I have two tables, “questions” and “test_questions”:
schema "questions" do
has_one :test_question, TestQuestion
field :question_type, :string, null: false
field :body, :string, null: false
end
schema "test_questions" do
belongs_to :test, Test
belongs_to :question, Question
field :position, :integer, null: false # question no. in the test
end
Is there any efficient way to retrieve all questions that are not test questions? I tried something like the following, according to a StackOverflow answer (https://stackoverflow.com/a/19364694):
Repo.all(from q in Question,
where: q.question_type == "long question"
and not ^Repo.exists?(from tq in TestQuestion, where: tq.question_id == q.id),
limit: 20
)
But I got the compilation error that q is an unbounded variable. I also tried to change q.id to ^q.id, but the compiler complained that q/0 is an undefined function.
Edit. It seems that the following query works:
Repo.all(from q in Question,
left_join: tq in assoc(q, :test_question),
where: q.question_type == "long"
and is_nil(tq.id),
limit: 20
)
but I’m not sure if this is really a correct or good way to solve the problem.
This can be accomplished by a RIGHT JOIN if I’m not mistaken.
1 Like
The issue with your implementation is that it will execute the subquery for every question. This quickly gets very slow when you start scaling.
Currently on mobile so its hard to write code, but your best bet is probably to do an outer join from question to test_question based on question_id. After that outer join you can use a WHERE to check which rows have tq.id IS NULL.
Hopefully thats clear 
Edit: Sfusato’s version is definitely the way to go
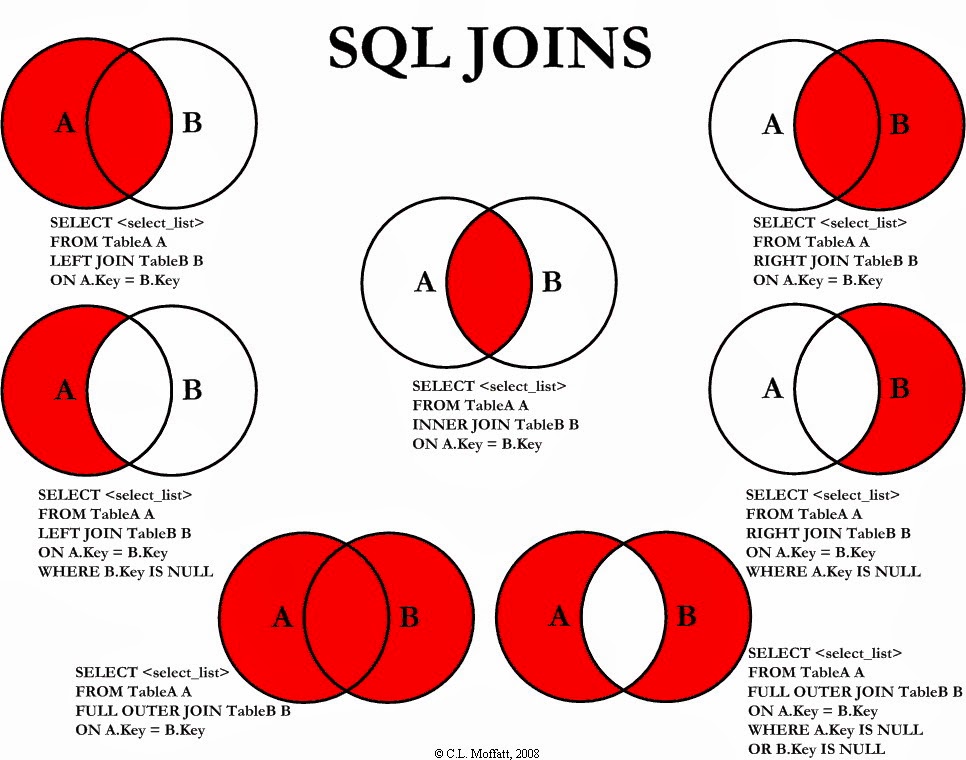
Thanks, but I don’t understand what A.Key and B.Key should be. The “test_questions” table essentially contains pointers to the test and the question. Its schema has only three entries:
schema "test_questions" do
belongs_to :test, Test
belongs_to :question, Question
field :position, :integer, null: false # question no. in the test, not question ID
end
The only relevant field that can be used as the key is question_id, which is never null.
The “test_questions” table references the “questions” table, but not vice versa. The “test_questions” table essentially contains pointers to tests and questions. At present, I can retrieve all test questions first, and perform another query to obtain all questions whose IDs do not appear on the test questions list:
ids = Repo.all(from tq in TestQuestion, select: tq.question_id)
questions = Repo.all(from q in Question,
where: q.question_type == "long question"
and q.id not in ^ids,
limit: 20
)
but this is too inefficient.
A is your test_questions table
B is questions table
When you right join the tables, if there’s a question that doesn’t appear in test_questions, then test_questions.question_id in the “computed join table” will be null. This is the whole idea.
Try this:
from tq in TestQuestion,
right_join: q in Question,
on: tq.question_id == q.id,
where: is_nil(tq.question_id)
ps: w3schools has some examples and you can also play with the queries.
4 Likes