Currently, i was working on a project in which the backend services is in microservice + each service can have multiple instance. However, i from time to time deals with concurrency issue in case of two API request which mutate same data happen at very similar time. There’s many way to “deal” with such concurrency issue, like optimistic locking (ecto implement this BTW), random delay on processing request, etc. But i am currently researching on possibility of using Request sharding based on Domain Aggregate.
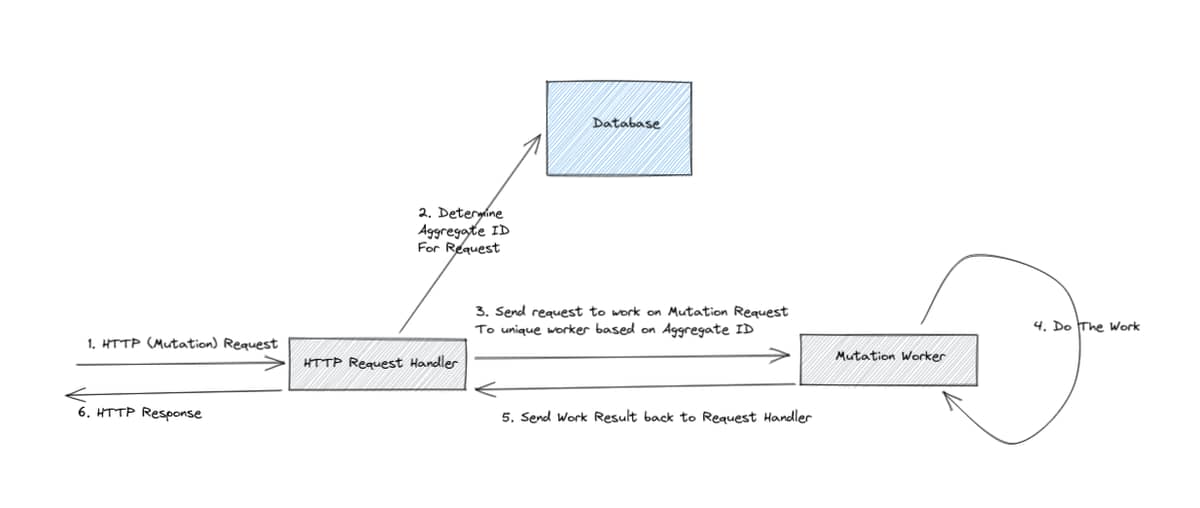
The system work like this: When there is a HTTP (Mutation) Request, it will be handled by HTTP Handler process which would determine the aggregate ID for HTTP request (request can be already have the ID, or it may need to do additional query to DB for the ID). then HTTP handler would send message to unique worker process (based on Aggregate ID) which would process all request for work for a particular aggregate ID serially. After work is finished, unique worker send the result back to HTTP handler which would forward it as HTTP Response.
was anyone have ever work on similar system? was it performant enough?
I am not sure how to implement step “3. Send request to work on Mutation Request
To unique worker based on Aggregate ID” and “5. Send Work Result back to Request Handler” in a multiple microservice instance environment, could you give pointer?
I worked on a system that would send requests to a process based on a shard ID. The process was made unique using :global process (I know about netsplits). That system worked really well for us and we never hit any issues with that aspect of it. That system was doing external API requests, not database queries, so I didn’t have the ability to do anything fancy with the database. However, it was an optimization solution. It would be correct even if the cluster netsplit and 2 processes did the same work.
If it was possible, I would certainly try to solve this via the database and not have any fanciness on the Elixir application side. The reason is that you have a correctness problem here. If you mutate incorrectly, then your data is incorrect. This makes the problem of netsplits or general blips a much bigger concern.
My immediate thought process follows this order:
Atomic updates are preferable. No magic required anywhere
SELECT FOR UPDATE a single record to lock it during the write. Always perform modifications after the record is loaded to 100% guarantee you have the latest version
Advisory lock around a group of operations to ensure they don’t enter simultaneously
SGP (single global process) based on aggregate ID to perform the updates
The database operations are preferred for the reasons I mentioned above. If you go the SGP route, then it’s likely still okay performance-wise, because there’s a global process per domain aggregate ID.
This is a fairly deep question because it highly depends on your microservice architecture. I only ever did this within the cluster of a single application and would never have tried it cross microservice. There’s just too much that can go wrong. Likely, you’ll need to use whatever request/response API you prefer between the microservices (like HTTP, gRPC, etc).
Unless you put aggressive timeouts, the API calls can take a lot of time. It seems to me that using database locks in this case would drain the connection pool pretty quickly and would not scale well. Is that the reason you went with process-based serialization?
Thank you very much for sharing your experience @sb8244 !, it’s awesome for you to share insight in such detailed manner!
I worked on a system that would send requests to a process based on a shard ID. The process was made unique using :global process (I know about netsplits). That system worked really well for us and we never hit any issues with that aspect of it. That system was doing external API requests, not database queries, so I didn’t have the ability to do anything fancy with the database. However, it was an optimization solution. It would be correct even if the cluster netsplit and 2 processes did the same work.
Ah, i doesn’t consider possibility of netsplit, but considering that definitely have implication to the correctness of the system. I assume you are doing caching/batching on external API call, that’s why you try to group it into a single unique worker? Actually the inspiration of sharding request across domain aggregate ID come from one of Dave Farley’s youtube video in which he describe implementing High Performance Financial Exchange in such sharding manner. It’s really performant because using sharding doesn’t rely on exclusive lock. And i thought if i do this on application level i would get concurrency correctness while still having good concurrent performance.
If it was possible, I would certainly try to solve this via the database and not have any fanciness on the Elixir application side.
Yes, point well taken, using conventional technology would be more reliable also. I don’t realize there’s such thing as Advisory lock on SQL, using Advisory lock based on Aggregate ID would also be doable. (BTW, we get this concurrency problem because we kind of misunderstood that transaction guarantee in postgresql).
This is a fairly deep question because it highly depends on your microservice architecture. I only ever did this within the cluster of a single application
Sorry, “microservice” that i was involved in is not really “micro” sized services, more like “macro” sized services. And actually i does consider the problem in context a single macroservice with multiple instance of it.
The big thing here is optimization vs correctness. Even if every node became split, the application would still be correct in the case I’m referencing.
In this case, you’ll probably find the blog post above useful. I’d still point you to the database approach if it’s possible, but maybe it’s okay you have a bit of fun sometimes as long as you know the downsides you might experience.