is handled by cowboy/ranch, hence the process which is spawn AFAIK is out of my control. Is there a way that I can have access to that process or any event I can subscribe to etc.
The webrequest is spawned by the webserver, but that doesn’t mean you cannot spawn additional processes to do work for you. The simplest way to do that is by using Task or Task.Supervisor. There’s no need to do all the work in the webrequest process, especially for things, which are prone to fail at times.
1 Like
I’ve been trying to wrap my head around Task.Supervisor. I’ve worked with Task within a GenServer with trap_exit flag set - handling :EXIT and :DOWN within handle_info callback. I’ve a few questions after perusing the Task.Supervisor docs.
I’ve two scenarios - I make an http call to a third party api - I need the response/failure to proceed - wrapping it in a task & waiting on the next line will not be that efficient if I’m using async and await since subsequent flow depends on the return of this call - kindly advise.
In the second scenario, it’s a db call, I don’t need to report error to user but will have to log if an error occurs while saving to database. I think I can hand this off to the Task.Supervisor, per the docs, the Task.Supervisor is started for a Supervisor. I’m under the impression that I can use or extend it like a GenServer or DynamicSupervisor and probably have a handle_info call to hand failed task - kindly advise.
Thanks.
It’s still kinda synchronous code if you start the task and immediately await it. Processes on the beam are cheap, so it shouldn’t really hurt “efficiency”. But you get the resilience that the web request will not crash no matter what happens to the api call and the code clearly communicates that a possible error needs to be handled. If you need that resilience depends on how stable you expect the code to be.
I’ve been perusing resources on learn in my bid to use the Task or Task.Supervisor as an alternative(better) to the try/catch. Most of the examples wraps the Task.Supervisor call in a GenServer and report the status to the GenServer; is this the ideal usage?
-
How will my use case be in this context - send the db call to task, monitor the task and log if the db call fails.
-
How do I go about using the task for the http call and responding back to the caller and being able to handle a crash as well.
Any resource that I can take a look at.





















